
LINE DEVELOPER DAY 2021의 Day 2 Server-Side 세션들을 정리해 보았습니다. 혹여 잘못 이해한 부분이 있거나, 오탈자가 있는 경우엔 댓글로 알려주시면 감사하겠습니다.
| 세션 | 발표자 |
|---|---|
| 마케팅 데이터 플랫폼 ‘Business Manager’ 개발기 | Toshiyuki Nakamura |
| 8년간 유지해 온 Perl 프로덕트를 Kotlin으로 바꾼 이야기 | Kohei Ohara |
| Redis Pub/Sub을 사용해 대규모 사용자에게 고속으로 설정 정보를 배포한 사례 | Kazuya Horiuchi |
| 대규모 음악 데이터 검색 기능을 위한 Elasticsearch 구성 및 속도 개선 방법 | Taku Tada |
마케팅 데이터 플랫폼 ‘Business Manager’ 개발기 - Toshiyuki Nakamura

안녕하십니까. LINE에서 비즈니스 매니저를 개발하고 있는 Nakamura Toshiyuki라고 합니다.
본 세션에서는 차세대 마케팅 비즈니스 플랫폼 개발이라는 주제로 발표하겠습니다.
Agenda

본 세션의 Agenda는 다음과 같습니다.
-
비즈니스 매니저란 무엇인가
-
비즈니스 매니저가 구축되기 전 시스템
-
비즈니스 매니저의 시스템 아키텍처
-
비즈니스 매니저를 개발하는 데 과제가 된 기능과 접근 방식
Business Manager
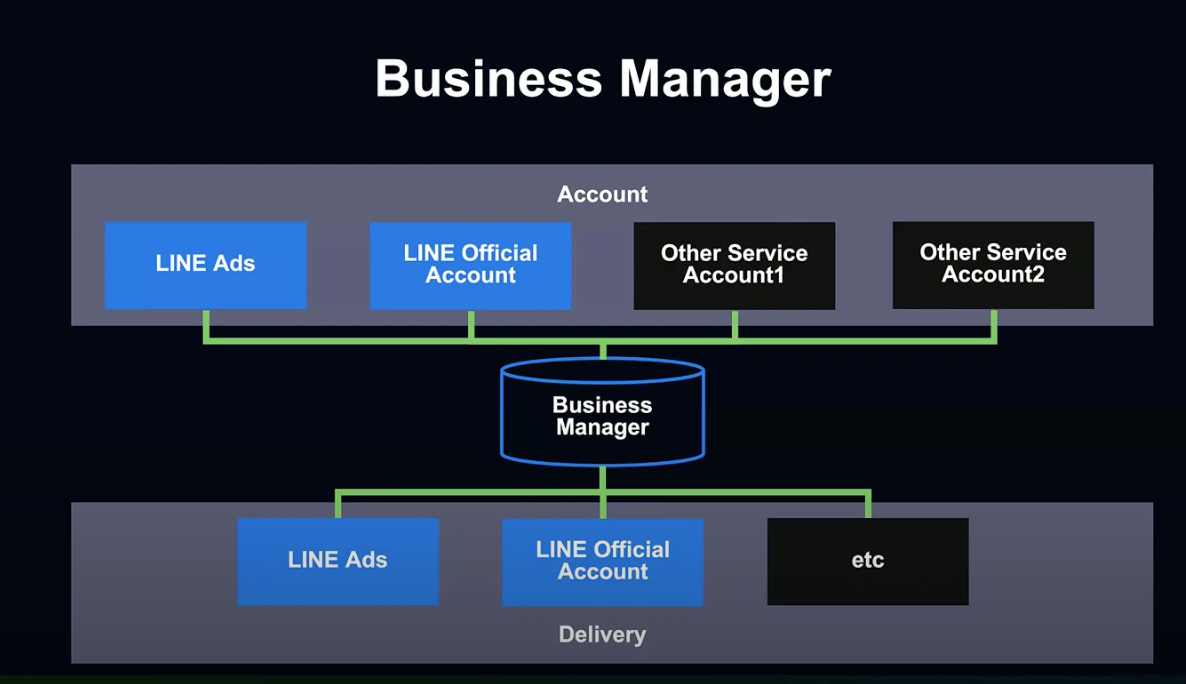
먼저 비즈니스 매니저란 무엇인지 알아보겠습니다.
비즈니스 매니저란 광고주인 기업들이 LINE의 각종 마케팅 Product를 통해, 다양한 데이터를 효과적으로 활용할 수 있도록 하는 시스템입니다.
LINE 광고, 공식 계정과 같은 각종 Product 데이터를 통합해, 광고 송출 등의 서비스에 효과적으로 활용하고 있습니다.

LINE이라고 하면 메신저 앱의 소비자용 서비스라는 이미지가 강하지만, 다양한 비즈니스용 Product도 제공하고 있습니다.
비즈니스 매니저에 대한 이해를 돕기 위해 LINE의 B2B Product를 소개하겠습니다.
LINE B2B Product에는 광고, 공식 계정, 포인트 등이 있는데, 이 중에서 LINE 공식 계정과 LINE 광고에 대해서 알아보겠습니다.

길을 걷다 가게에서 한 번쯤은 LINE 공식 계정 친구 모집 글귀를 본 적이 있으실 것입니다.
LINE 공식 계정은 대기업에서 소규모 가게까지 유저와 소통할 수 있게 도와주는 서비스입니다.

LINE 광고는 LINE 유저를 대상으로 LINE 앱을 비롯한 다양한 미디어를 통해 광고를 송출하기 위한 플랫폼입니다.
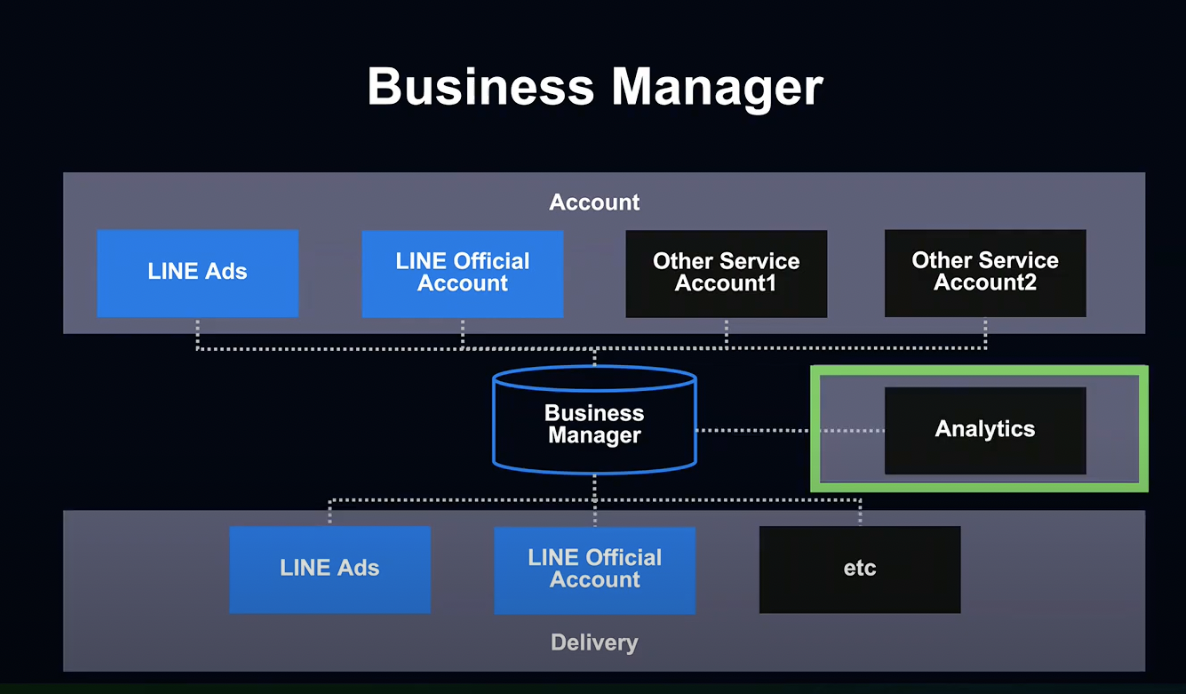
다시 비즈니스 매니저로 돌아가 보겠습니다.
비즈니스 매니저에서는 LINE 광고와 공식 계정 등 서비스 계정에 접속하여, 각각의 계정이 보유하고 있는 데이터를 통합 관리합니다.
접속한 계정의 데이터를 이용해 광고를 송출하고, 메세지를 전송하는 등 다양한 활용이 가능합니다.
릴리즈 초기에는 두 가지 서비스만 지원했지만, 지속적으로 확대해 나갈 예정입니다.
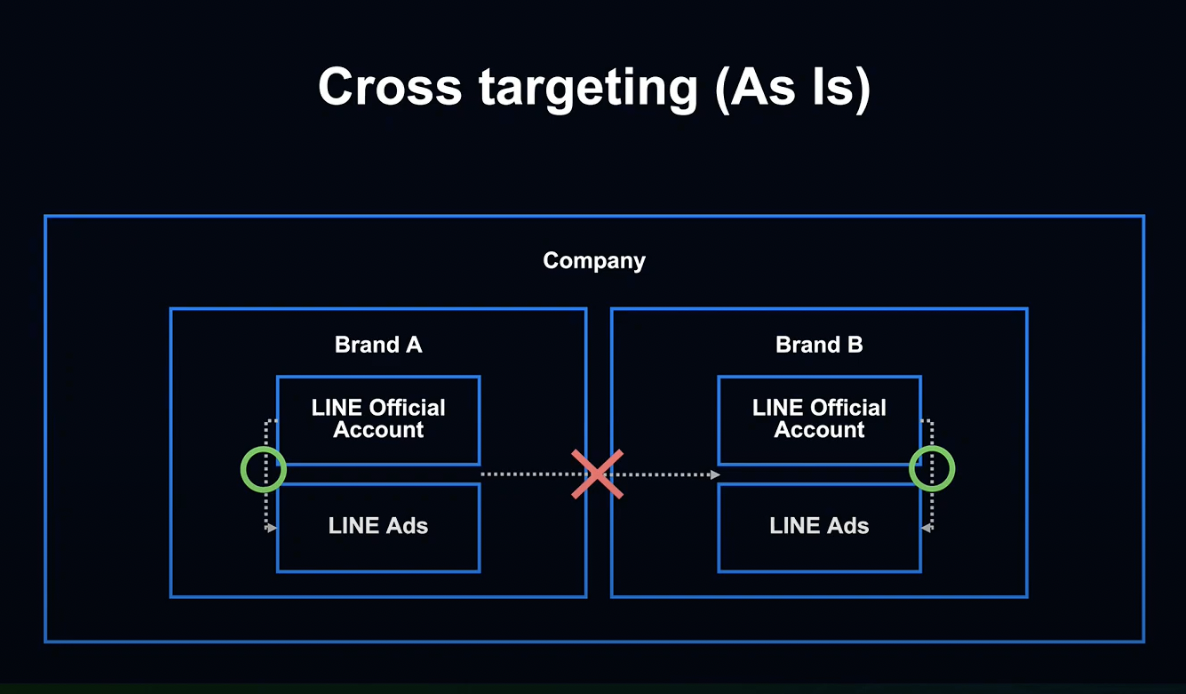
그렇다면 비즈니스 매니저가 왜 차세대 시스템일까요?
기존에는 Cross Targeting이 데이터 활용 시스템으로 사용되고 있었습니다.
그러나 Cross Targeting에서는 시스템, 규정 상의 제약으로 한 기업이 운영하는 여러 브랜드 간 직접적인 데이터 공유가 불가능했습니다.
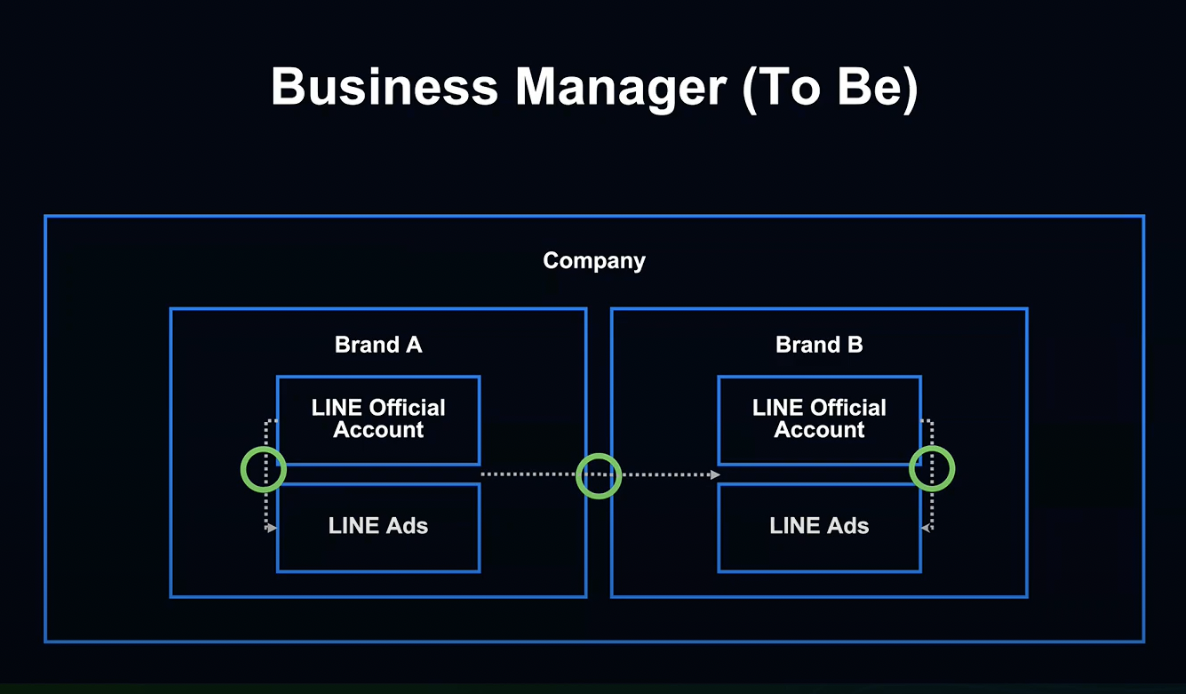
비즈니스 매니저는 같은 기업 브랜드 간의 데이터 공유를 가능하게 만드는 시스템입니다.
이를 통해 LINE 광고 데이터를 다른 브랜드의 광고 계정으로 공유 및 활용이 가능해졌습니다.
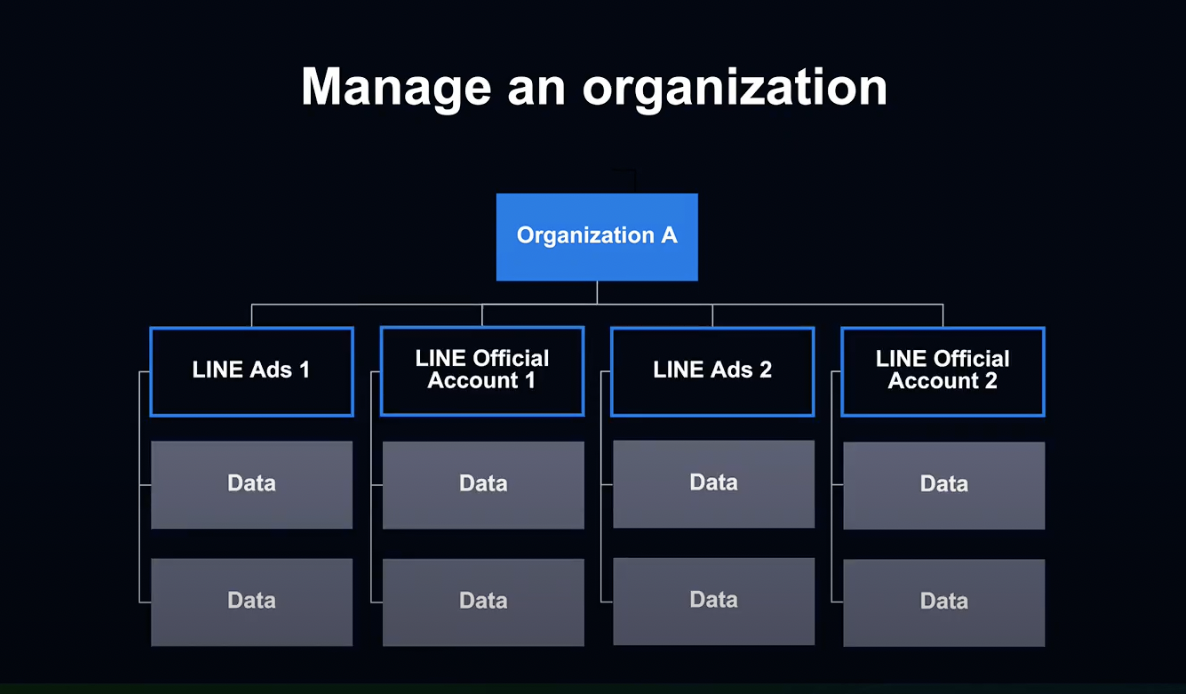
비즈니스 매니저에서는 관리 화면에서 Organization이라고 부르는 그룹을 광고주 기업 단위로 생성할 수 있습니다.
Organization 아래에 LINE 광고와 공식 계정을 둠으로서 해당 계정이 보유한 데이터를 계정 간에 공유할 수 있습니다.
릴리즈 초기에 계정 간 이용 가능했던 데이터는 주로 2가지였습니다.
-
LINE Tag와 JS Snippet을 웹사이트에 설치해 전환율 계측
-
어떤 유저에게 어떤 광고를 송출할 것인가를 나타내는 사용자 데이터 집계
현재 비즈니스 매니저에서 접속 가능한 계정 및 데이터 타입은 2가지 뿐이지만, 앞으로 지속적으로 확대해 나갈 계획입니다.
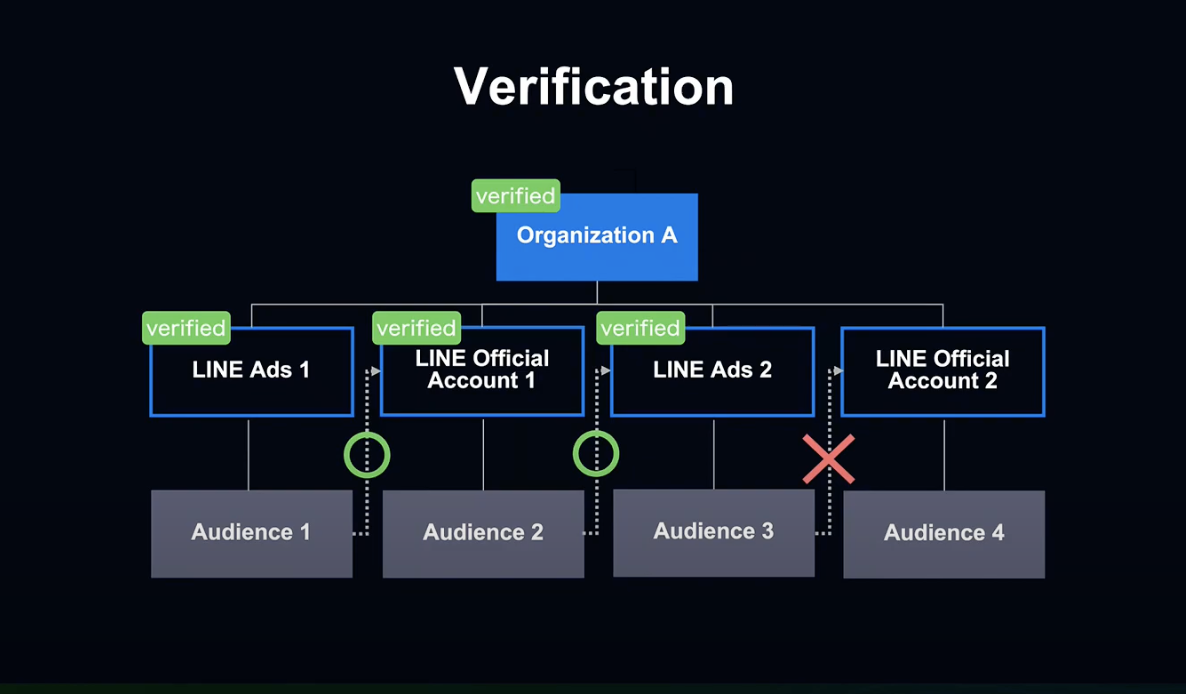
기업들이 안심하고 비즈니스 매니저를 이용할 수 있도록 인증 기능을 갖추었습니다.
사용자는 Orgazination으로 접속이 가능하지만, 그것 만으로는 계정 간 사용자 데이터 공유가 불가능합니다.
LINE의 오퍼레이터가 Orgazination과 해당 계정을 운영하는 기업이 동일한지 내부 툴을 이용해 심사하고, 여기서 승인된 Orgazination과 계정만이 사용자 데이터를 공유할 수 있습니다.

또한 Orgazination 안에서 데이터 공유 권한 설정도 가능합니다.
Orgazination 아래 모든 계정의 모든 데이터 공유와 같은 와일드카드 설정이나, 특정 데이터만을 특정 계정과 공유하는 등의 설정이 가능합니다.
또한 Orgazination에 직접 LINE Tag와 고객 데이터를 작성 및 공유하는 것이 가능합니다.
About the System

비즈니스 매니저에는 여러 서비스 계정과 데이터가 있습니다.
필연적으로 많은 개발 과제가 발생할 수밖에 없는데, 이제부터 과제들을 기술적으로 어떻게 풀어나갔는지에 대해 설명하겠습니다.
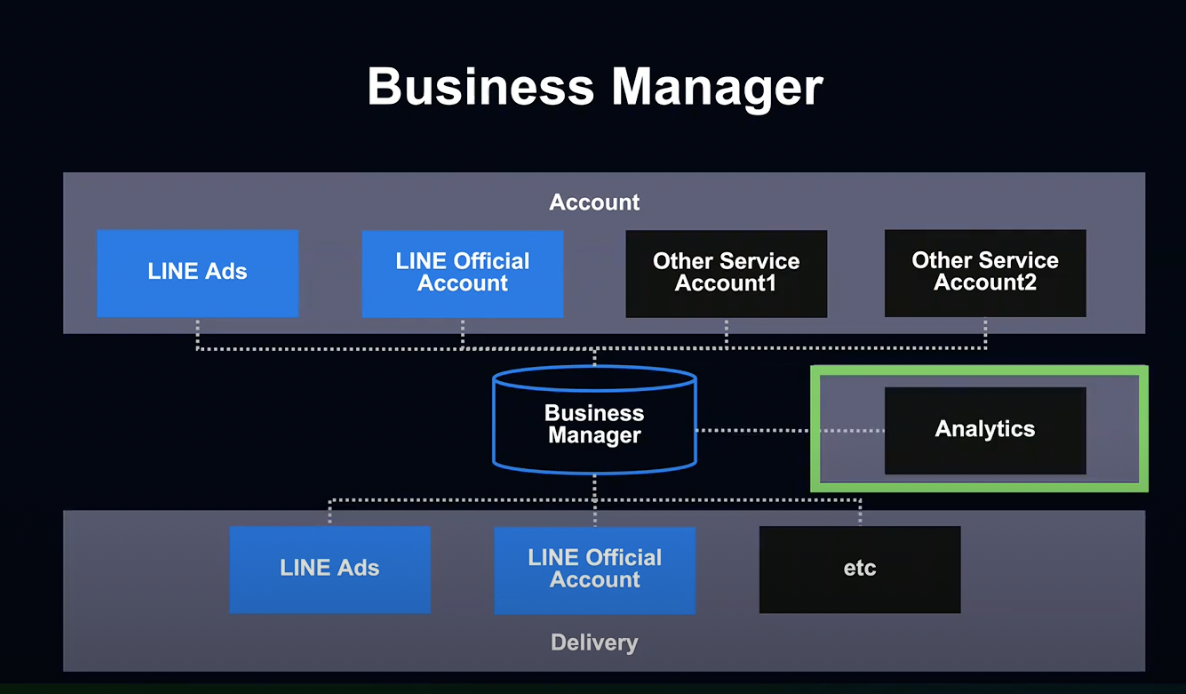
이에 앞서 잠시 앞에서 보여드린 슬라이드 내용을 살펴보겠습니다.
비즈니스 매니저는 비즈니스 매니저만으로 기능을 실현하는 것이 아니라 기존 시스템에 공유 권한 관리를 추가함으로서 가동됩니다.
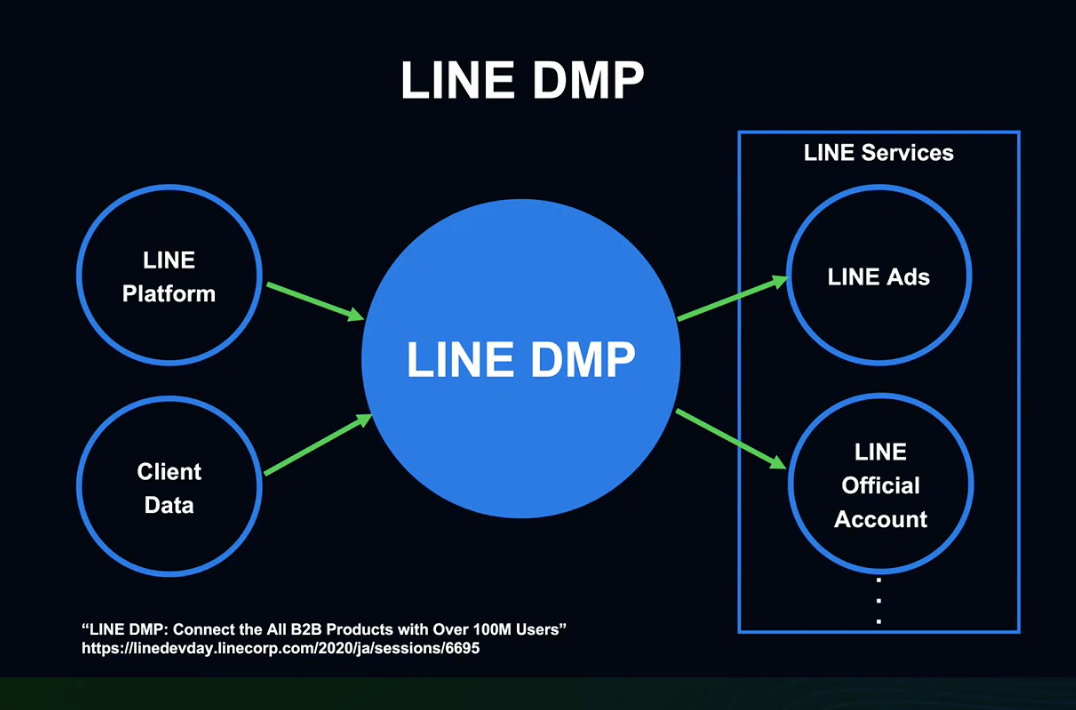
앞서 설명드린 기존 Cross Targeting 시스템을 구현한 것이 LINE DMP입니다.
LINE DMP란 LINE이 내부적으로 사용하고 있는 광고 데이터의 수집/가공/제공을 위한 플랫폼입니다.
LINE 플랫폼에 생성된 데이터와 기업이 관리하는 데이터를 추천 및 가공하여 LINE 광고, 공식 계정 등 B2B 서비스에 제공합니다.
작년 DEVELOPER DAY에서 LINE DMP의 상세 내용을 다루고 있으니 참고하시면 좋을 것 같습니다.
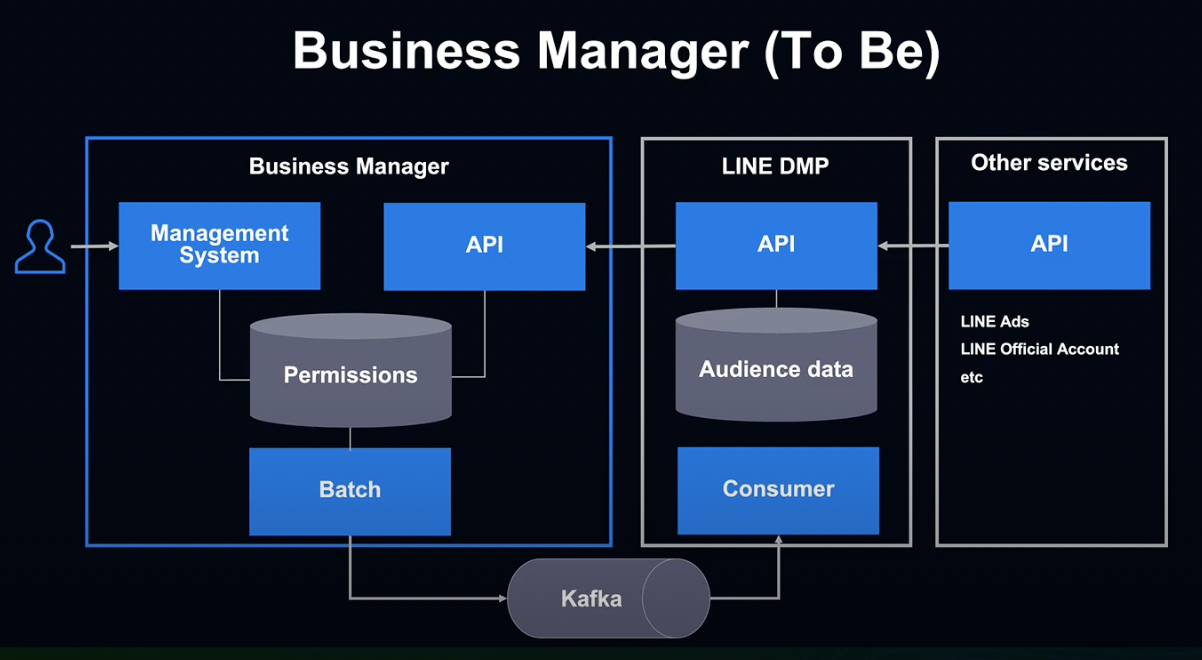
다시 비즈니스 매니저로 돌아가 보겠습니다.
비즈니스 매니저 구축 전에는 DMP에 연계해 사용자 데이터를 제공했습니다.
이 시스템에 비즈니스 매니저의 권한 관리 기능을 추가함으로서 계정 간 데이터 공유를 실현했습니다.
기존 시스템과 비즈니스 매니저의 데이터 연계 방법으로는 크게 2가지가 있습니다.
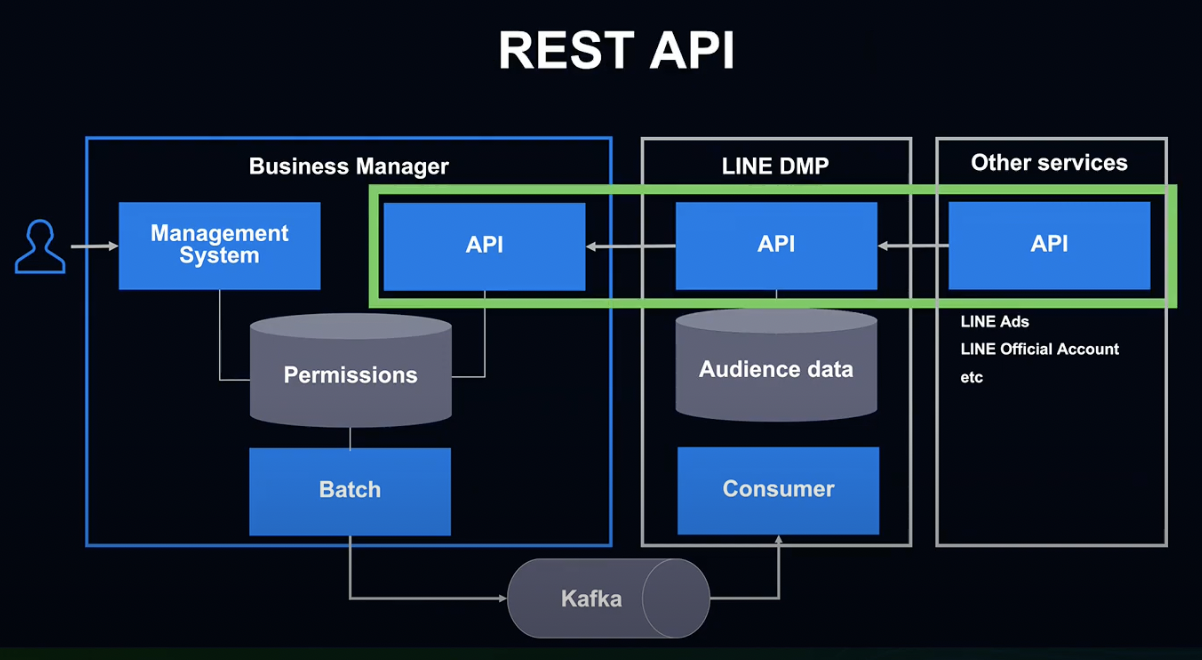
첫 번째는 REST API 방식입니다.
기존에도 LINE 공식 계정이나 광고에서는 DMP 데이터를 활용할 경우 DMP API를 사용하고 있었습니다.
현재는 DMP 내부에서 비즈니스 매니저 API를 호출해 권한을 확인하는 방식을 사용하고 있습니다.
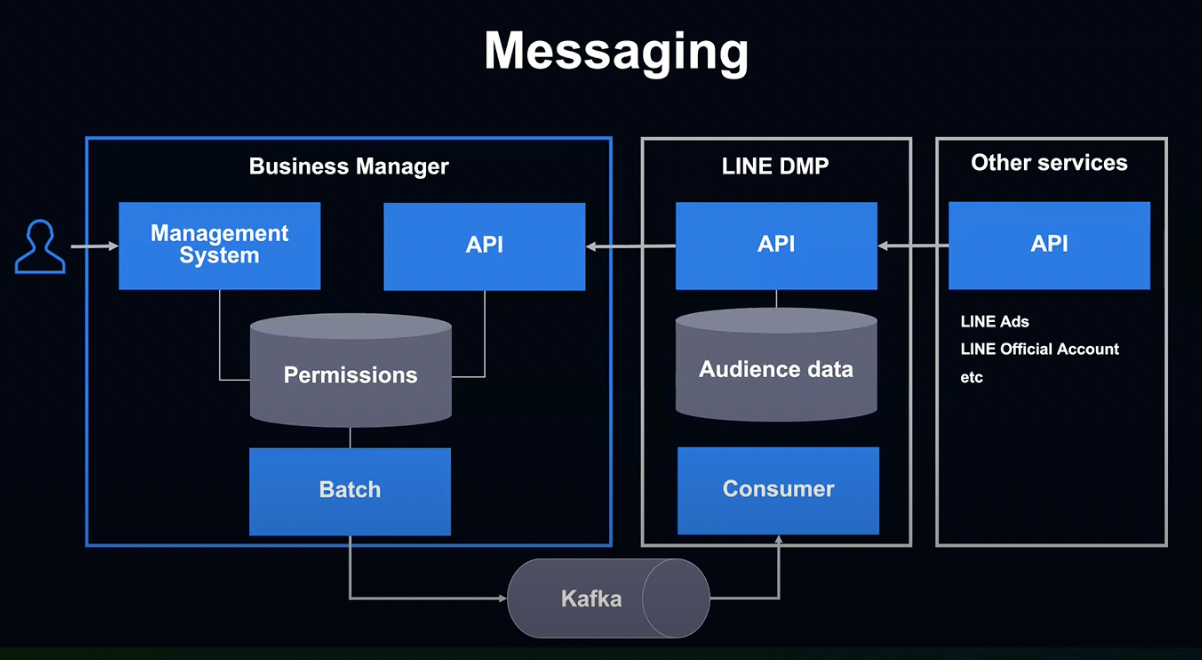
두 번째는 Kafka를 통한 메시징 방식입니다.
비즈니스 매니저의 유저들이 계정 간 공유 권한 설정을 변경하면, MySQL에 내용이 저장되고, Batch가 변경된 내용을 로딩해 Kafka를 통해 DMP에 변경을 전달합니다.
이 부분은 여러가지로 검토해야 할 어려운 과제들이 많았는데, 뒷부분에 자세히 설명하도록 하겠습니다.

지금부터는 비즈니스 매니저를 구성하는 구체적인 기술에 대해 알아보도록 하겠습니다.
프로그래밍 언어로는 Kotlin을, 프레임워크로는 Spring Boot를 사용하고 있습니다. 뒷부분에서도 말씀드리겠지만 Kotlin 기능을 최대한 활용하여 개발하고 있습니다.
미들웨어는 기본 저장소로서 MySQL, 캐시와 락은 Redis, 각 서비스 데이터 동기화를 위해 Kafka를 사용하고 있습니다.
인프라는 사내 클라우드인 Verda를 사용 중입니다.
짧은 초기 개발 기간과 데이터를 취급하는 시스템의 중요성을 고려해 가급적 검증된 기술을 선택했습니다.
Findings from development

비즈니스 매니저 개발 과정에서 발생한 과제와, 그 과제들을 어떻게 극복했는지에 대해 말씀드리겠습니다.
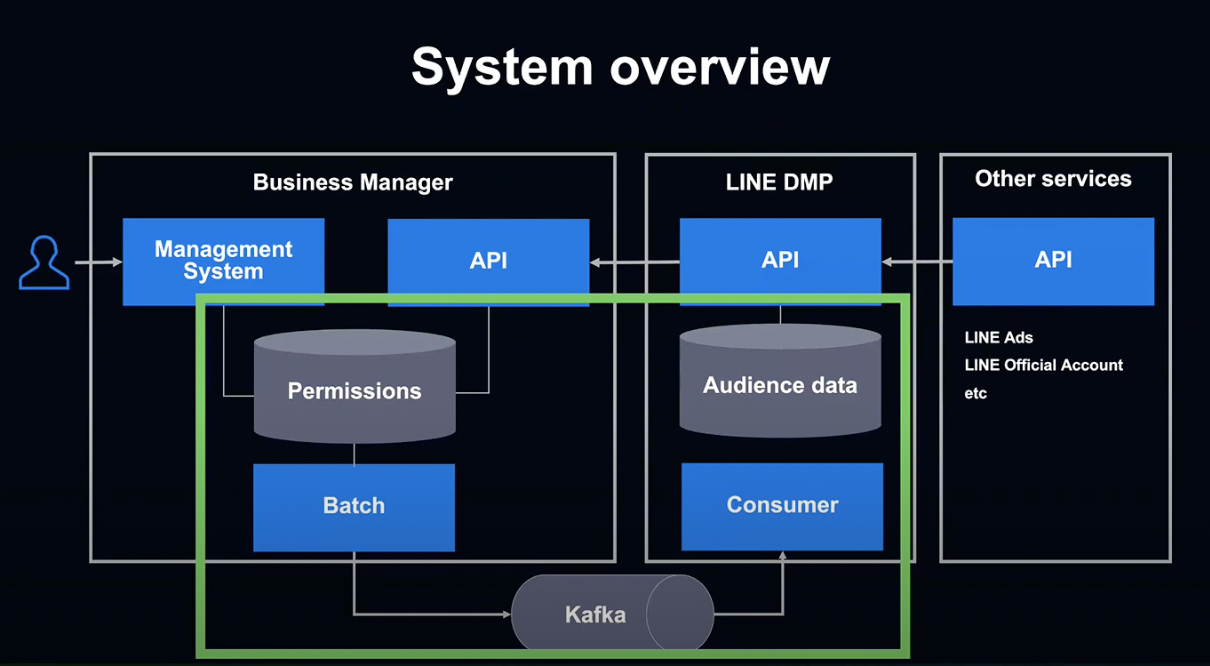
비즈니스 매니저에서는 데이터베이스 권한 설정의 변경을 Kafka를 통해 LINE DMP에 전달하고 있습니다.
이 부분에서 몇 가지 과제가 있었습니다.

비즈니스 매니저에서는 유저가 공유 권한의 설정을 변경할 수 있습니다.
이때 LINE DMP에 확실하게 누락 없이 데이터의 변경을 전달해야 하는데, Database와 Kafka를 하나의 트랜잭션으로 처리해야 했습니다.
문제를 해결하기 위하여 회의한 결과, 3가지의 해결 방안이 도출되었습니다.
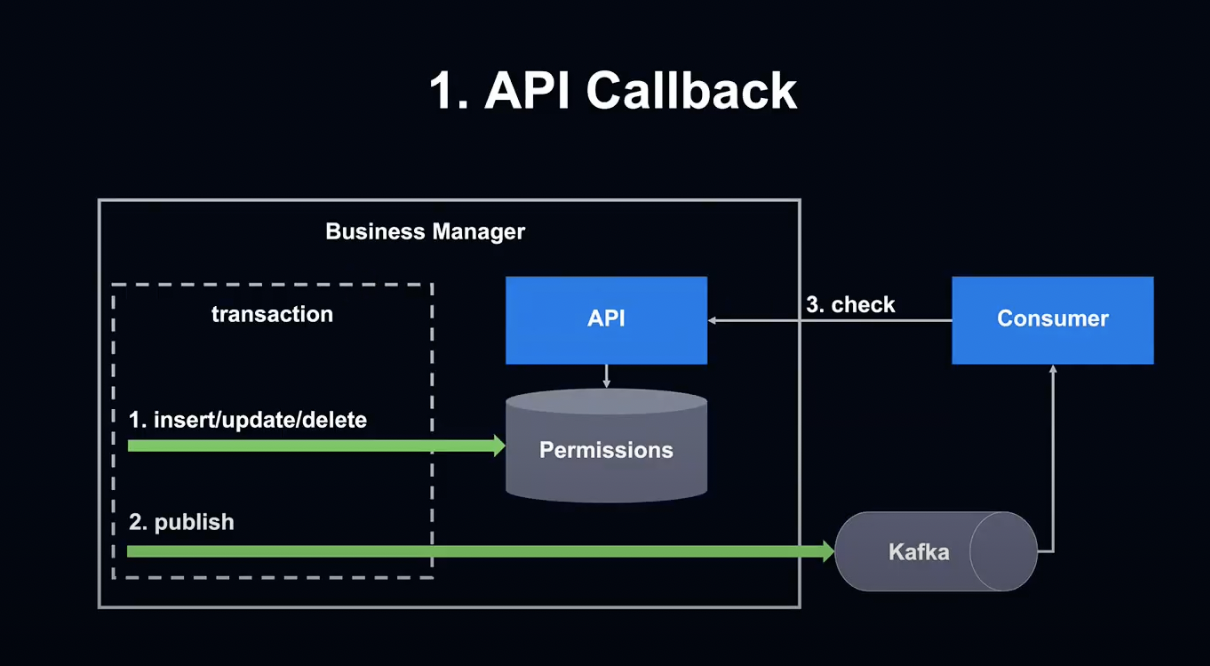
첫 번째 방안은 API Callback입니다.
데이터베이스의 동일 트랜잭션에서 갱신 처리를 완료한 후, 권한이 변경되었다는 메세지를 Publish 합니다.
그 후 Consumer 측에서 API를 호출하여 변경된 내용이 데이터베이스에 반영되었는지 확인하는 방식입니다.
트랜잭션 내에서 Kafka Publish 된 후 Rollback 처리되어 데이터베이스에 데이터가 반영되지 않는 경우가 있기 때문에, API를 호출하여 확인해야 합니다.

구현이 간단하고 다른 팀에서도 자주 사용되는 검증된 방법이라는 장점이 있지만, Callback API의 성능 우려가 있었기 때문에 이 방법은 포기했습니다.
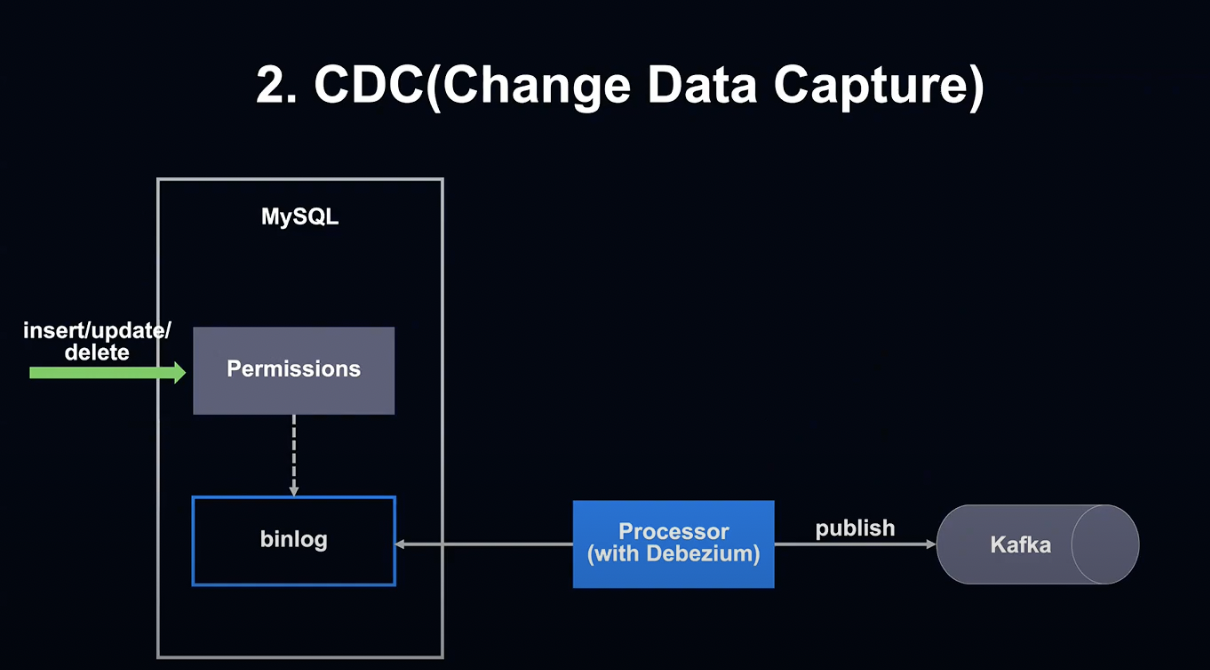
두 번째 방법은 CDC, 즉 Change Date Capture를 사용하는 방법입니다.
이미 저희 부서에서는 MySQL Binlog에서 Debezium을 사용해 변경 내용을 Kafka에게 전달한 경험이 있었기에 검증된 방법이었습니다.

장점으로는 실시간에 가까운 처리가 가능하고, 다른 팀에서 이미 검증된 방법이라는 점이 있습니다.
하지만 관리 테이블의 구성이 복잡하고, Consumer의 설계가 어렵고 별도의 작업이 많이 필요할뿐더러 다른 팀에서 사용하고 있을 경우 순서가 보장되지 않아 결국에는 결과를 확인하기 위한 API Callback이 필요했기 때문에 결국 반려되었습니다.
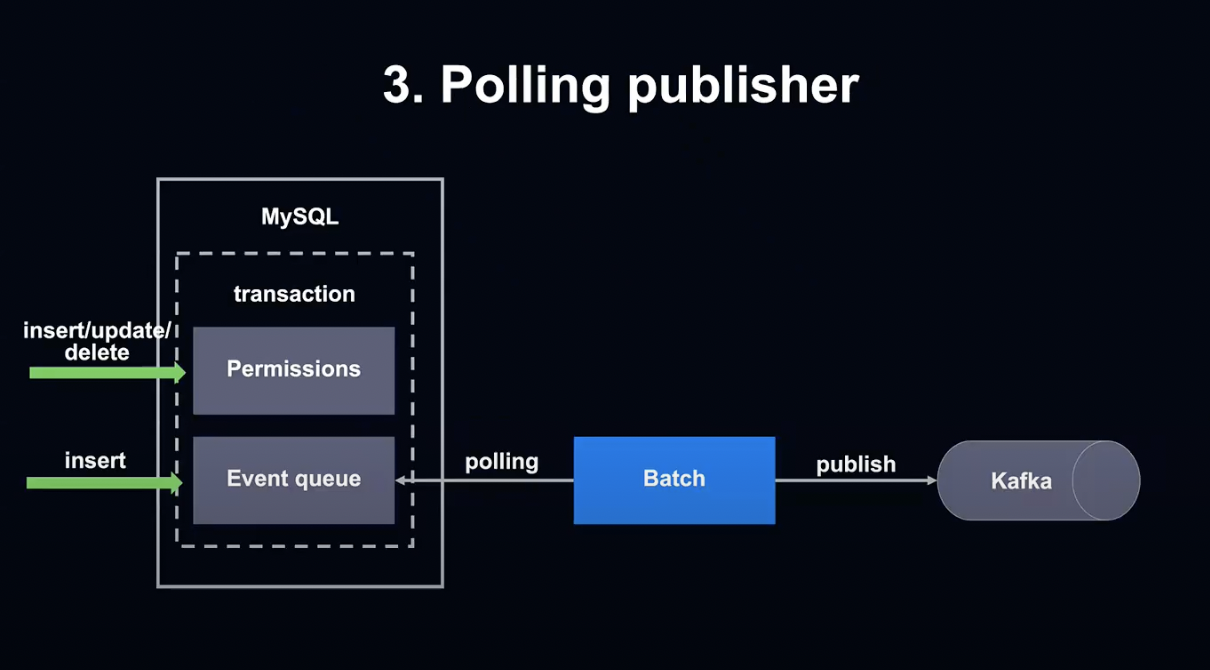
세 번째 방안은 공유 권한의 설정이 변경될 때 설정 테이블만이 아닌 Event Queue에 해당하는 테이블도 똑같이 트랜잭션 이벤트를 기록하는 방식입니다.
그 후 Event Queue에 Table Batch를 Polling해 권한 변경 시 Kafka에 전달합니다.

이 방식은 구현이 심플하고, 순서가 보장된다는 장점이 있습니다.
단점으로는 Polling 간격에 따라 실시간성이 상실될 수 있고, 변경이 잦은 경우 증축이 어렵다는 점이 있습니다.
그렇지만 비즈니스 매니저의 경우 실시간성이 꼭 필요하지 않고, 권한 설정을 자주 변경해야 할 만한 Use Case가 없다고 판단해 최종적으로 이 방법을 선택하게 되었습니다.
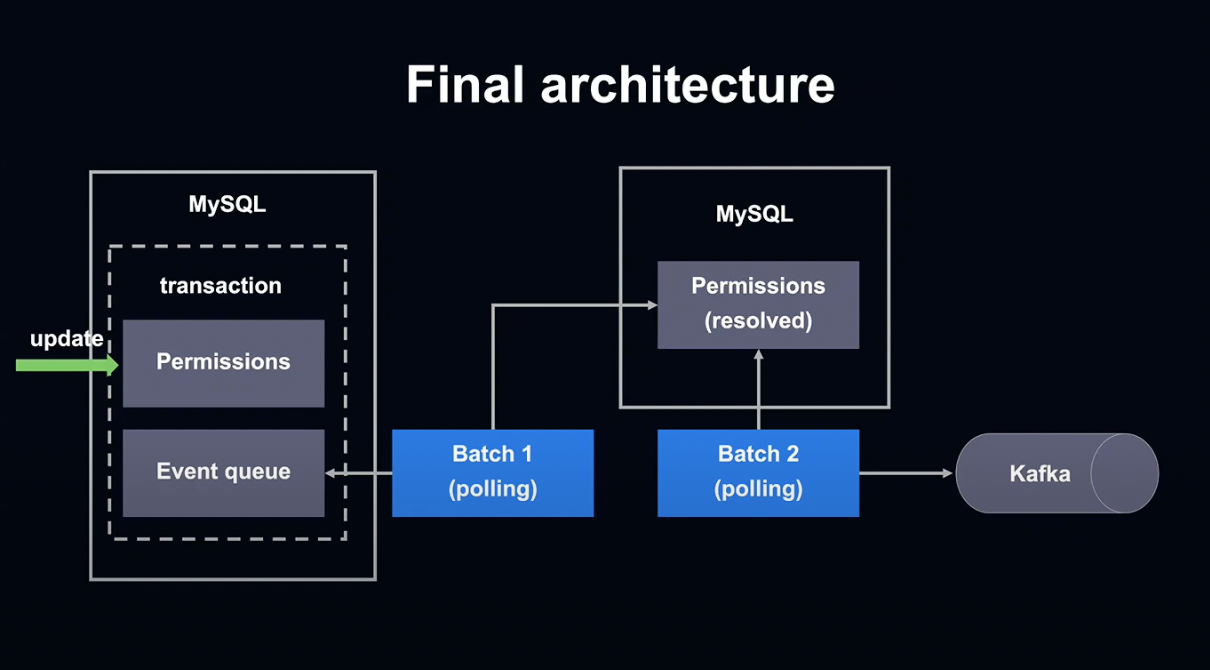
최종적인 구조는 다음과 같습니다.
공유 권한 설정 변경 및 Event Queue에 해당하는 테이블의 변경을 동일 트랜잭션에 적습니다.
첫 번째 Batch에서 Event Queue 테이블에서 변경을 읽어내고, 공유 권한 설정을 다른 데이터베이스 테이블에 적습니다.
두 번째 Batch에서 해결된 공유 권한 설정을 Kafka에 알립니다.
Batch를 2개 단위로 나누었기 때문에 문제 발생 시 Kafka의 송신 상태 관리 컬럼만 변경하면 설정이 재송신되고, 복구 작업이 쉬워집니다.
Development by Multiple Teams

시스템 설명에 이어 여러 팀이 어떻게 연계하여 개발하였는지에 대해 말씀드리겠습니다.
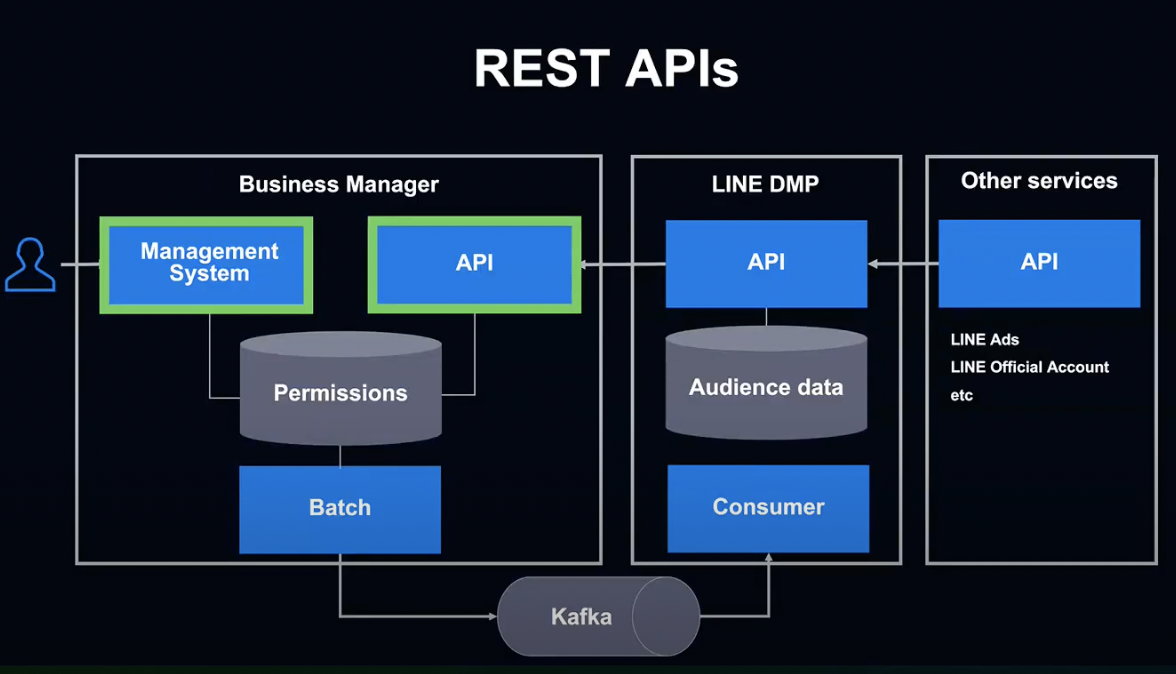
비즈니스 매니저 백엔드 개발팀은 여러 개의 REST API를 다른 팀에 제공하고 있습니다.
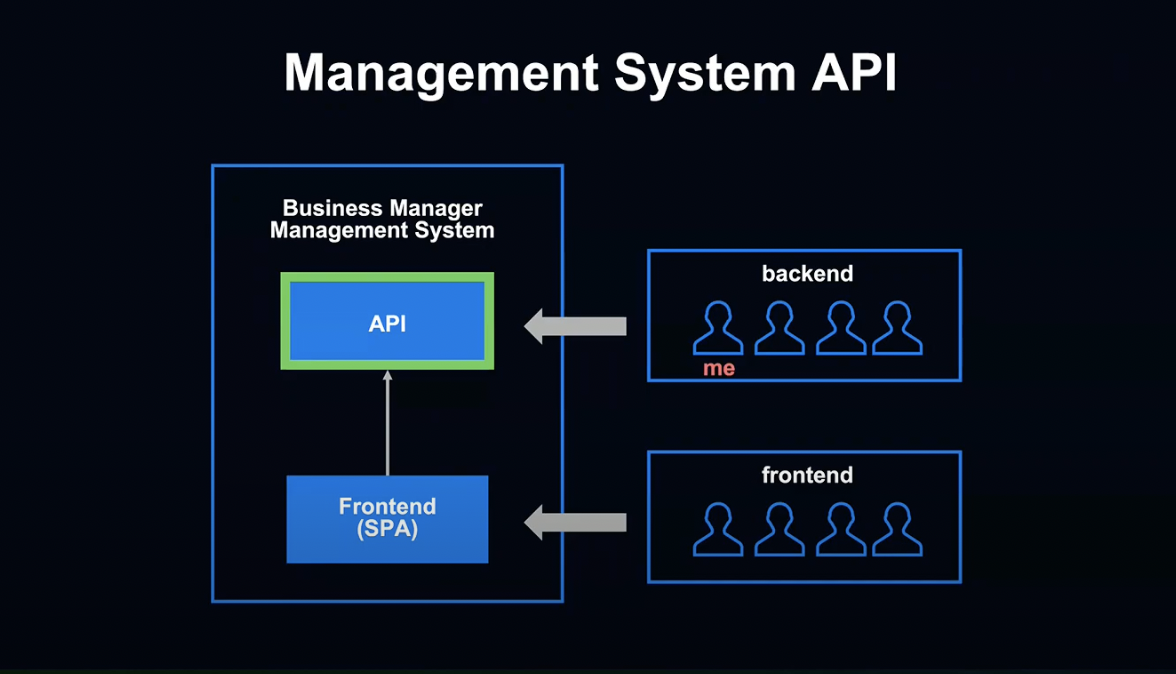
먼저 관리 화면용 API입니다.
Front-End팀에서는 SPA로 작성된 비즈니스 매니저 관리 화면에서 이 API를 사용합니다.
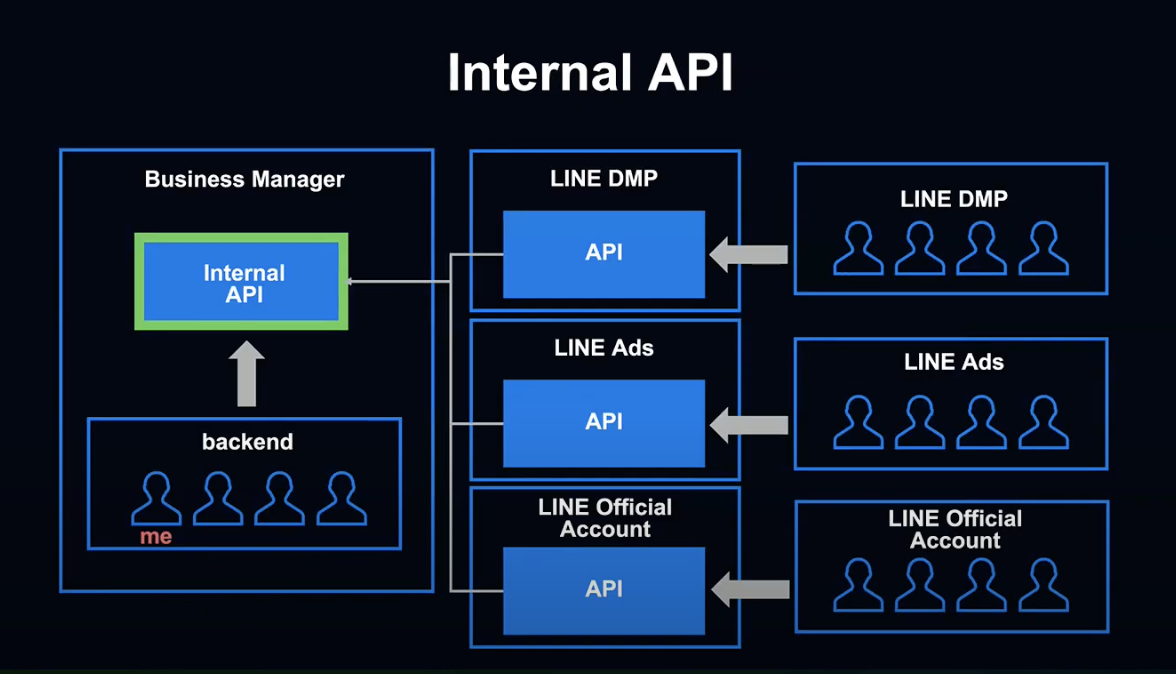
다음은 내부 시스템 전용 API입니다.
LINE DMP의 공유 권한 설정을 반환하는 API와 LINE 공식 계정의 비즈니스 매니저 계정 접속 API가 존재합니다.
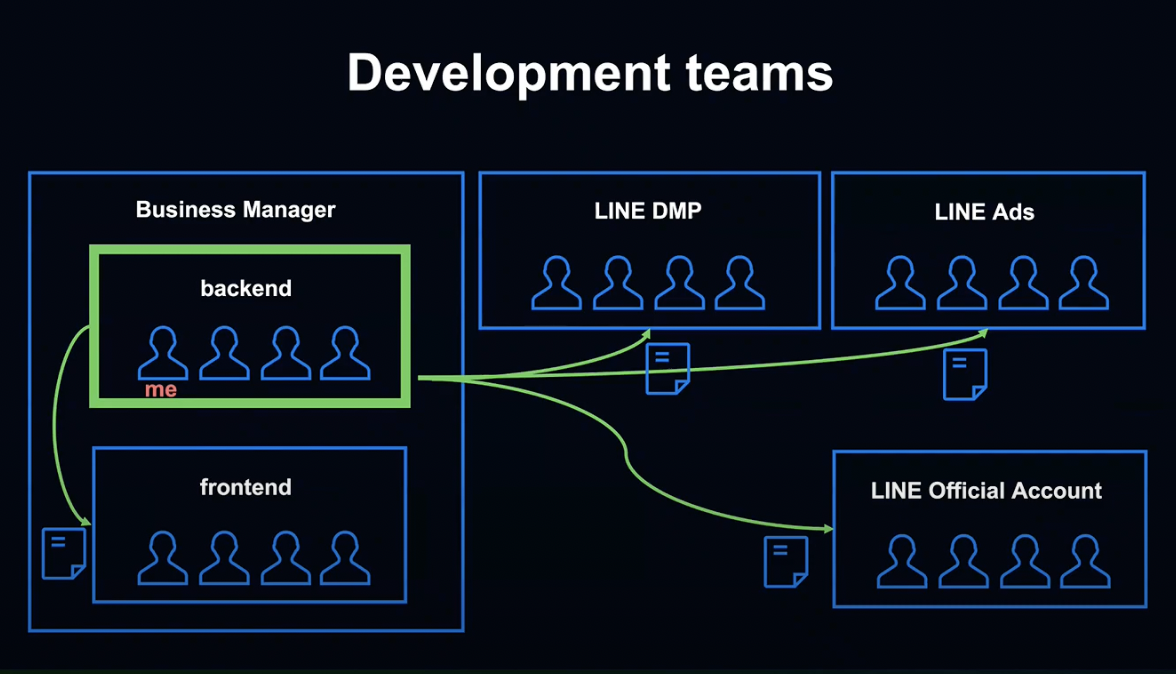
비즈니스 매니저의 초기 개발 때에는 Backend 팀이 이러한 API 사양을 정해야 했습니다.
다른 팀에게 짧은 개발 기간 동안 가능한 한 빨리 제공해야 했습니다.
여기서 과제가 된 것은 API Docs를 작성 및 유지보수하는 비용입니다.

사내에서도 부서에 따라 다르지만, 제가 소속된 부서는 사내 위키에 API Document를 기재하는 방식을 사용하고 있었습니다.
이 방법은 사양이 변경되었을 때 코드와 문서를 이중으로 관리하는 비용이 발생했습니다.
비즈니스 매니저의 초기 개발 때는 촉박한 스케줄 가운데 어려운 사양을 이해하면서, API Document까지 신속하게 작성해야 했습니다.
springdoc-openapi

이 문제에 대해, 저희는 springdoc openapi를 적용해 대응했습니다.

springdoc openapi는 Spring의 Controller에 Annotation만 달아주면 OpenAPI 3 버전의 JSON이나 YML을 생성해주는 라이브러리입니다.
Endpoint마다 Swagger UI를 사용할 수 있게 되어 Controller의 최신 API Document를 언제든지 열람할 수 있고, 실제 API도 실행해 볼 수 있습니다.
또한 Kotlin을 지원하기 때문에, Kotlin이 Not null일 때 필수 요소로 인식해 주기 때문에 매우 편리합니다.
독자적인 Annotation을 읽어 문서 항목을 추가하는 등의 커스터마이징도 가능합니다.
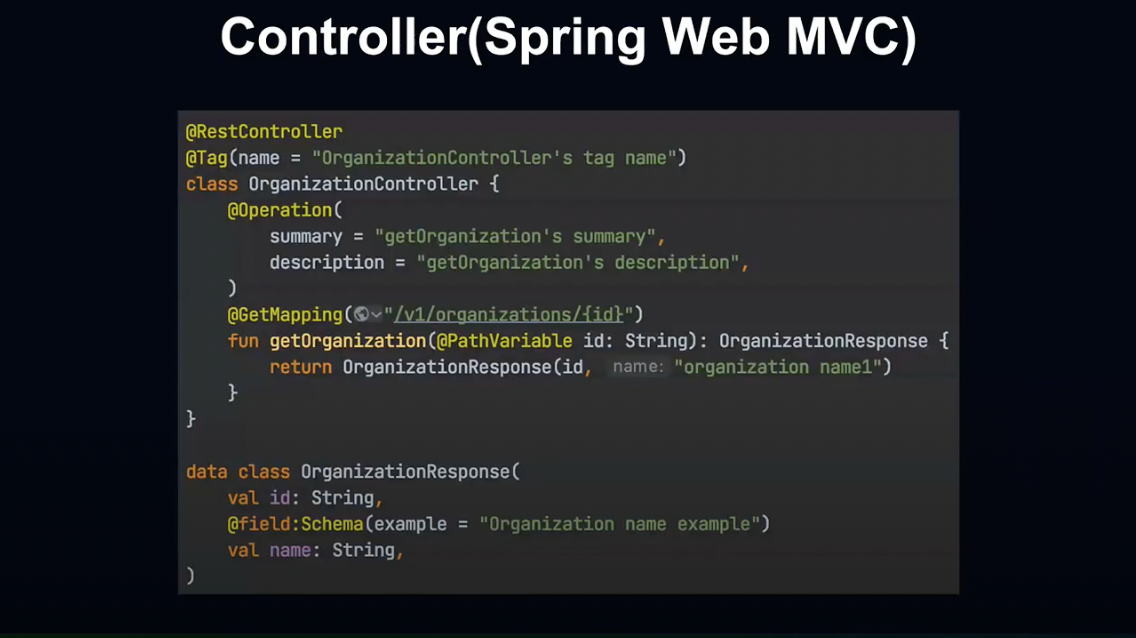
좀더 구체적인 예시를 보여드리겠습니다.
Spring Controller를 작성할 때 @Tag @Operation @Schema 등의 Swagger API Annotation을 붙여주는 것만으로 Swagger UI로 API 문서를 작성할 수 있습니다.
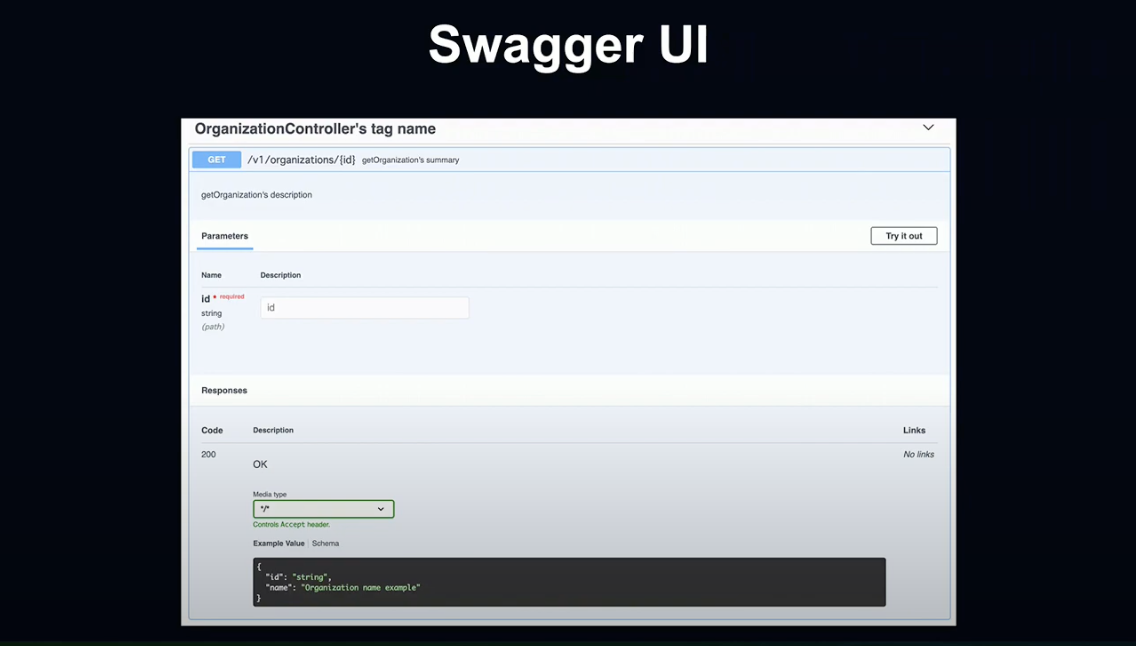
이러한 OpenAPI Version 3 형식의 파일로 특정 Endpoint를 취득 가능하기 때문에 Swagger UI 이외의 사용도 가능합니다.
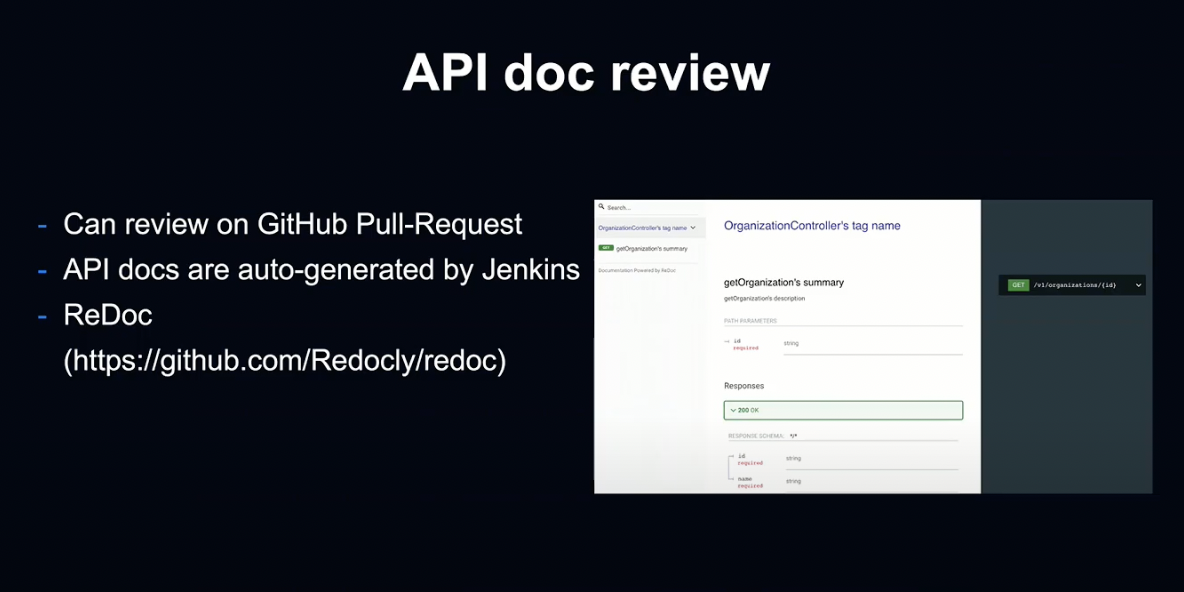
GitHub를 통해 개발할 때, Pull Request시 Branch별로 API 문서가 생성됩니다.
이 문서로 리뷰어는 API 사양을 쉽게 사용할 수 있습니다.

또한 비즈니스 매니저의 관리 화면을 작성하는 Front-End 팀에서는 TypeScript를 사용해 SPA 화면을 관리하고 있는데, TypeScript의 Open API 라이브러리를 사용해 Back-End API와 효율적으로 통합할 수 있습니다.
OpenAPI Typescript로 API parse, request, response의 정의가 생성되기 때문에 부드러운 API 추가 및 변경이 가능합니다.
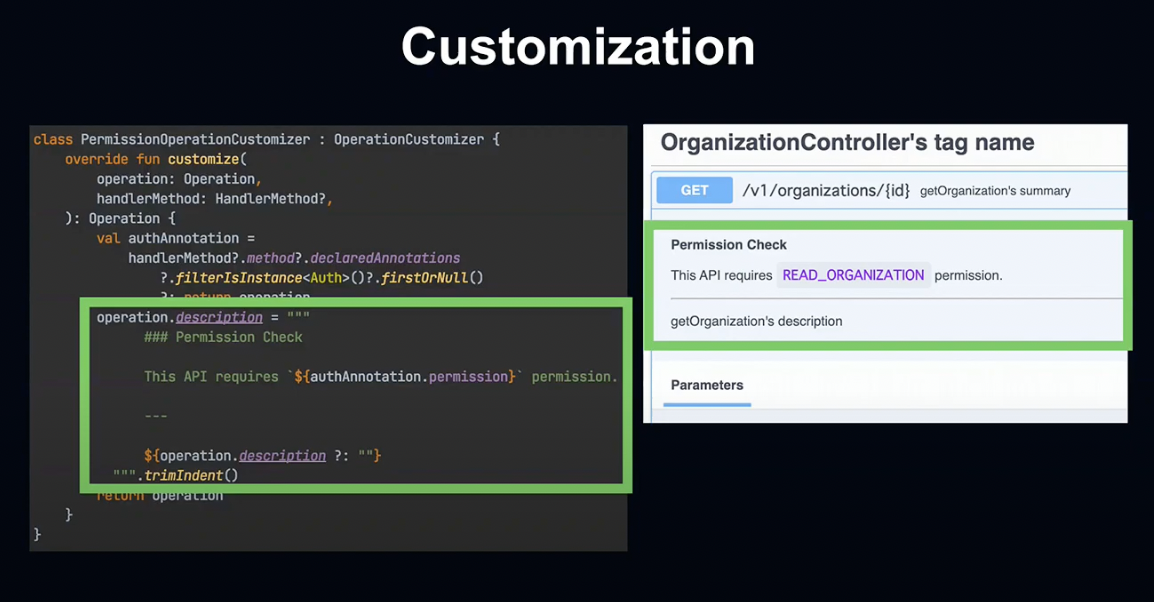
마지막으로 커스터마이징 응용 방법에 대해서 말씀드리겠습니다.
비즈니스 매니저 관리 화면에서는 기업 유저 이용을 가정하기 때문에, Admin이나 User와 같은 역할별 권한 관리 기능이 있습니다.
저희는 독자적인 Annotation을 통해 Controller에서 권한을 관리하고 있는데, springdoc-openapi의 Operation Customizer에서는 독자적인 Annotation을 읽어 초기화 시 등록합니다.
그 결과 어느 권한이 이 Endpoint에 엑세스 가능한지를 자동으로 문서에 반영하게 됩니다.
Programming Approach

지금부터는 문제를 해결할 때 어떤 프로그래밍 방식을 사용했는지 말씀드리겠습니다.
비즈니스 매니저는 ID 종류가 너무 많다는 문제가 있었습니다.
비즈니스 매니저는 다른 계정에 접속해 그 데이터를 공유하는 시스템 성격 상 ID의 종류가 많습니다. (ex. 비즈니스 매니저 / Orgazination, 라인 광고, 계정, LINE Tag, 유저 등..)
앞으로도 기능이 추가됨에 따라 접속하는 계정과 연결되는 데이터가 많아질 것입니다.
이러한 아이디를 정확하게 다룰 수 있게 아이디를 Value Object로 다루고 있습니다.
Value Object

Value Object란 Domain Driven Design에 기반한 Object로서, 동일성(Equality)과 불변성(Immutable)이 보장됩니다.
Kotlin에서는 Value Class에 기본 값을 감싸주기만 하면 쉽게 작성이 가능합니다.

Value Object의 ID를 Controller에서 받으면 데이터베이스에 입력될 때까지 프로그램 내에서 일관되게 이용될 수 있게 하여 프로그래밍 상의 대입 실수를 방지합니다.
상단 코드의 예시처럼 Value Object를 사용하여 인수 대입의 실수 등을 컴파일 시에 확인할 수 있습니다.

또한 Value Object를 springdoc api와 융합하면 문서 작성도 효율화 할 수 있습니다.
정의한 ID에 Annotation을 부여해 문서 상에서도 ID 정의를 함께 사용할 수 있습니다.
Kotlin

비즈니스 매니저에서는 Kotlin의 기능을 최대한으로 활용하고 있습니다.

Null Safety로 인해 Nullable 클래스와 Notnull 클래스를 구별해 안전한 프로그래밍이 가능합니다.

또한 비즈니스 매니저는 계정 데이터 타입이 많고 앞으로도 증가할 예정입니다.
Sealed 클래스 인터페이스의 when 분기 명령으로 계정이나 데이터 타입 별 처리가 가능합니다.
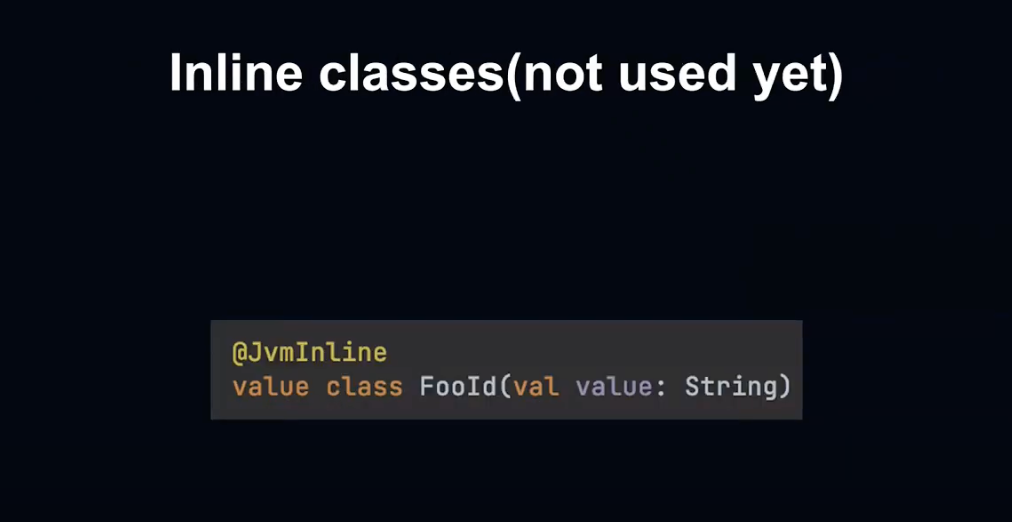
개발 당시에는 실험적인 기능이었기 때문에 사용하고 있지 않지만, 기본값을 Wrap하는 Inline Class를 추후 활용할 예정입니다.
이와 같은 Kotlin의 편리한 기능들을 적극적으로 사용하고 있습니다.
New Team. COVID. ETC

여기까지 몇 가지 기술적인 내용을 설명드렸습니다.
마지막으로 하나 더, 비즈니스 매니저의 개발을 통해서 배운 내용을 공유하겠습니다.
비즈니스 매니저의 개발은 지난 1월에 출범한 새로운 팀에서의 개발이었습니다.
팀이 출범된 직후 COVID-19로 인해 완전 원격근무가 시행되었고, 이러한 가운데 팀 개발을 시작했습니다.
이러한 상황에 있어 몇 가지 효과적이었던 사례를 공유하겠습니다.

새로운 팀에서 개발에 관한 자세한 인식을 공유하고 싶어 Mob Programming을 시도했습니다.
Mob Programming은 팀 전원이 하나의 프로그래밍을 하는 것으로, Pair Programming을 여러 명이 하는 것이라고 생각하면 이해가 쉽습니다.
Driver가 실제 코딩을 하고, Navigator가 다른 사람이 어떤 코드를 작성할지 지시하고, Driver가 교대할 때에는 Git Branch에 변경을 Push해 다음 Driver에게 개발을 넘겨주게 됩니다.
또한 프로그래밍 뿐만 아니라 릴리즈, 인프라 관련 작업도 Zoom으로 화면을 공유해 Mob으로 작업 중입니다.
팀에 기술을 공유하고, 팀워크를 새로 조성한다는 점에서 효과적이었던 기술입니다.

Zoom을 특정한 룸에서 카메라와 마이크를 끈 상태로 상시 연결해, 필요할 때 언제든 말을 할 수 있는 상황을 만들었습니다.
기본적으로 Slack을 통해 비동기 커뮤니케이션으로 개발 중이지만, 비즈니스 매니저의 경우엔 사양 면에 의문이 있을 때 화면을 공유하며 이야기하는 것이 편할 때가 많아 유용하게 사용할 수 있습니다.

매일 오전 11시에 아침 모임을 가져 인식을 공유하고 싶은 과제, 사소한 이야기 등 모든 것을 다 함께 이야기하는 시간을 마련했습니다.
또한 태스크 관리를 위해 그날 하는 것을 트리 형식으로 그리고, 테스크를 가져가는 형식을 채택했습니다.
원격 근무는 다른 분들이 무엇을 하고 있는지 파악하기 힘들다고 느낄 때가 많기 때문에 모든 알람을 Slack에 표시했습니다. (ex. GitHub Pull Request, CI Result..)
또 릴리즈 때에도 전용 Bot을 통해 Slack 상으로 알 수 있게 했습니다.
Summary

이제 정리하는 시간을 갖도록 하겠습니다.
비즈니스 매니저는 마케팅 데이터를 활용하기 위한 차세대 기반 플랫폼입니다.
앞으로도 접속 서비스를 확대하는 등 지속적으로 개발을 추진해 나가겠습니다.
비즈니스 요건이 복잡해 시스템적으로 해결할 과제가 많지만, 그만큼 보람차다고 생각합니다.
이상으로 발표를 마치겠습니다. 경청해 주셔서 감사합니다.
8년간 유지해 온 Perl 프로덕트를 Kotlin으로 바꾼 이야기 - Kohei Ohara

이번 세션의 발표를 맡게 된 개발자 Ohara입니다.
Agenda

본 세션의 Agenda는 다음과 같습니다.
- LINE Point Club에 대하여
- Perl을 Kotlin으로 변경한 이유
- 변경 후 시스템 Overview
- 프로젝트를 어떻게 진행했는지
- 프로젝트 진행 중 발생한 어려움과 경험
이 세션이 끝나면 언어 변경의 장점을 알게 될 것입니다.
시스템을 변경하는 모든 분들에게 도움이 될 것이라고 예상합니다.
LINE Point Club

먼저 LINE Point Club에 대해 소개해 드리겠습니다.
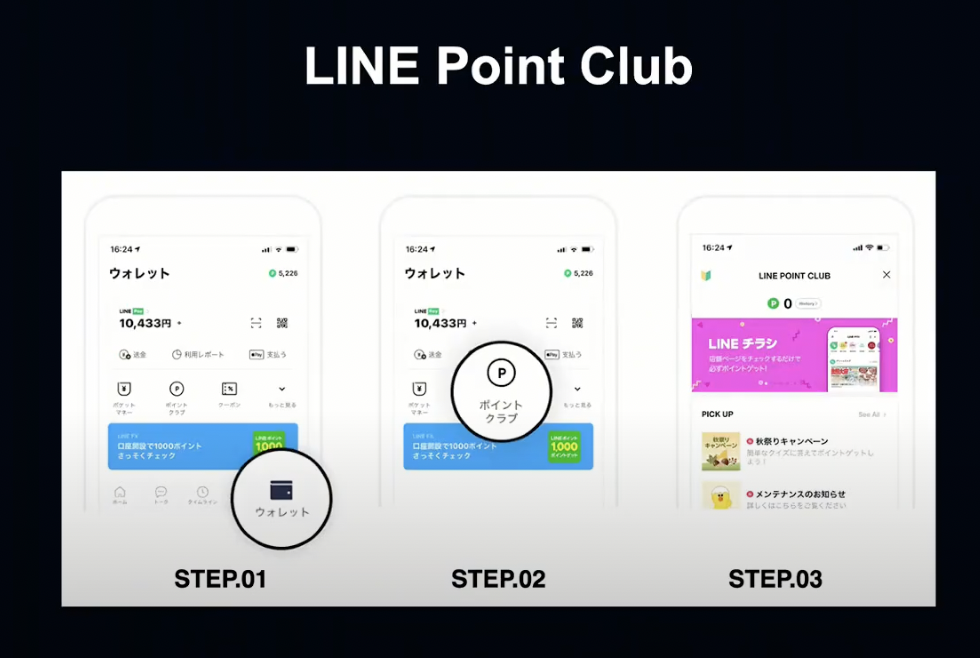
LINE Point Club은 LINE Pay는 물론 LINE의 각종 서비스에서 사용할 수 있는 공통 포인트인 LINE Point를 적립하고, 연계된 서비스를 활용할 수 있는 포털 서비스입니다.
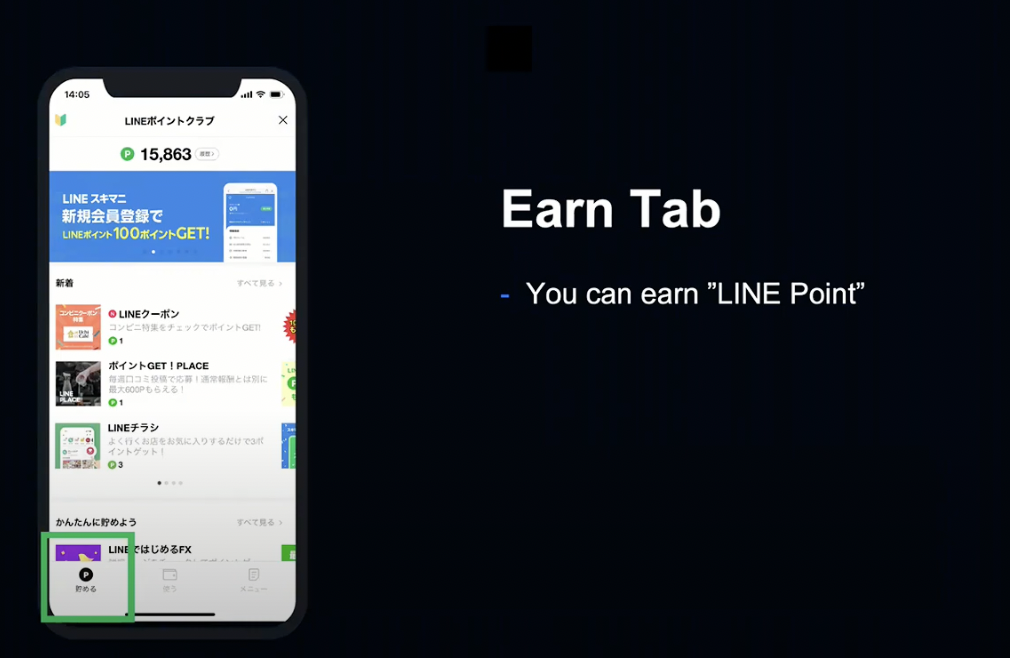
LINE Point Club에는 적립 탭과 사용 탭이 있습니다.
적립 탭에서는 포인트를 적립할 수 있고, 유저가 동영상을 보거나 앱을 설치하는 등의 미션을 달성하면 포인트가 적립됩니다.
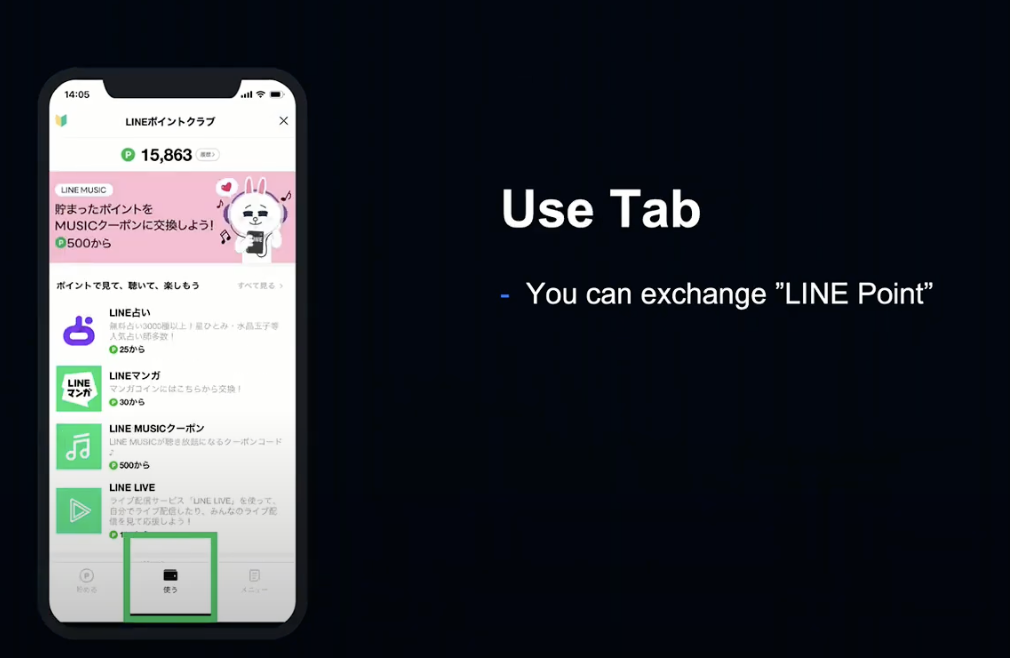
사용 탭에서는 이렇게 모은 포인트를 사용할 수 있습니다.
LINE Manga, Music 등에서 사용할 수 있는 코인이나 쿠폰을 비롯해 다양한 서비스에서 사용할 수 있습니다.
LINE Point System
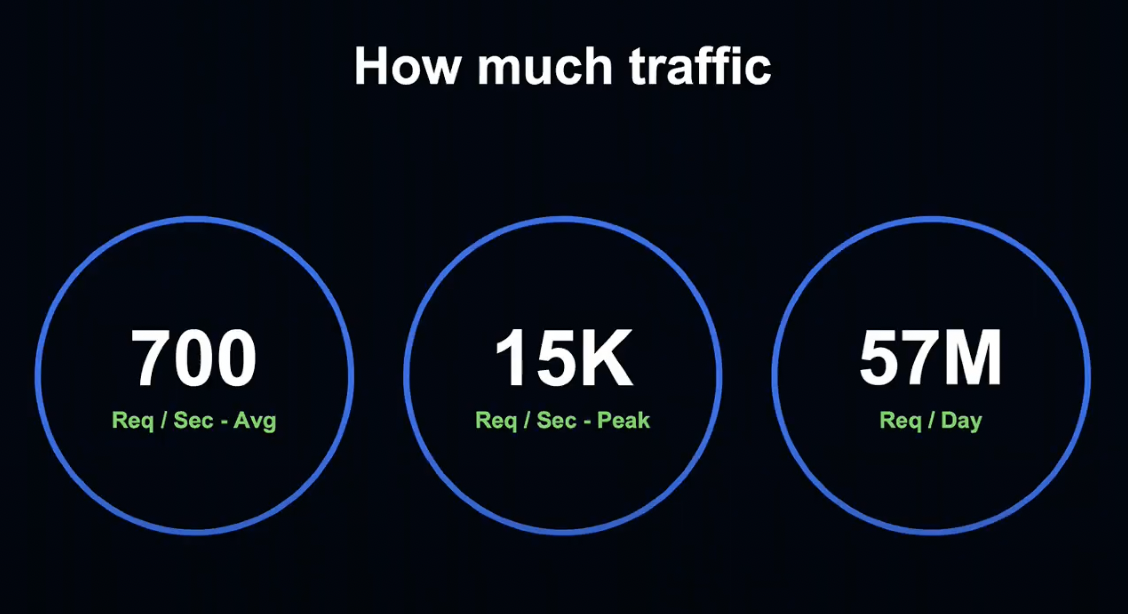
LINE Point에서는 평균적으로 초당 700번, 피크 시 초당 15,000번의 요청이 발생합니다.
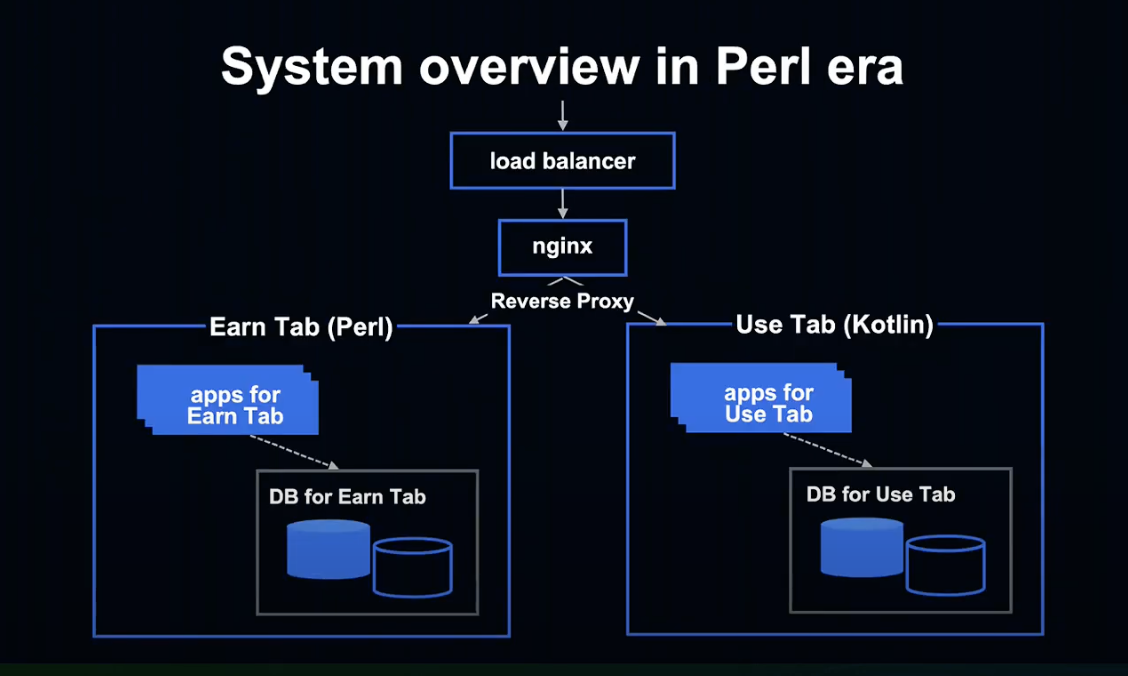
이 슬라이드는 Perl 시절의 서버 측 시스템의 구성을 간략화한 것입니다.
외부 인터넷에서 요청이 오면, 로드 밸런서가 수신하여 Nginx로 보내고, Nginx가 적립 / 사용으로 각각 Proxy합니다.
적립 탭과 사용 탭은 각각 다른 데이터베이스를 보유 중이며, 각각의 앱이 컨텐츠를 반환하도록 구성되었습니다.
적립하기는 Perl, 사용하기는 Kotlin으로 작성되었는데, 언어가 서로 다른 이유는 적립과 사용의 개발 시기가 각각 달랐기 때문입니다.
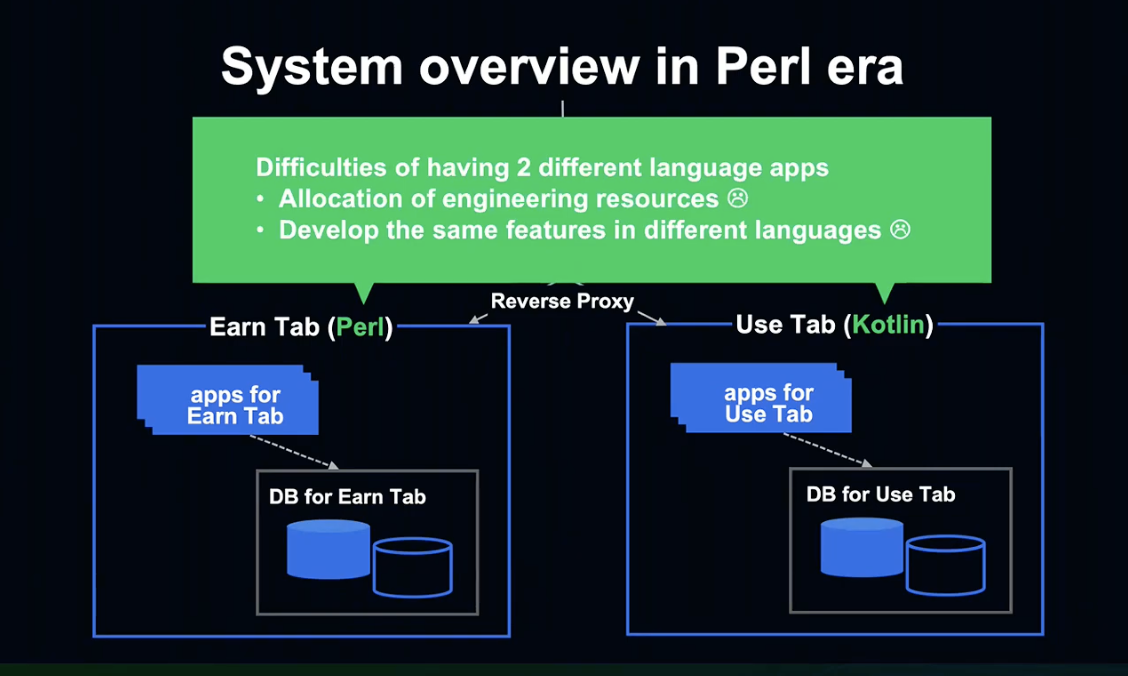
서로 다른 언어로 작성된 두 가지 앱을 관리하는 것은 매우 번거로웠습니다.
Nginx 자원 배분을 비롯해 적립 / 사용 탭에서 똑같은 기능을 따로 개발해야 하는 어려움이 존재했습니다.
이 세션은 Perl 프로젝트를 변경한 내용이기 때문에, 문제 해결에 앞서 적립하기에 대해서 설명드리도록 하겠습니다.
Perl Earn Tab
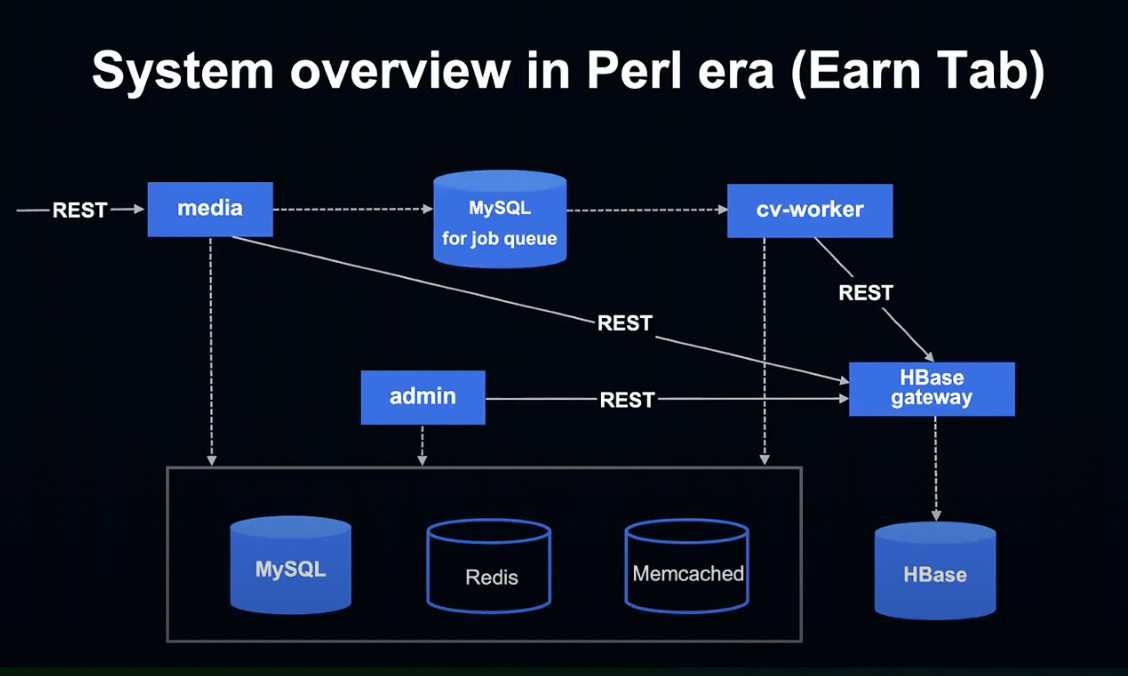
적립하기 탭의 시스템 Overview를 하나씩 살펴보도록 하겠습니다.
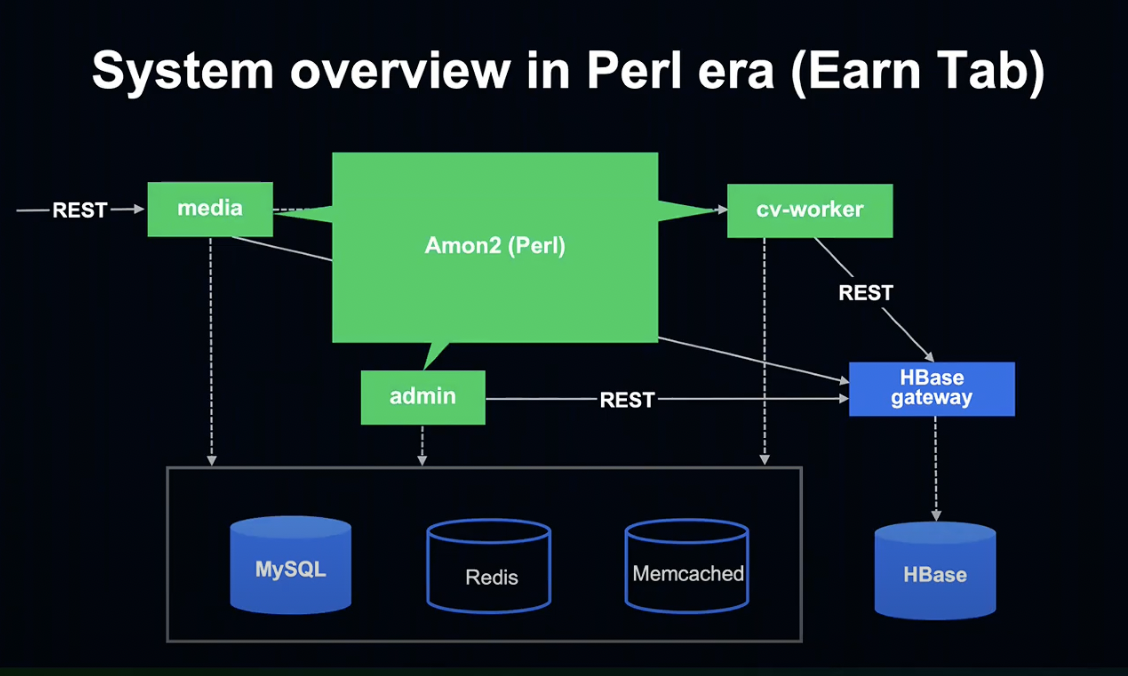
먼저 Media, Admin, cv-worker는 Amon2라는 Perl Framework로 작성되어 있었습니다.
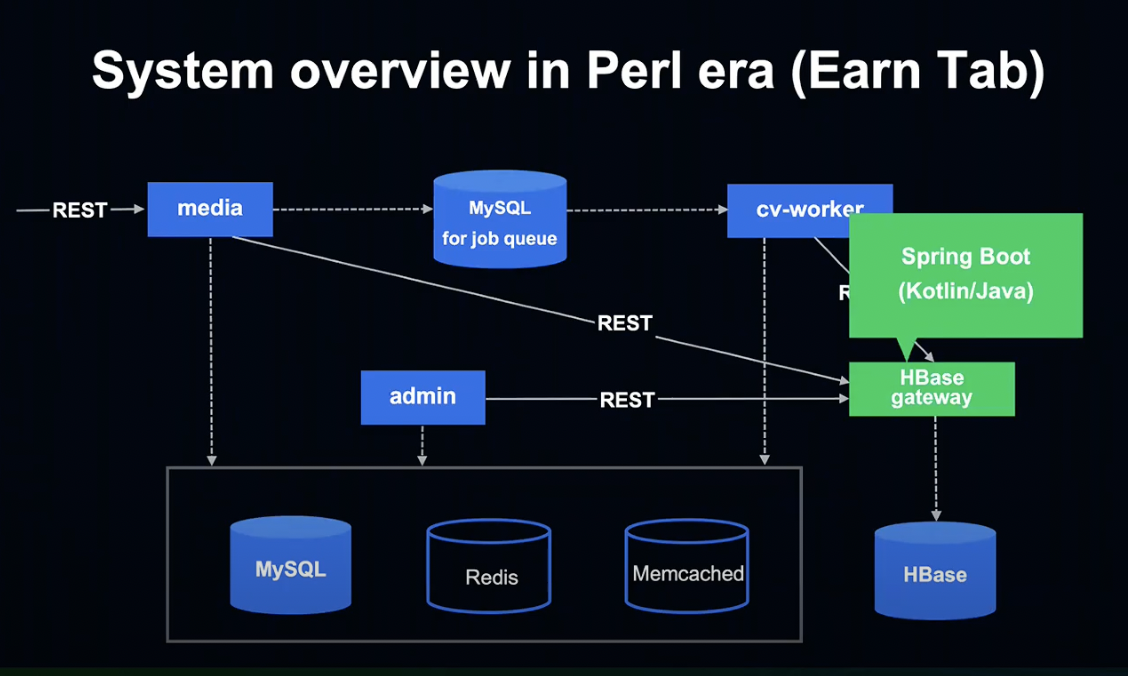
그리고 HBase gateway는 Kotlin & Java와 Spring Boot를 사용해 작성되어 있었습니다.
Perl에서는 HBase를 직접 사용할 수 없는 문제가 있어, Spring Boot로 Gateway를 만들어 간접적으로 HBase를 사용 중이었습니다.
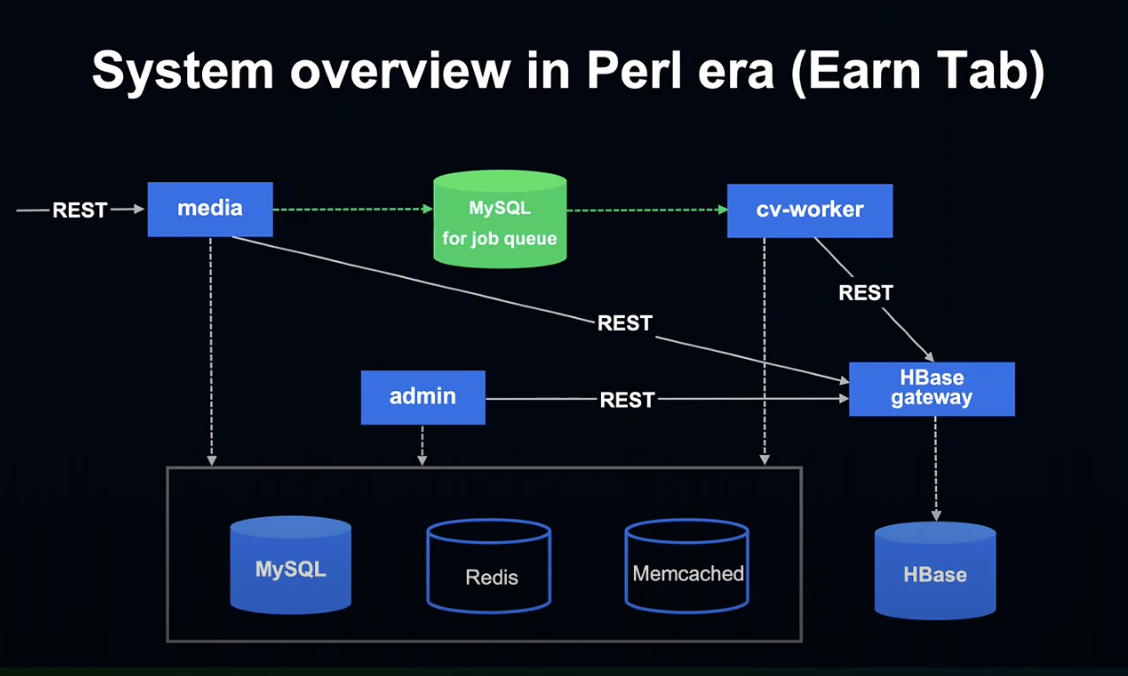
MySQL for job queue에서는 유저가 적립하기 탭에서 달성한 미션 데이터를 Job Queue에 적재하고, Queue는 MySQL에 저장되어 cv-worker가 처리하게 됩니다.
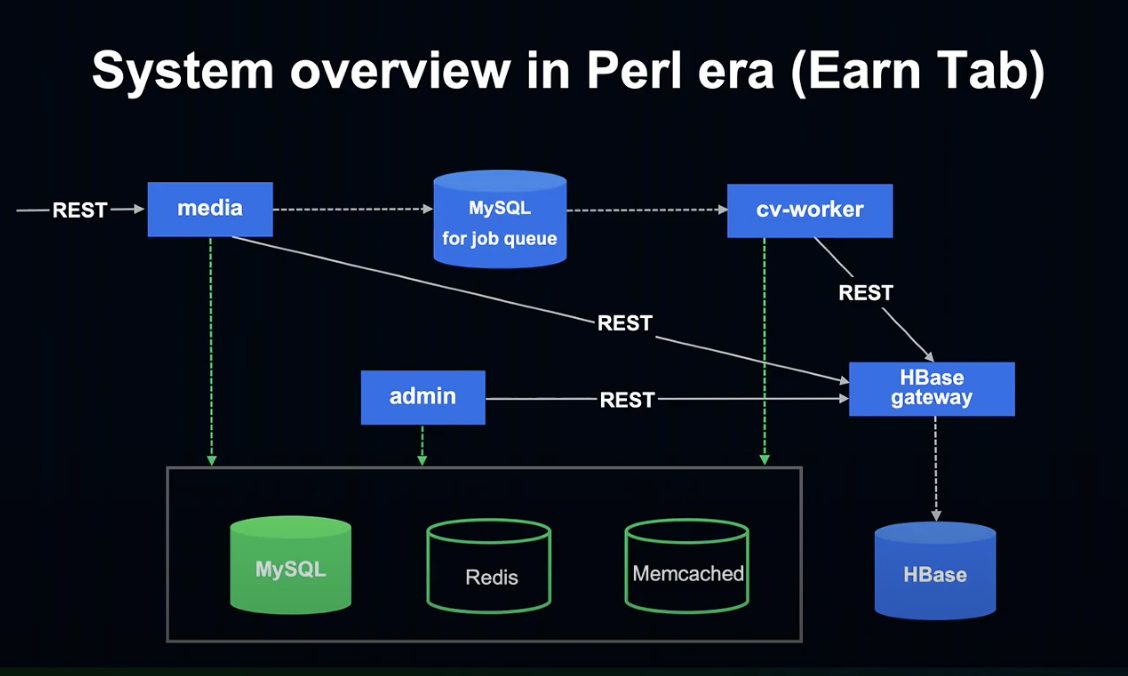
데이터베이스로는 MySQL, 캐시로는 Redis, Memcached를 사용 중입니다.
Why did we decide to rewrite Perl to Kotlin?

지금부터 Perl을 Kotlin으로 변경한 이유에 대해 말씀드리겠습니다.

변경 언어를 Kotlin으로 정한 이유는 LINE Server side 개발에서 가장 많이 사용하는 언어가 Java & Kotlin이기 때문입니다.
같은 언어를 사용하면 엔지니어 자원 배분과 사내 생태계 이용이라는 큰 장점이 있기 때문에 Kotlin을 선택하게 되었습니다.
Java를 선택하지 않은 이유는 팀 내 다른 프로덕트와 기술을 맞추고 싶었기 때문입니다.

Perl을 Kotlin으로 변경하기로 결정한 이유에 대해 말씀드리겠습니다.
먼저 시스템 구성이 복잡해지는 문제가 있습니다.
Overview에서 말씀드렸다시피 저장하기 탭과 사용하기 탭이 다른 언어로 구현되어 있고, Perl이 HBase를 사용하기 위해선 별도의 Gateway를 관리해 줘야 할 필요가 있었습니다.
두 번째로 기능이 복잡해지는 문제가 있습니다.
관련된 다양한 기능이 추가 및 변경 삭제됨에 따라 기능이 복잡해지고, 사용하지 않는 기능도 많았습니다.
세 번째로 Perl 엔지니어가 너무 적었기 때문에 언젠가 개발을 계속하지 못하게 될 미래가 보였습니다.
네 번쨰로 다음 프로젝트 시작 전 6개월 정도 큰 변경이 없는 기간이 생겨, 변경한다면 지금이라고 생각했습니다.

마지막으로 Perl의 라이브러리를 유지보수할 엔지니어가 감소하고 있습니다.
아까 말씀드렸던 HBase 사용 문제를 비롯한 미들웨어 클라이언트 라이브러리 부족 문제가 있었습니다.
System overview after remaking

Kotlin으로 변경 후 시스템 Overview를 살펴보도록 하겠습니다.
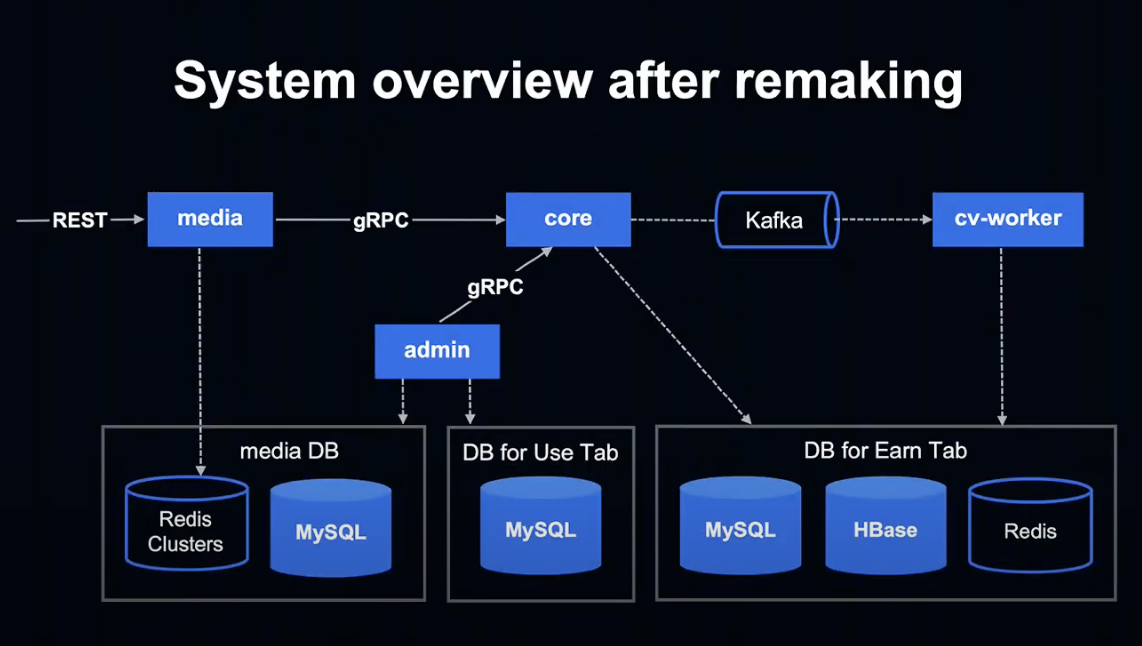
간단히 나타내면 이런 모습입니다. 순서대로 살펴보겠습니다.
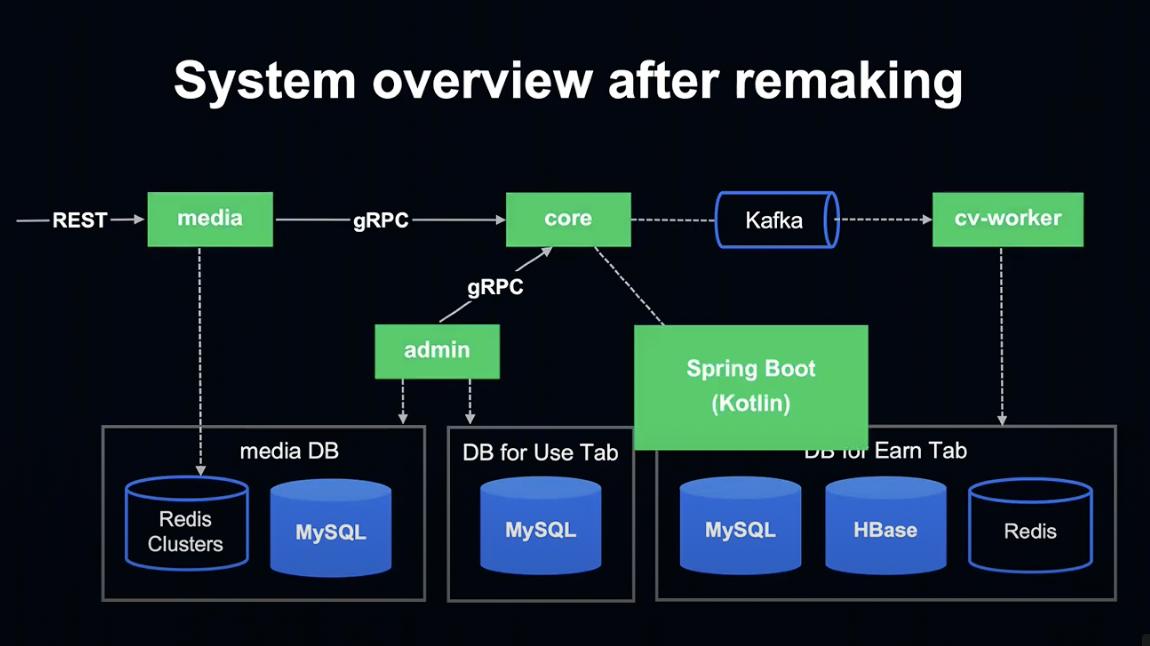
먼저, 모든 애플리케이션이 Spring Boot & Kotlin으로 구현되어 있습니다.
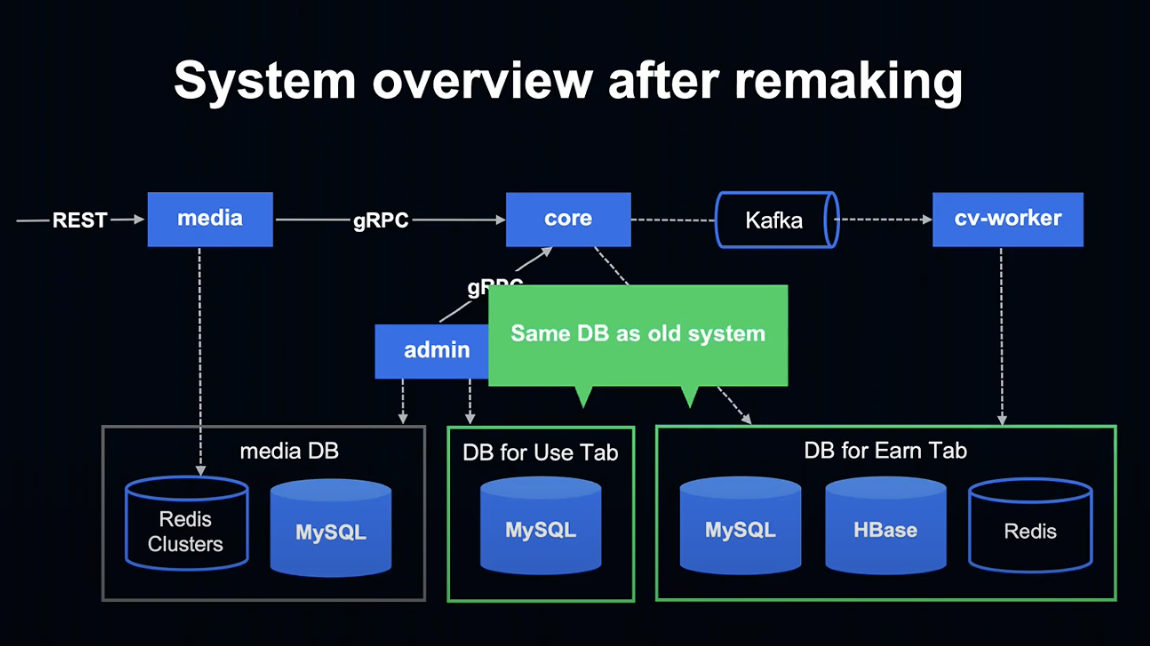
데이터베이스는 과거에 사용했던 저장하기 탭과 사용하기 탭의 데이터베이스를 그대로 사용하고 있습니다.
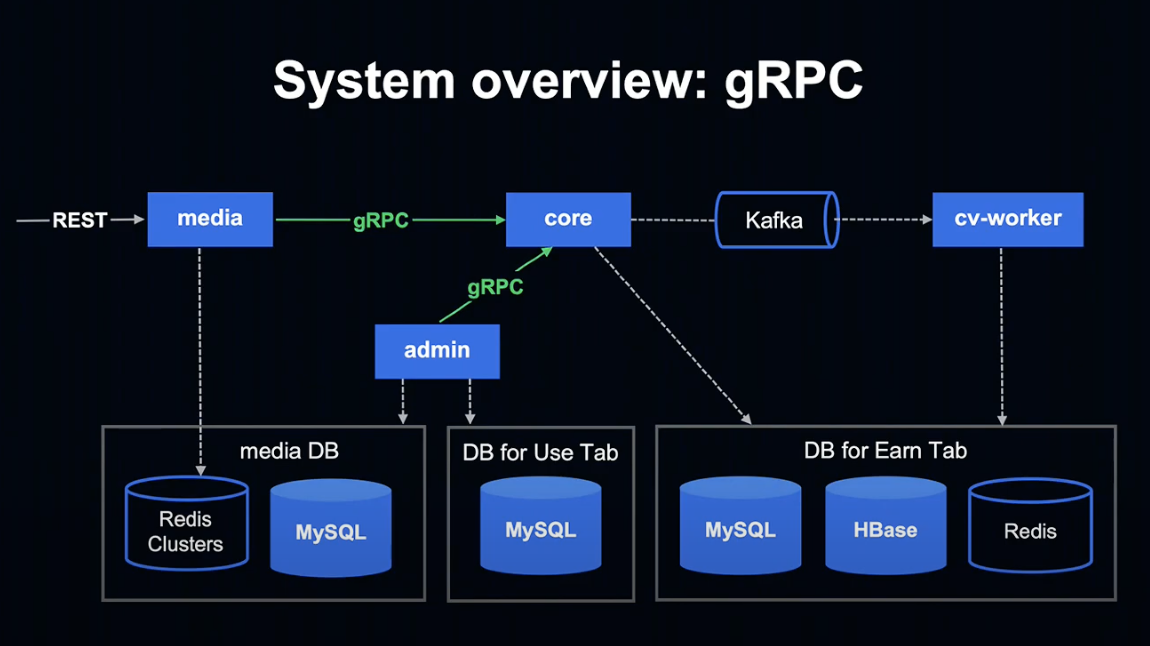
지금부턴 변경된 부분에 대해 살펴보도록 하겠습니다.
어플리케이션 간 통신은 gRPC를 사용하게 되었습니다.
프로토콜 버퍼를 통한 직렬화 고속 통신이 가능하고, IDL로 정의된 API 사양이 클라이언트와 서버 측 각각의 코드를 정리해 주기 때문에 매우 편리한 장점이 있습니다.
Point Club 적립하기 탭의 데이터는 크고 복잡한 경우도 있는데, gRPC는 이러한 데이터의 애플리케이션 간 통신 시 어려움이 없는 장점이 있습니다.
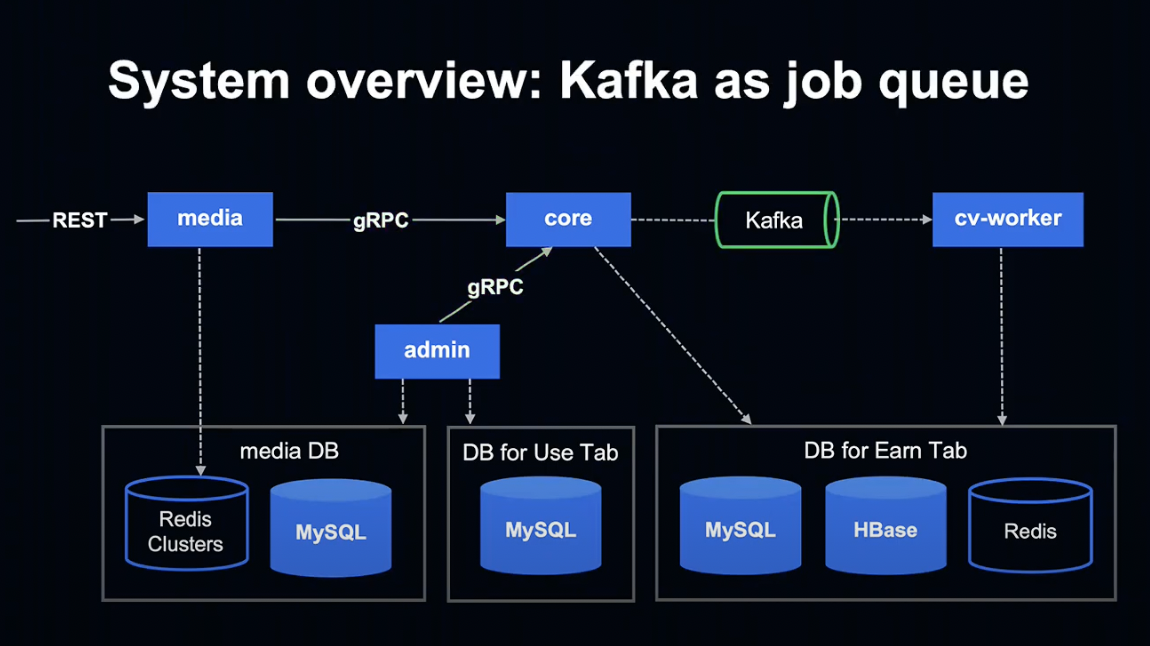
Kafka를 Job Queue에 도입했습니다.
이에 따라 확장성이 증가하고, Consumer에 따라 다른 처리가 가능해졌습니다.
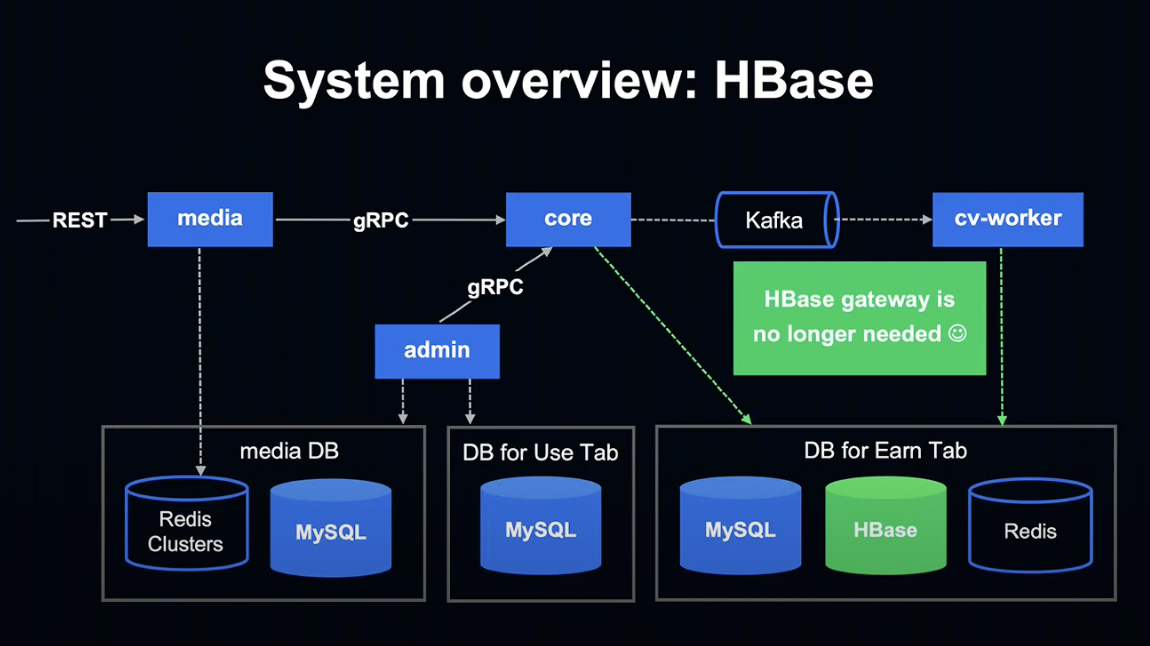
또한 HBase의 사용이 편리해졌습니다.
Perl 시절 사용했던 Gateway가 필요 없어져 관리 비용이 줄어들고, core와 cv-worker 등에서 직접 HBase 조작이 가능하게 되었습니다.
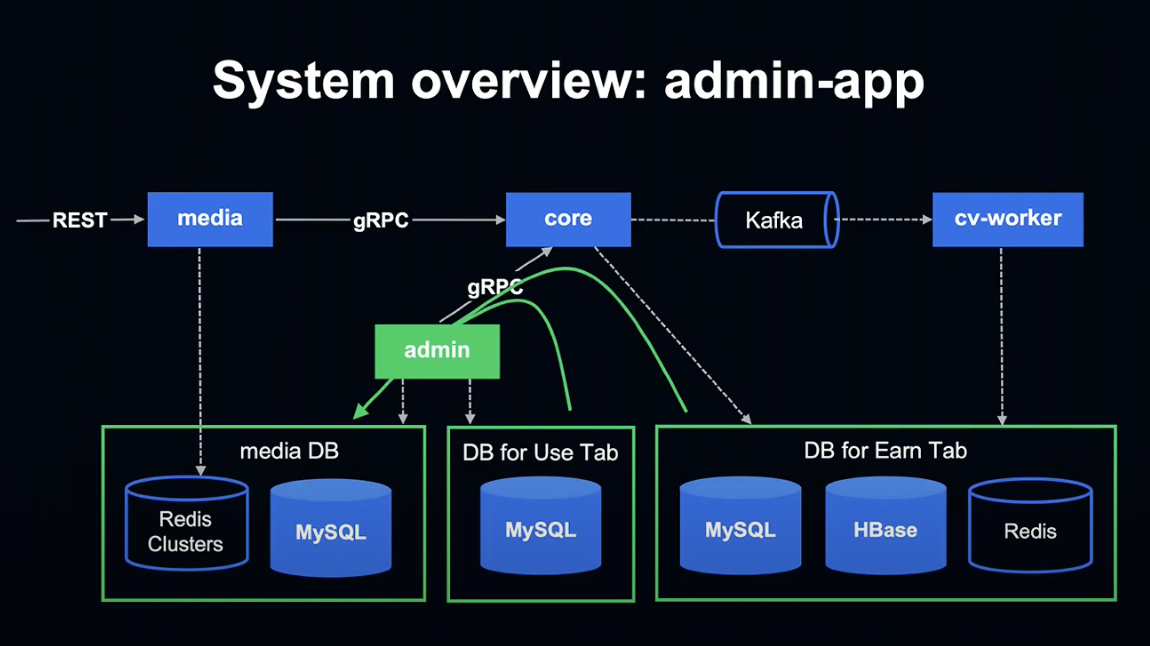
admin은 적립 / 사용 탭의 데이터를 Media 데이터베이스에 입력하여 Media 데이터베이스가 적립 탭과 사용 탭의 차이를 흡수하는 레이어로 작용하게 합니다.
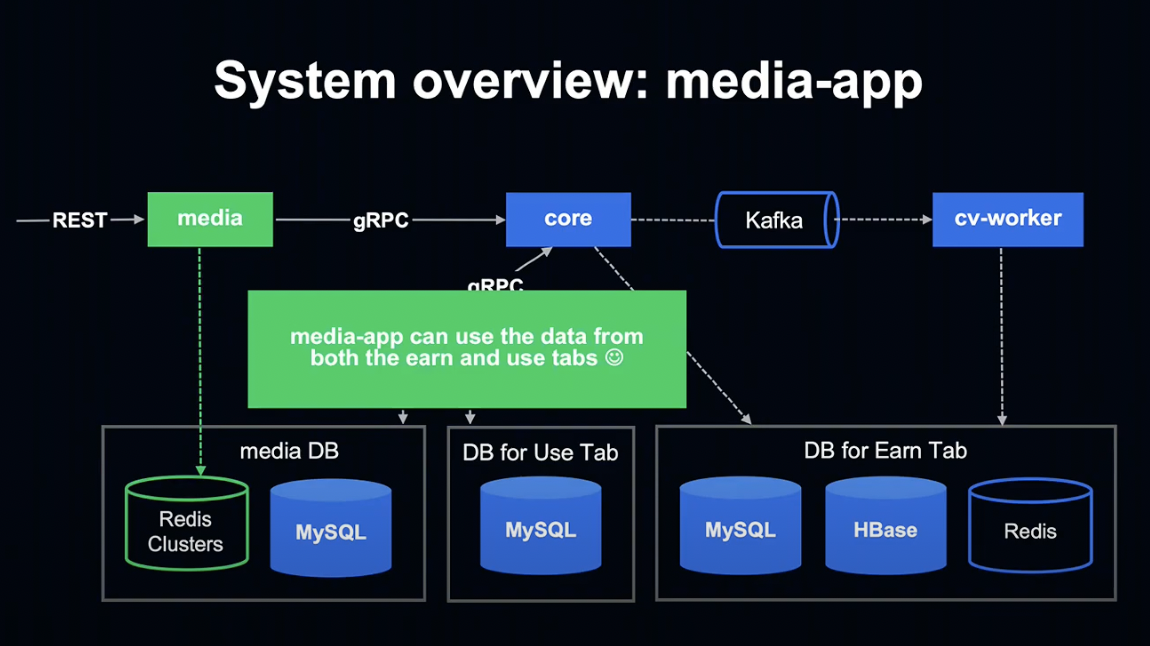
그 결과 Media 앱은 적립 / 사용 탭 양쪽의 데이터를 반환할 수 있게 되었습니다.
또한 Media 앱은 Redis Cluster에만 접속하기 때문에 향후 Kubernetes 등으로 언제든지 변경이 가능한 높은 확장성을 유지하고 있습니다.
How to proceed with the project

다음으로 프로젝트를 어떻게 진행했는지에 대해 말씀드리겠습니다.

먼저 개발 멤버의 구성을 살펴보겠습니다.
개발 멤버는 모두 6명으로, 3명이 Java / Kotlin, 3명이 Perl 엔지니어였습니다.
Java / Kotlin 엔지니어들은 Spring Boot와 Kotlin에 익숙하고, Perl 엔지니어들은 사양을 파악하고 있었습니다.
적립의 사양을 잘 파악하고 있는 Perl 엔지니어들이 사양을 작성하여 개발을 원활하게 돕고, Kotlin 엔지니어들이 실제로 개발했습니다.

프로젝트 기간 중 서비스 운영과 기획에 대해 어떤 체제로 진행했는지 말씀드리겠습니다.
먼저 오래된 시스템에 대해 새로 변경을 추가하지 않기로 했습니다.
변경을 추가하면 새로 작성된 Kotlin에도 적용해야 해 개발 공수가 늘어나 변경 작업이 늦춰지기 때문입니다.
또한 Daily Meeting을 진행하여 개발 의사 결정을 신속하게 내릴 수 있었습니다.
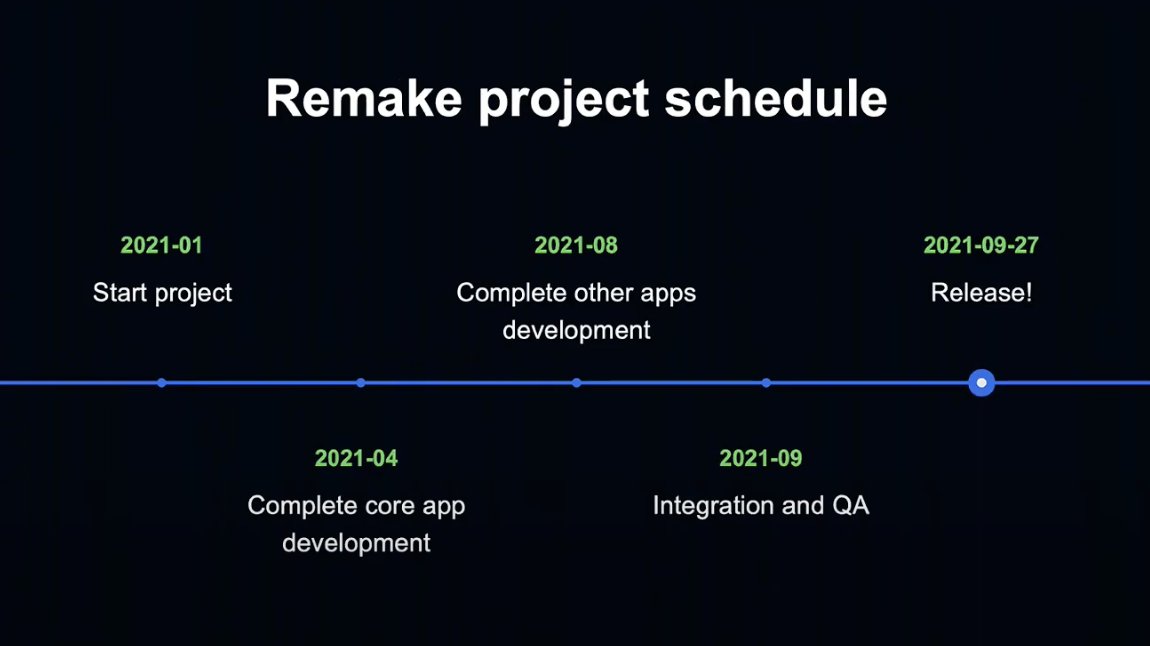
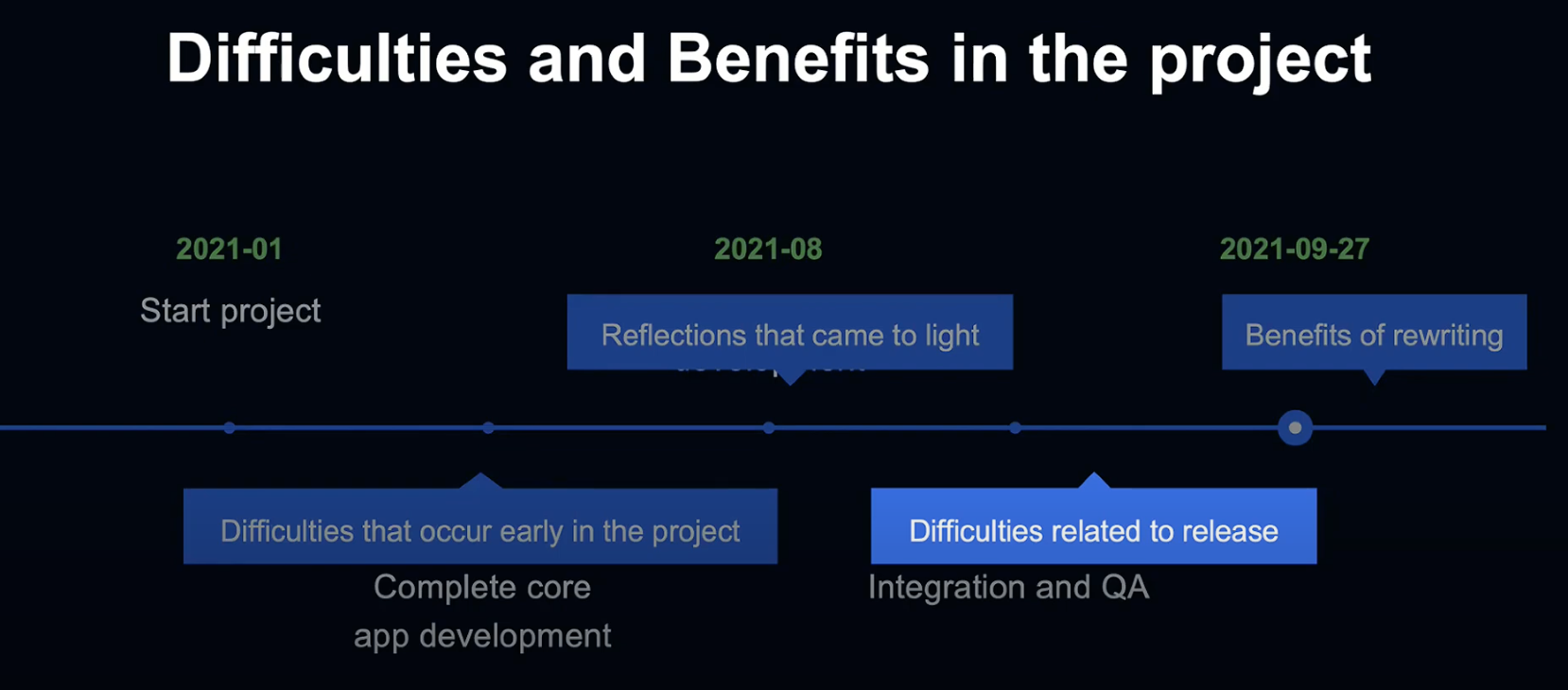
이번 프로젝트의 일정은 이렇게 진행되었습니다.
2021년 1월에 프로젝트를 시작하여 4월쯤에 core의 개발이 완료되었고,
8월에는 Media, Admin, Cv-worker의 개발이 완료되었습니다.
9월까지 통합 및 QA를 진행한 후, 9월 27일에 릴리즈되었습니다.
Difficulties and Benefits in the project

마지막으로 프로젝트 진행 중 발생한 이슈와 얻은 경험, 다른 언어로 변경할 때의 장점에 대해 말씀드리겠습니다.
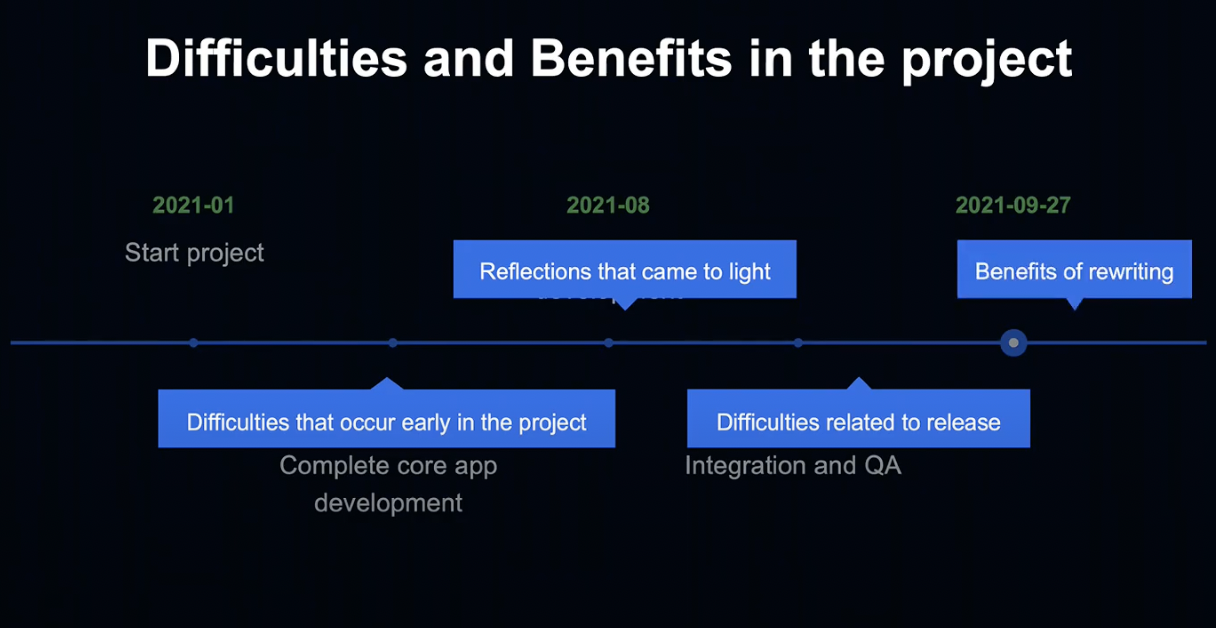
초기 개발에 있었던 어려움, 개발 중후반에 접어듬에 따라 발견된 반성할 점, 릴리즈 시의 어려움, 다른 언어로 변경함에 따라 얻은 이점을 차례대로 설명드리겠습니다.
Difficulties and Benefits in the project

먼저 프로젝트 초기에 발생한 이슈에 대해서 말씀드리겠습니다.
이야기를 시작하기 전 먼저 질문을 하나 드리겠습니다.
개발 언어를 변경하는 것은 기본적으로 이사하는 것과 비슷합니다.
여러분은 이삿짐을 쌀 때 무엇을 먼저 하십니까? 대부분 지금 있는 물건들을 정리해 버릴 수 있는 것들을 버릴 것입니다. 모든 짐을 몽땅 박스 안에 넣어서 이사하는 사람은 없습니다.

그와 마찬가지로 먼저 버려야 할 기능을 정리했습니다.
8년간 운영되어 온 Product엔 구현되어 있지만 사용하지 않는 복잡한 기능들이 많았습니다.
이런 기능들의 사용 여부를 하나하나 정리해 새로운 사양에 반영하는 작업이 굉장히 힘들었습니다.
또한 사용하지 않는 기능뿐만이 아닌 사용하고 있으나 당시 사정 때문에 억지로 만들어둔 부분에 대해서도 대처를 검토할 필요가 있었습니다.

두 번째로 어떤 기능을 버릴 것인지 멤버들 사이의 인식 공유 문제가 있었습니다.
문서에 삭제할 기능에 대해 기술되어 있지 않은 부분이 있어 삭제하기로 한 기능을 다른 멤버들이 구현해버리는 사례가 일어나기도 했습니다.
문제 해결을 위해 삭제할 기능도 위키에 기록하고, Perl 코드에 주석을 작성했습니다.

세 번째로 Kotlin 엔지니어가 Perl 코드를 이해할 때 어려웠던 점을 말씀드리겠습니다.
시간과 인력 문제로 사양이 모두 문서화 되어 있지 않았기 때문에, Kotlin 엔지니어가 Perl 코드를 읽어서 이해해야 했습니다.
이것은 어느 프로덕트에서도 있을 수 있는 상황으로, 시간을 들여 해결해 나가야 할 과제입니다.

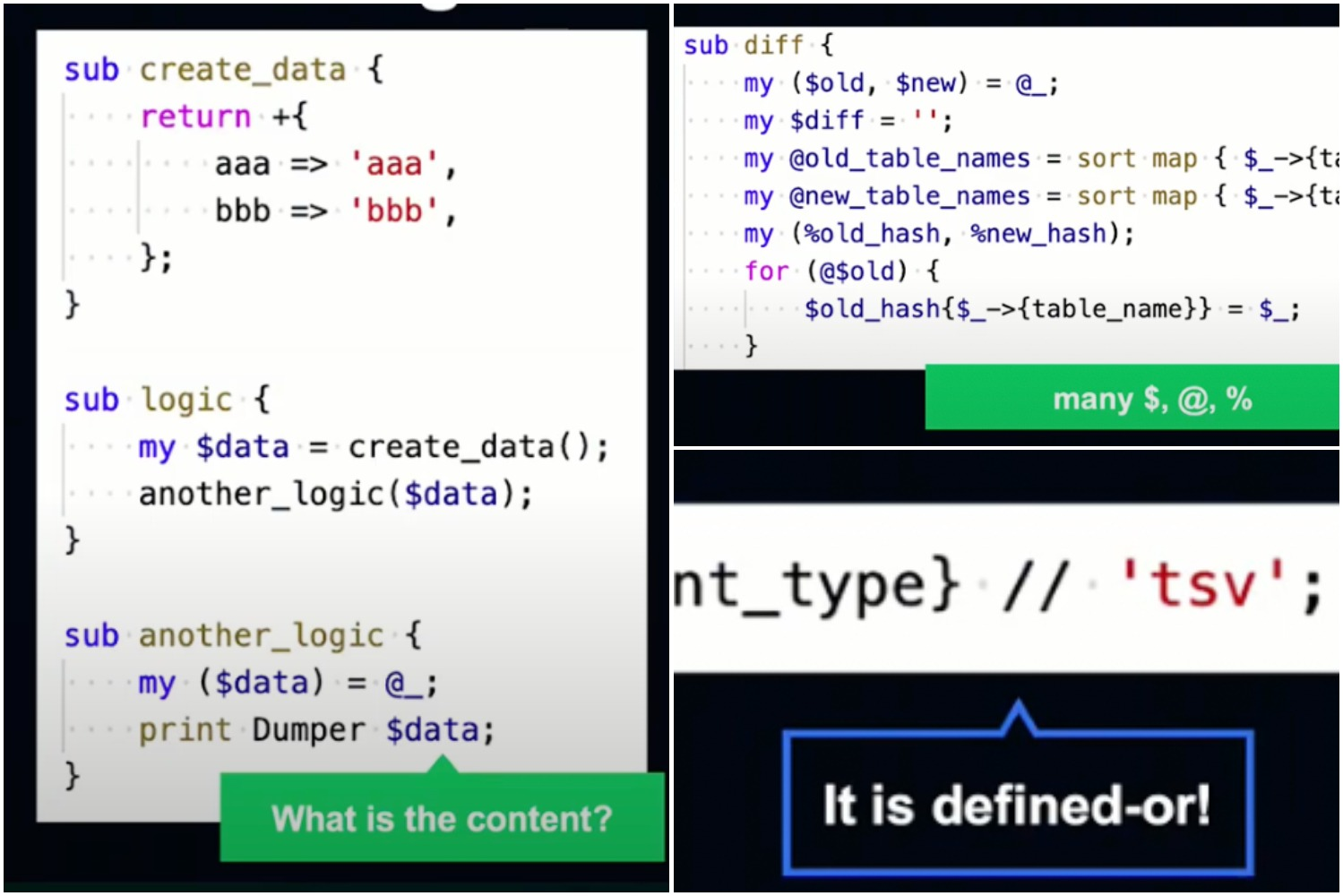
//를 연산자로 사용하는 Defiend-or 연산자, $ @ % 등의 기호, 알기 힘든 HashRef 내용 등이 특히 읽기 힘들었습니다.

마지막으로 Perl 엔지니어가 Spring Boot & Kotlin을 배울 때 어려웠던 점에 대해서 말씀드리겠습니다.
Kotlin보다는 Spring Boot를 익히는 데 시간이 걸렸습니다.
Perl과는 Import 방식이 달랐고, DI, Component Scan, Bean 등의 Spring 지식을 익힐 필요가 있었습니다.
Reflections that came to light

지금부터는 프로젝트 후반에 느낀 반성할 점에 대해서 말씀드리겠습니다.

첫 번째 반성할 점은 Nullable을 너무 많이 사용했다는 것입니다.

Perl의 변수는 기본적으로 Kotlin의 Nullable과 같습니다.
Perl의 변수는 undef(null) 될 수 있고, 그렇기에 항상 null check를 해야 했습니다.
이번 프로젝트에서는 로직을 맞추어 Kotlin에 이식했기 때문에, Perl-Kotlin 변경 시 변수를 Nullable로 작업한 경우가 많았습니다.
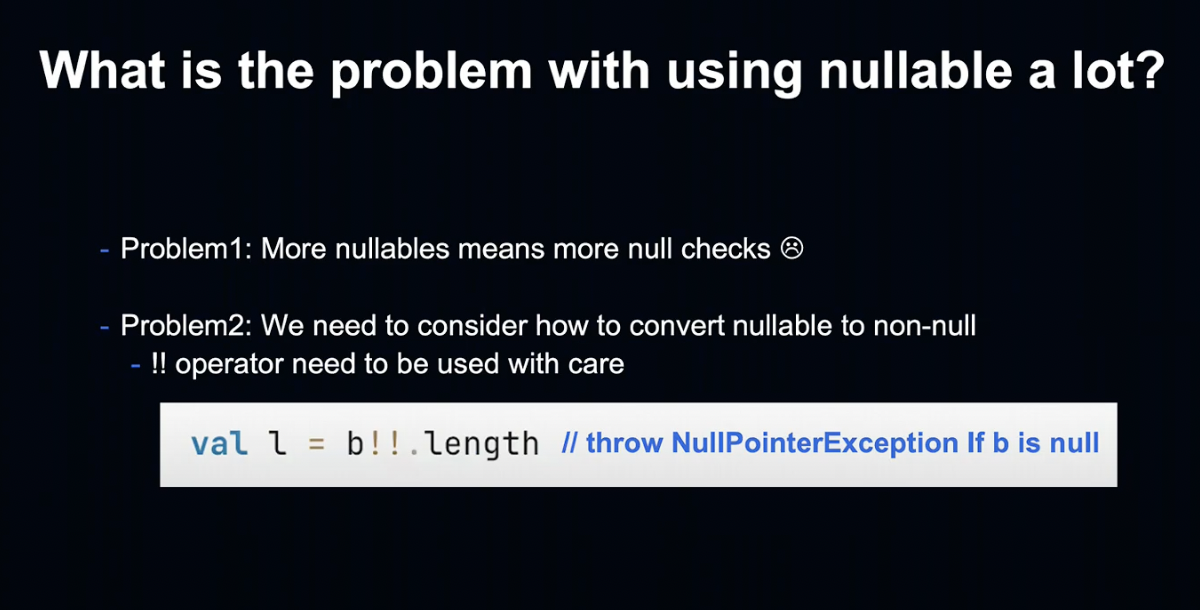
Nullable이 많아지면 Null check도 필연적으로 많아지게 되는데, 한번 null check한 변수를 여러 번 확인하는 것은 불필요한 행위입니다.
또한 Nullable을 Nonnull로 변환하는 경우도 생각해야 합니다.
예를 들어 !!(Non Null Assertion) 연산자를 사용하는 경우 별도의 준비가 필요하게 됩니다.

그렇다면 어떠한 방법을 사용하는 것이 좋을까요?
우선 가능한 한 non-null을 사용하는 것이 필요합니다.
Controller에서 null을 체크하고, 서비스 층에서는 non-null로 전달해 nullable의 범위를 좁힙니다.
또한 non-null assertions 연산자 사용 시 NPE 가능성을 고려해 구현해야 합니다.
단점도 있었지만 nullable 덕분에 Perl-Kotlin 이관을 쉽게 할 수 있었습니다.

두 번째 반성할 점은 비슷한 의미의 변수 취급입니다.

우리의 프로덕트에는 Digest라는 여러 의미를 가진 변수가 있습니다.
Digest는 사용자와 캠페인 별로 발행되는 일종의 토큰인데, Limited Digest, Unlimited Digest, LINE Digest등 여러 종류가 있습니다.
프로젝트 초기에는 이 Digest들을 모두 String 형으로 다뤘는데, 그 결과 개발 시 이 코드의 Digest는 무엇인지 혼란스러워졌습니다.

이 혼란에 대처하기 위해서 우리는 Typealias를 사용하기 시작했습니다.
이는 String에 대한 일종의 별명으로, Typealias 사용 전인 왼쪽과 비교해 오른쪽이 훨씬 읽기 편한 코드가 되었습니다.
그러나 Typealias는 어디까지나 별명으로, 원 타입은 String이기 때문에 문자열이면 전부 입력되었습니다.

앞으로는 inline 클래스로 바꿔나갈 예정입니다.

세 번째는 반성할 점은 설계 문제로, 비즈니스 로직이 바깥 세상에 관해 알고 있다는 것입니다.

먼저 문제 상황에 대해서 말씀드리겠습니다.
일부 비즈니스 로직이 io grpc 패키지의 StatusRuntimeException을 던졌습니다.
즉, 비즈니스 로직이 바깥 세상과 어떻게 통신하고 있는지 알고 있는 상황이었습니다.

그 결과 문제가 발생했습니다.
어떤 로직을 다른 애플리케이션에서도 쓰고 싶다는 흔히 있는 상황이 발생했습니다.
해당 애플리케이션은 gRPC를 사용하지 않는 어플리케이션입니다. 그 어플리케이션에서도 StatusRuntimeException만을 위해서 io gRPC를 의존성 추가해야 하는 상황이 발생한 것입니다.
공통 로직에서는 해당 예외가 발생하지 않도록 해야 했는데, 비즈니스 로직의 공통 부분을 분리하기가 매우 어려워진 상황이었습니다.

그렇다면 왜 이 같은 상황에 빠지게 되었을까요?
프로젝트 초기에는 어떻게든 정상 동작만 되도록 코딩했고, 예외와 의존성에 대해 충분히 생각하지 못했습니다.
결국 이러한 기능 공통화 작업에서 문제가 생기게 되었습니다.

이번 케이스에서는 StatusRuntimeException을 공통 사용 로직에서는 사용하지 말았어야 하고, 통신 계층을 확실히 나눠야 했습니다.
비즈니스 로직은 바깥 세상을 모르는 상태로 만드는 것이 좋다는 것을 재확인한 사례였습니다.
Difficulties related to release
지금부터 릴리즈에 관한 어려움에 대해 말씀드리겠습니다.

첫 번째로 현행 Perl 시스템을 고려한 Real QA(운영 환경의 QA)의 어려움이 있었습니다.
모든 데이터를 새로운 데이터베이스로 이관한다면 현행 시스템을 생각할 필요가 없어서 편했겠지만, 이번에는 현행 시스템의 데이터베이스를 그대로 선택했기 때문에 발생한 문제입니다.
두 가지를 주의하며 Real QA를 진행했습니다.
먼저 현행 시스템과 비 호환 데이터가 발생하지 않도록 유의했습니다.
데이터 환경에서 Perl과 Kotlin을 대략 한달 반 정도 병행했고, 이 기간에 많은 문제에 대해 깨닫게 되었습니다. 충분히 긴 기간을 잡는 것이 좋을 것 같습니다.
또한 현행 시스템 외의 애플리케이션을 추가할 때 MySQL 접속 수의 문제 등이 없는지 꼼꼼하게 확인했습니다.

두 번째 어려웠던 점은 아직 Perl로 운영되는 부분의 개발이었습니다.
전체 시스템을 한꺼번에 교체하면 좋겠지만, 모든 것을 다 바꾸려면 3~4달이 필요했기 때문에 현실적으로 어려웠습니다.
부분적으로 릴리즈하여 다른 요건에 대응하기 위한 노력이 필요했습니다.
Perl에 무엇을 남기고, 어떻게 수정할지를 검토하는 것에 집중해야 했습니다.
Benefits of rewriting

마지막으로 재작성의 장점에 대해서 말씀드리겠습니다.

네 가지 장점이 있었습니다.
첫 번째로 사용되지 않는 기능을 모두 없앴습니다.
두 번째로 프로젝트 개발에 참여하지 않은 엔지니어들이 참여함으로서 사양을 공유하고, 의식적 문서화를 통해 누구나 알 수 있게 문서화했습니다.
세 번째로 당사 개발 조직에서 자주 사용되는 Kotlin으로 이관함으로서 경험을 공유하고, 리뷰를 활성화하여 개발 자원의 유동성을 높였습니다.
마지막으로 다른 언어로 재작성할 때 현대적인 아키텍처 및 기술을 사용하여 개발자 스킬이 업데이트 되었습니다.
결론

오늘은 LINE Point Club의 8년간 사용하던 언어를 Kotlin으로 이관한 사례에 대해 알아보았습니다.
오랫동안 서비스를 운영하다 보면 반드시 복잡해지기 마련입니다. 복잡해진 서비스는 유지가 어려워지고, 변경이 필요해질 때가 오기 마련입니다.
오늘은 언어를 변경할 때의 어려움과 해결책의 일부를 소개했습니다. 그리고 언어 변경에 따른 이득과, 시사점에 대해서 배울 수 있었습니다.
여러분의 프로덕트에서도 가까운 미래, 수년 후를 내다보고 필요없는 기능의 제거나 코드 리뷰 문서화를 진행해 주시기 바랍니다.
이상으로 발표를 마치겠습니다. 시청해주셔서 감사합니다.
Redis Pub/Sub을 사용해 대규모 사용자에게 고속으로 설정 정보를 배포한 사례 - Kazuya Horiuchi

본 세션의 발표를 맡게 된 개발 센터의 Horiuchi입니다.
여러분은 대규모 업데이트나 신규 기능 출시 시 제대로 작동하는지, 혹시 장애가 나지 않을 지 걱정하신 적이 있으신가요?
LINE도 마찬가지로 하루에 수백 번 노드를 확인하거나 매트릭스를 지켜봅니다. 단순한 개발 에러 외에도 인프라, 네트워크 장애도 굉장히 신경쓰입니다.
이와 같은 장애는 돌발적으로 발생하기 때문에 깜짝 놀라곤 하지만, 어느 정도 장애를 예측해 시스템을 구축한다면 자동 복구할 수 있어 안심할 수 있습니다.
오늘은 LINE이 어떻게 이러한 장애를 예측해 시스템을 구축했는지 알아보도록 하겠습니다.
Agenda

본 세션의 Agenda는 다음과 같습니다.
- LINE LIVE가 무엇인지
- LINE LIVE Chat 시스템 개요
- 설정 동기화와 전송
- 기존 아키텍처와 새로운 아키텍처
- 신규 아키텍처의 Use-case
- 새로운 아키텍처 구축 시 장애 대처
- 운영 결과
LINE LIVE

먼저 LINE LIVE에 대해 설명드리겠습니다.
LINE LIVE는 모두가 자유롭게 실시간 방송을 할 수 있는 라이브 스트리밍 서비스입니다.
팬들은 방송을 시청하고, 아이템과 하트로 방송자를 응원하고, 실시간 코멘트 기능으로 실시간 대화를 할 수 있습니다.
순간 순간이 중요한 서비스로서, Real Time 서비스가 무엇보다 중요한 서비스라고 할 수 있습니다.
만약 장애가 발생하거나 운영 중 실수가 발생한다면 예정된 라이브가 전부 실패하는 큰 사고로 이어지기 때문에, LINE은 실시간 커뮤니케이션을 안정적으로 즐길 수 있도록 힘쓰고 있습니다.

오늘은 이 코멘트 기능에 초점을 맞추고, 고품질 실시간성을 실현하기 위한 새로운 시스템에 대해 말씀드리겠습니다.
LINE LIVE Chat System
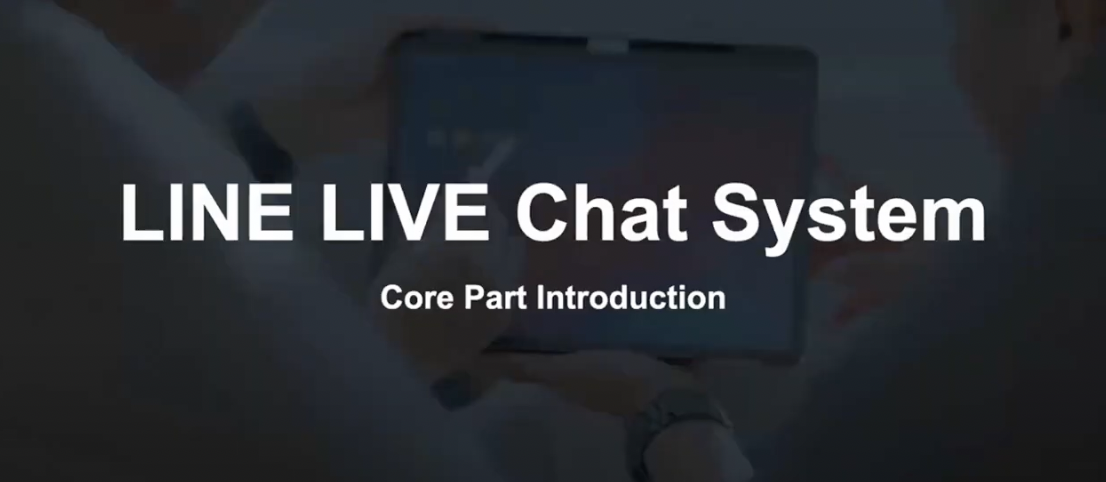
LINE LIVE 채팅 시스템에 대해 알아보기 위해 우선 Core 부분부터 설명하겠습니다.
채팅 서버는 Akka를 사용해 병렬 처리를 실현합니다.
위 그림에서 Akka Actor에 포함된 ChatSupervisor, ChatRoomActor, UserActor가 이에 해당합니다.
클라이언트-서버 간 통신은 웹소켓을 사용합니다.
클라이언트가 메세지 핸들러로 전송한 코멘트는 서버의 UserActor에서 다른 클라이언트로 전송됩니다.
현재 LINE LIVE 채팅의 서버는 120대로, 각 서버 간에 유저 코멘트를 공유할 필요가 있습니다.
코멘트 공유는 Redis의 Publish서버를 사용해 실현하고 있습니다.
채팅 서버는 Redis를 사용해 Publish & Subscribe를 사용합니다.
Publisher는 전송된 코멘트를 공유와 동시에 Redis에 일시적으로 저장하고, 저장된 코멘트는 뒷단에서 배치 처리를 통해 MySQL에 적재합니다.
LIVE Chat 시스템에서는 유저가 설정을 사용해 코멘트를 제어하기도 하는데, 이 설정 정보를 120대의 채팅 서버 간에 어떻게 동기화 & 반영하는지가 오늘의 주제입니다.
Legacy Architecture

오늘의 주제를 설명드리기 전에, 먼저 지금까지 사용해 온 기존 시스템에 대해 알아보겠습니다.
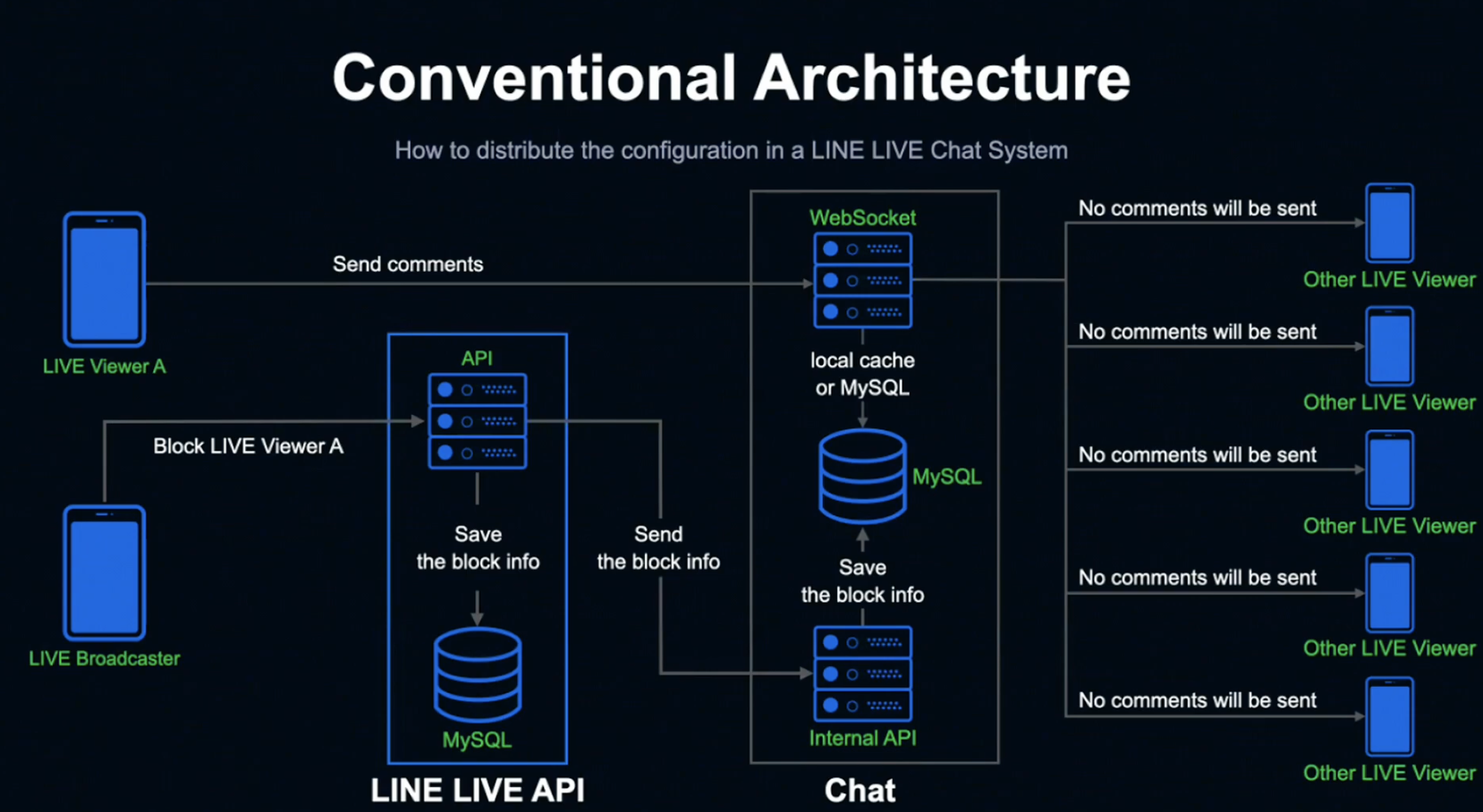
한 가지 유스케이스로 예를 들어 보겠습니다.
LINE LIVE에는 방송자가 시청자를 차단하면 해당 유저의 코멘트가 방송에 표시되지 않도록 하는 기능이 있습니다.
방송자가 시청자를 차단하면 LINE LIVE API에 차단 정보가 전송됩니다. 해당 차단 정보는 LINE LIVE MySQL에 저장되고 Chat Internal API 서버에 전송됩니다.
정보를 받은 Chat Internal API 서버는 MySQL에 차단 정보를 저장하고, 그 후 해당 시청자가 코멘트를 보내면 Chat WebSocket 서버는 로컬 캐시와 MySQL에서 차단 정보를 확인해 코멘트를 차단합니다.
기존 기능에서는 이 정도의 성능으로도 충분했고, 설정 반영 타이밍도 엄수할 필요가 없어 기한부 로컬 메모리를 사용해 기한이 만료되면 새로운 정보로 교체하는 식으로 개별적으로 정보를 취득했습니다.
Why do we need a new architecture?

그렇다면 기존에 잘 작동하던 시스템을 왜 새로운 시스템으로 변경했을까요?
우선 문제가 되었던 기능을 소개해 드리겠습니다.

LINE LIVE에서는 최근 코멘트를 꾸밀 수 있는 채팅 데코레이션 기능을 출시했습니다.
데코레이션 설정은 유저가 자유롭게 변경할 수 있고, 변경 내용은 실시간으로 반영됩니다.
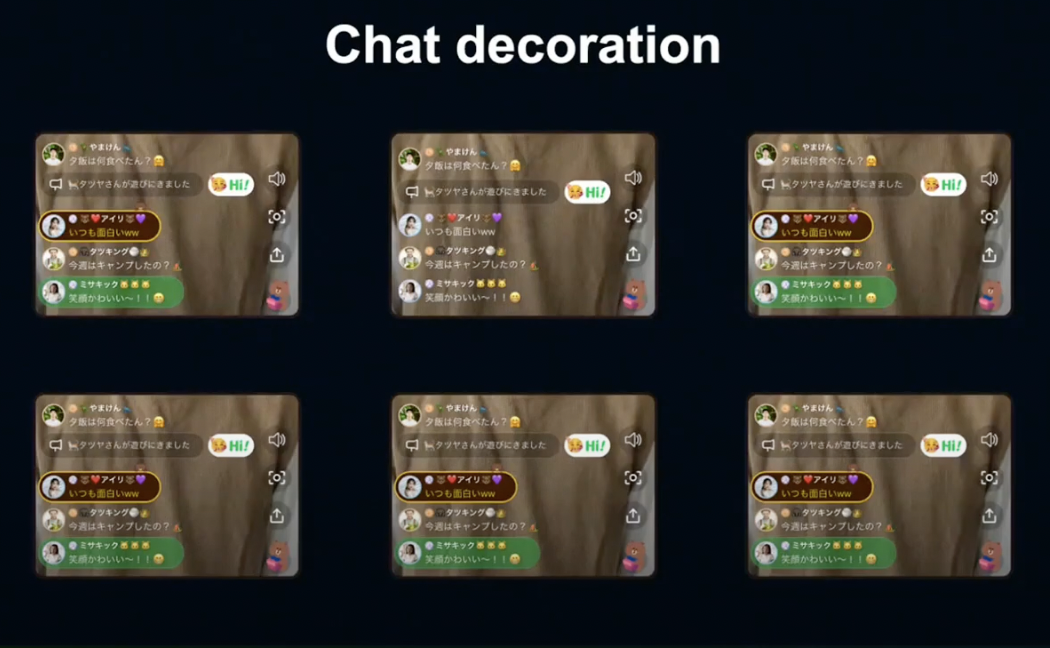
LINE이 실시간성, 동시성을 고집하는 이유는 위 화면처럼 혼자만 꾸며지지 않은 코멘트가 표시되는 나쁜 경험을 방지하기 위함입니다.
저희는 이런 나쁜 경험을 막기 위해 Redis Pub/Sub를 사용한 새로운 동기화 시스템을 만들기로 결정했습니다.
지금부터 새로운 시스템에 대해 설명드리겠습니다.
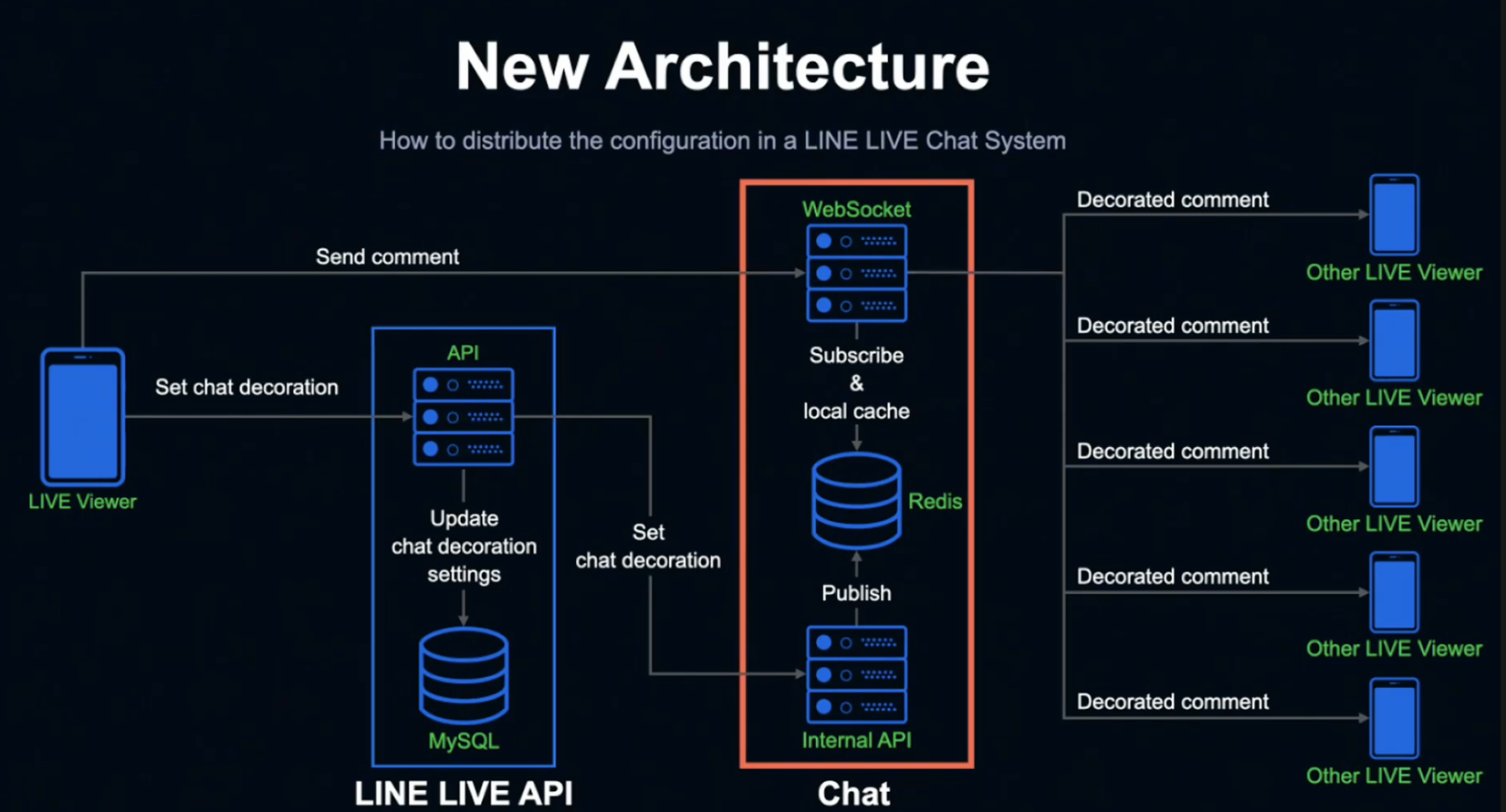
시청자가 데코레이션을 설정하면 LINE LIVE API 서버에 요청이 전송되고, LINE LIVE MySQL에 설정이 저장됩니다.
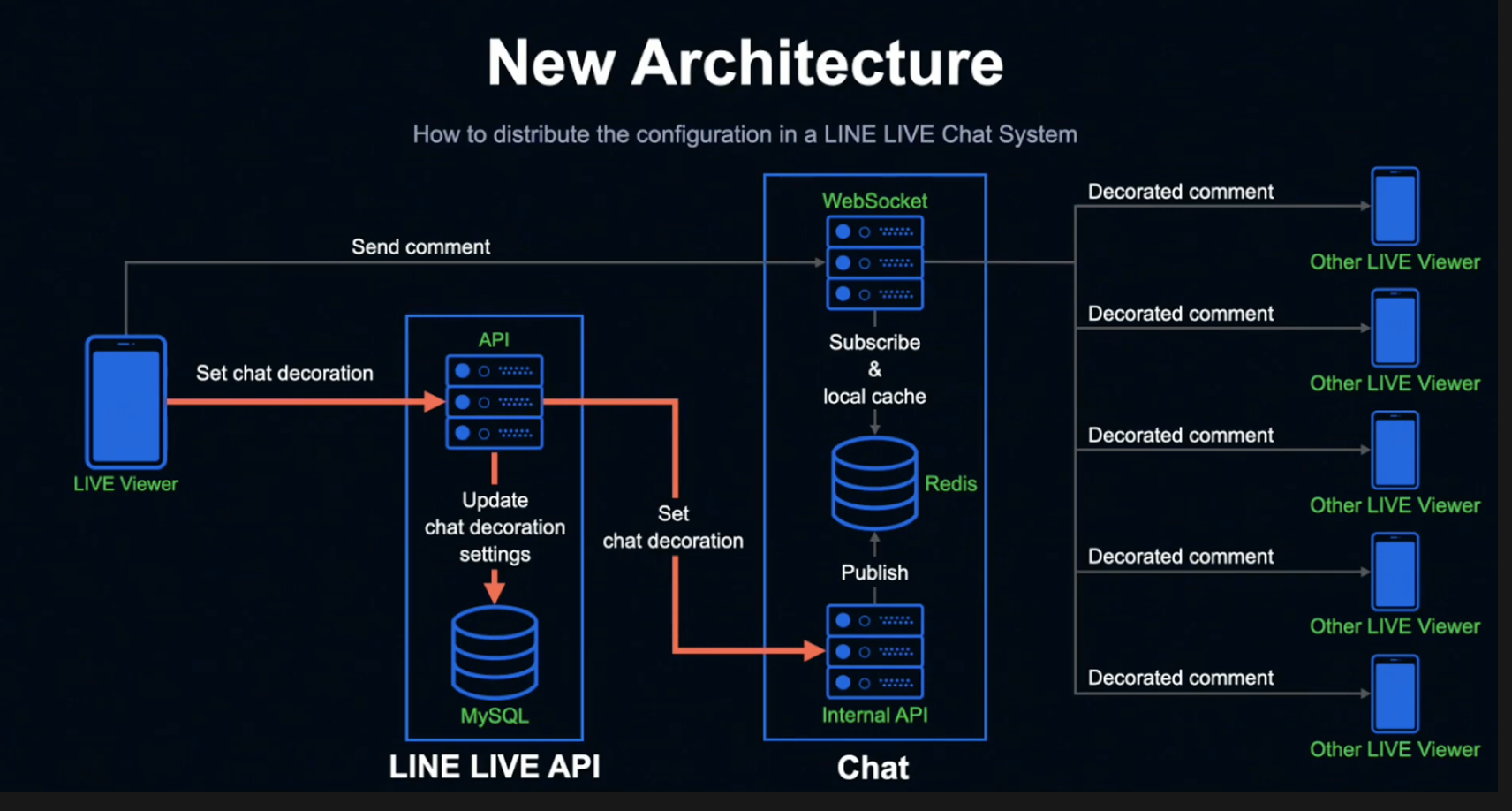
또한 Internal API 서버에 설정 정보를 넘겨주게 됩니다. 여기까지는 기존과 동일한 방식입니다.
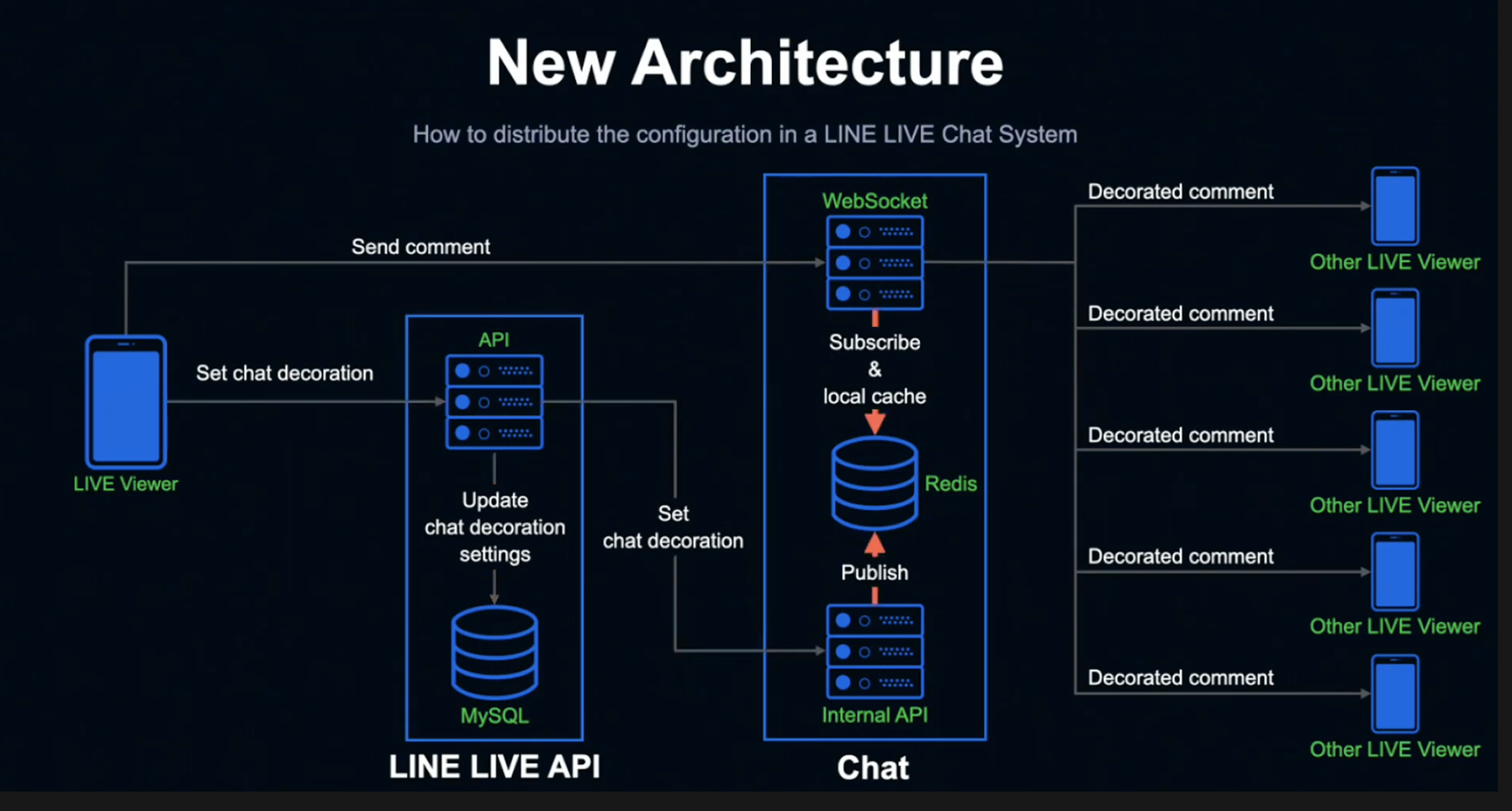
설정을 받은 Chat의 Internal API 서버는 Redis에 Publish 하고, Listen 상태인 Chat WebSocket 서버는 Publish된 정보를 Subscribe해 로컬 메모리에 캐싱합니다.
이때 Subscribe 처리는 전체 WebSocket 서버에서 동시에 진행되기 때문에, 결과적으로 동일한 타이밍에 전체 서버에 설정이 반영되게 됩니다.
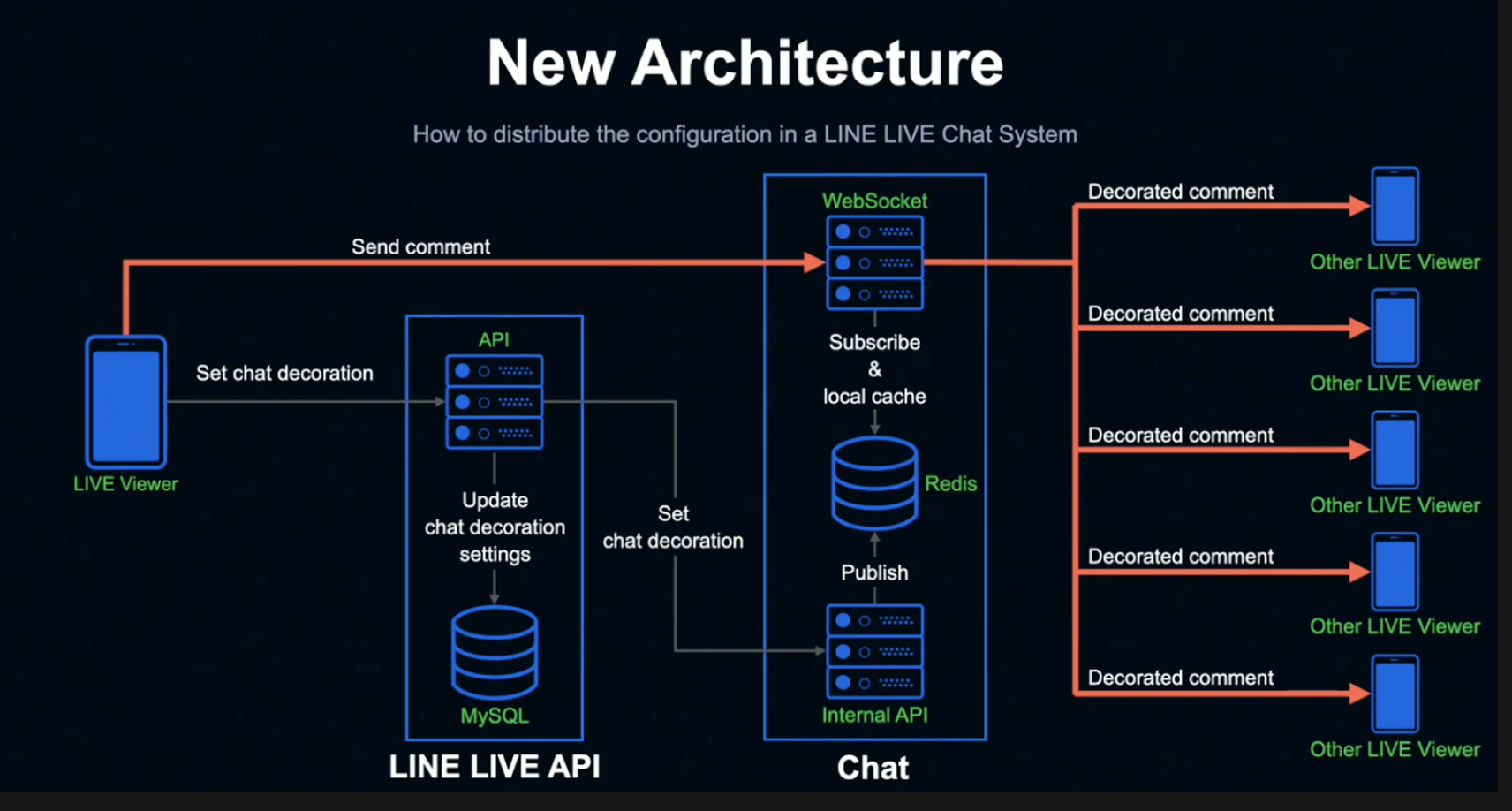
설정을 마친 시청자가 코멘트를 전송하면 Chat의 WebSocket 서버는 로컬 메모리 캐시에 저장된 설정을 참조하기만 하면 다른 시청자에게 데코레이션 정보가 반영된 코멘트를 전송할 수 있게 됩니다.
현재 LINE LIVE의 Chat WebSocket 서버는 120대가 운영되고 있지만, Redis Pub/Sub 기능을 사용해 시청자가 어떤 WebSocket 서버에 접속되어 있든 똑같이 코멘트를 표시할 수 있습니다.
Diversion of new architecture

신규 시스템은 범용적으로 사용할 수 있게 구축되었는데, 지금부터 이 시스템을 사용해 어떤 일을 할 수 있었는지 알아보겠습니다.
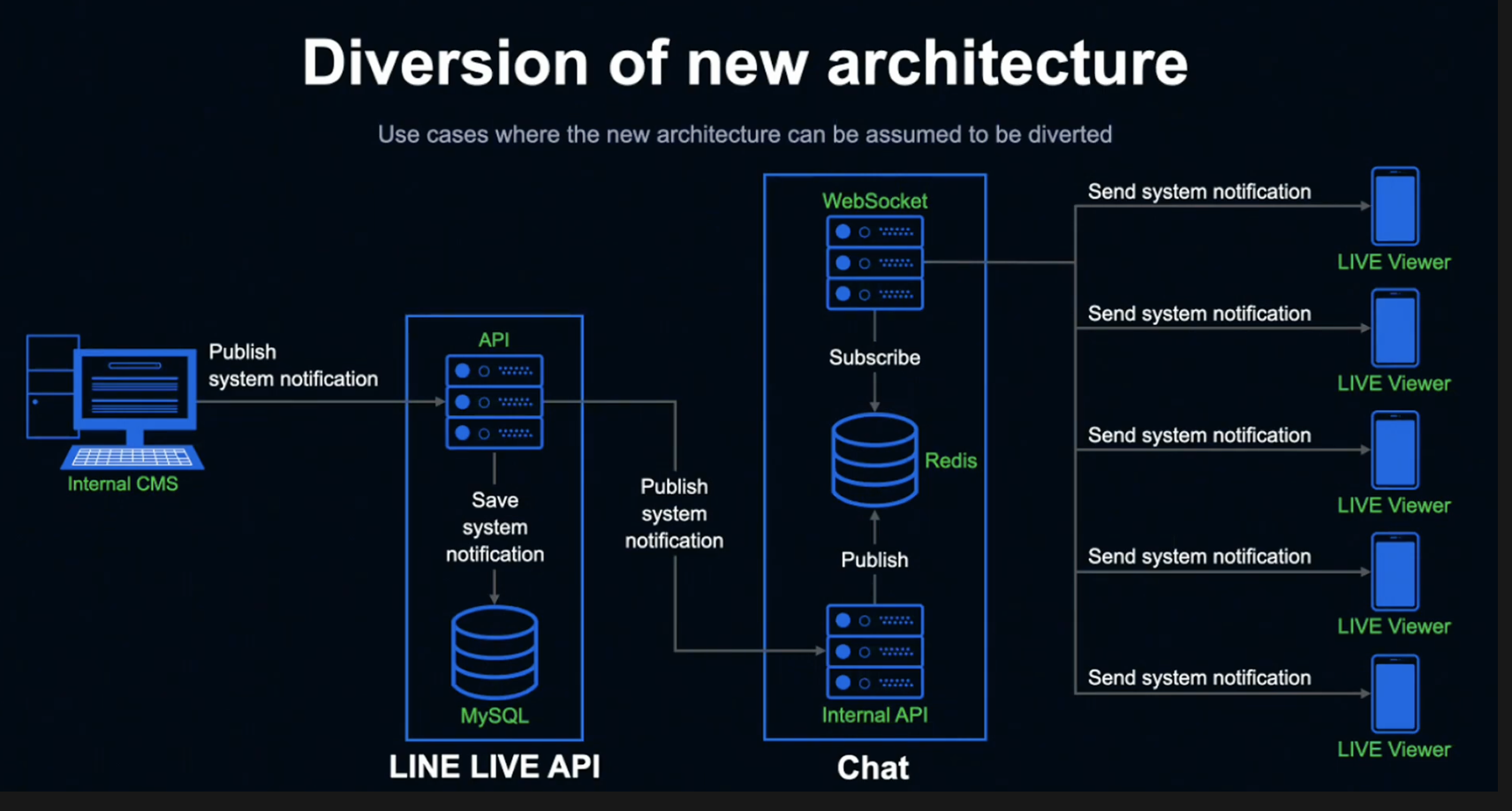
위 그림은 LINE LIVE가 현재 방송을 시청 중인 모든 시청자에게 알림을 동시에 전송하는 상황을 가정한 유스케이스입니다.
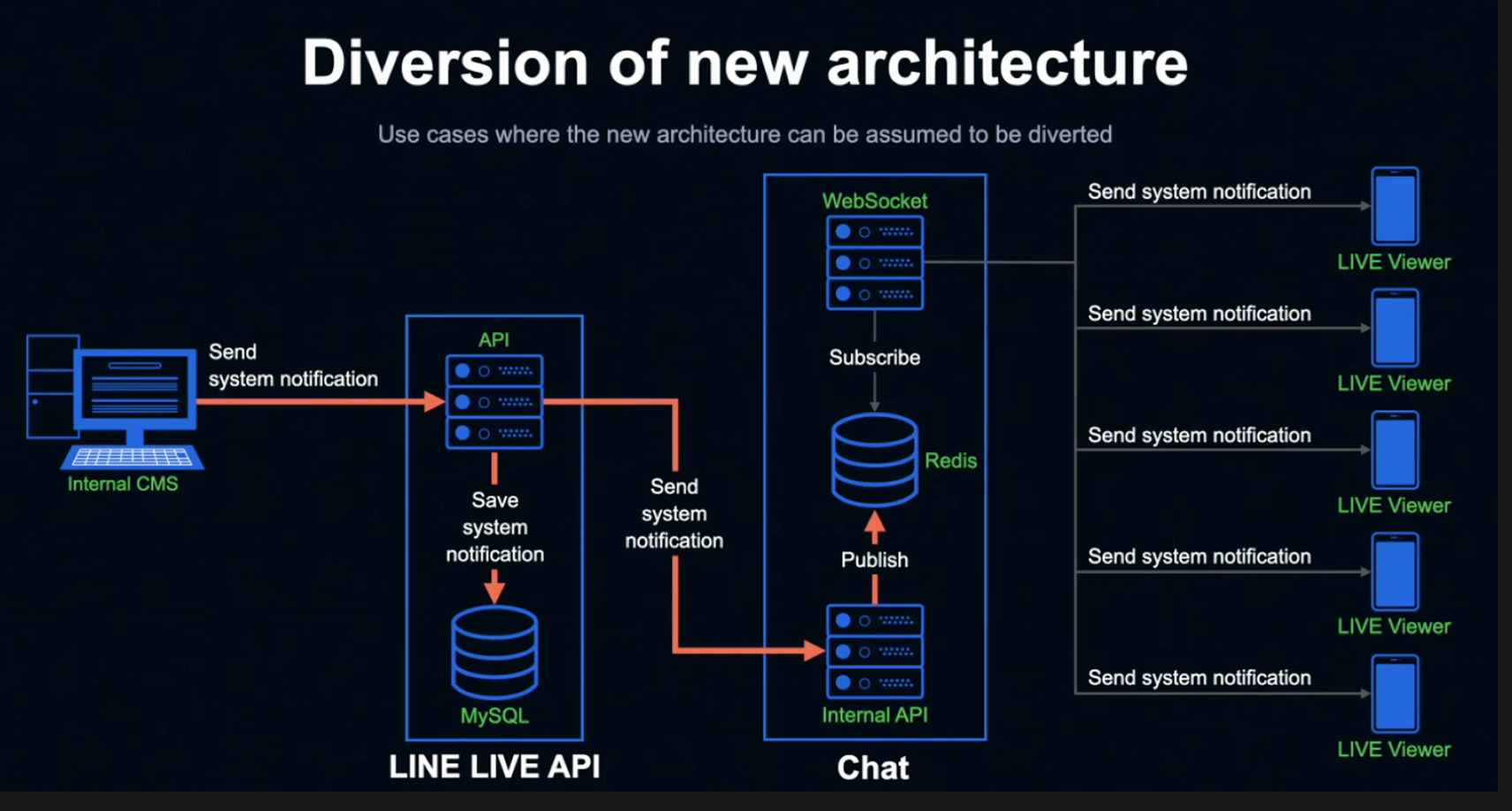
내부 Internal CMS를 통해 알리고 싶은 정보를 Submit해 LINE LIVE API에 전송합니다.
정보를 받은 API 서버는 MySQL에 알림 정보를 저장하고 Chat Internal API 서버에 알림 정보를 전달하고, 정보를 받은 Chat Internal API 서버는 Redis에 Publish합니다.
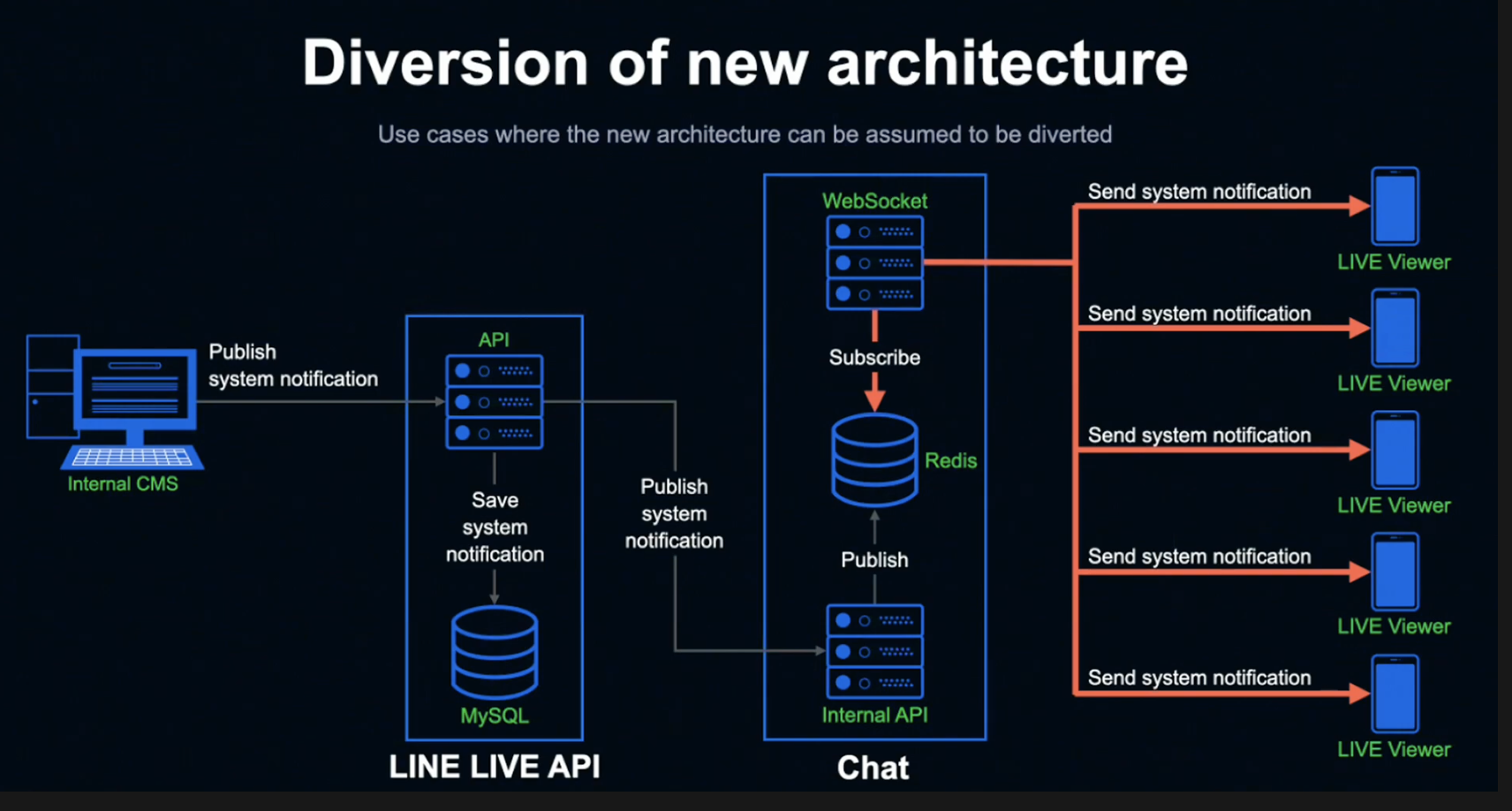
Listen 상태인 Chat의 WebSocket 서버는 Publish된 알림 정보를 취득해 현재 방송을 시청하고 있는 모든 시청자를 대상으로 알림 정보를 전송합니다.
신규 시스템을 사용해 알림 정보를 보냄으로서 거의 지연 없이 시청자 전부에게 동시에 알림을 전송할 수 있습니다.
이 기능을 활용하여 선착순 선물 등의 다양한 기능을 만들 수 있어 서비스 기획을 크게 확대할 수 있습니다.
For even safer operation

이상으로 신규 동기화 시스템의 설명을 마치겠습니다.
한 가지 더, Redis Pub/Sub를 사용해 구현한 내장애성 향상 시스템에 대해 소개하고 싶습니다.
인프라/네트워크 장애는 돌발적으로 발생합니다. 하지만 어느 정도 장애를 예측해 시스템을 구축할 수 있다면 자동 복구가 가능해지고 안심할 수 있는 시스템을 만들 수 있습니다.
그래서 저희는 Subscribe 연결에 이상이 탐지되면 자동으로 복구하는 시스템을 만들었습니다.
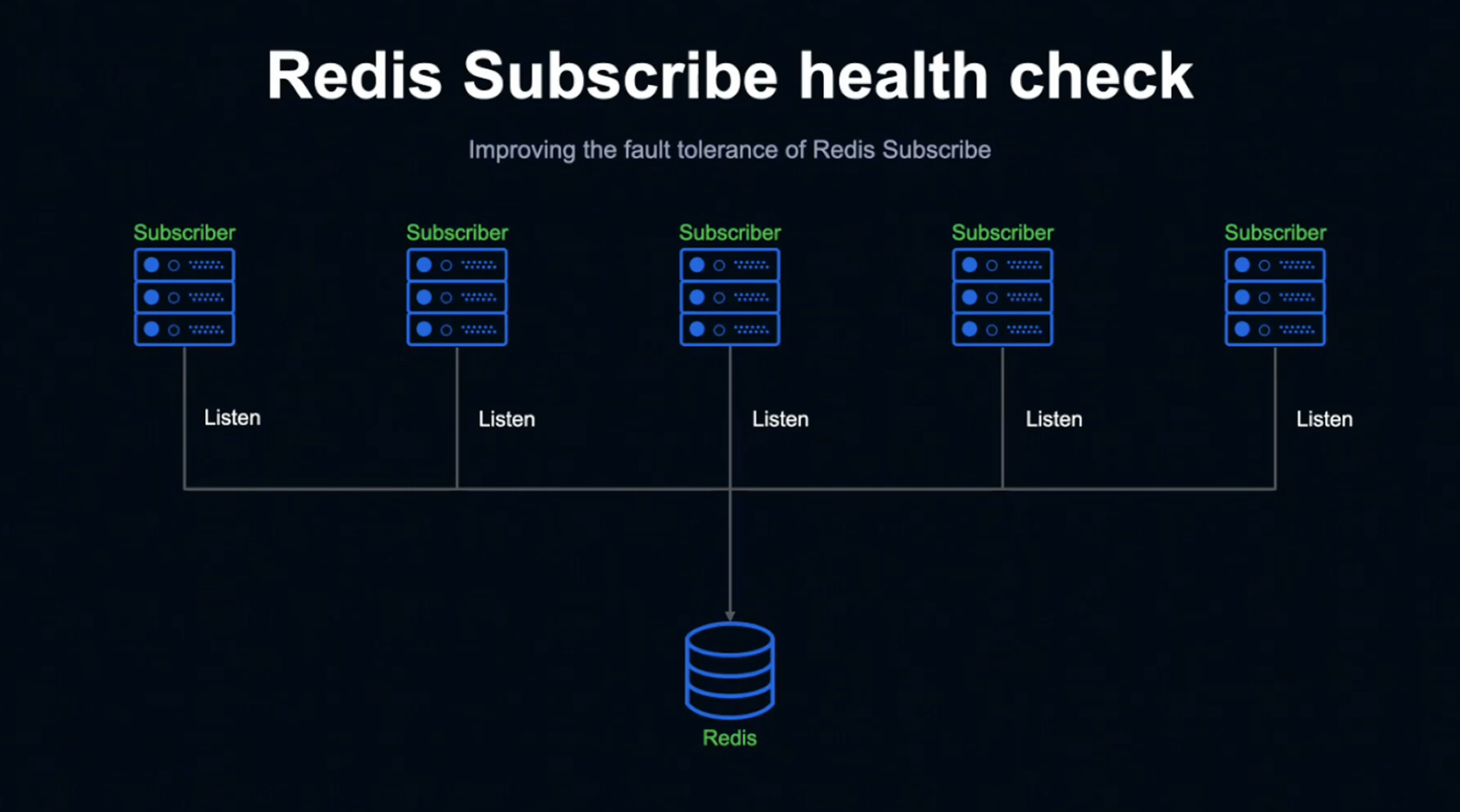
이 그림은 Redis에 여러 Subscriber가 Listen 중인 상태를 가정한 그림입니다.
LINE LIVE Chat 시스템의 WebSocket 서버가 Redis를 Listen 중인 상태와 동일합니다.
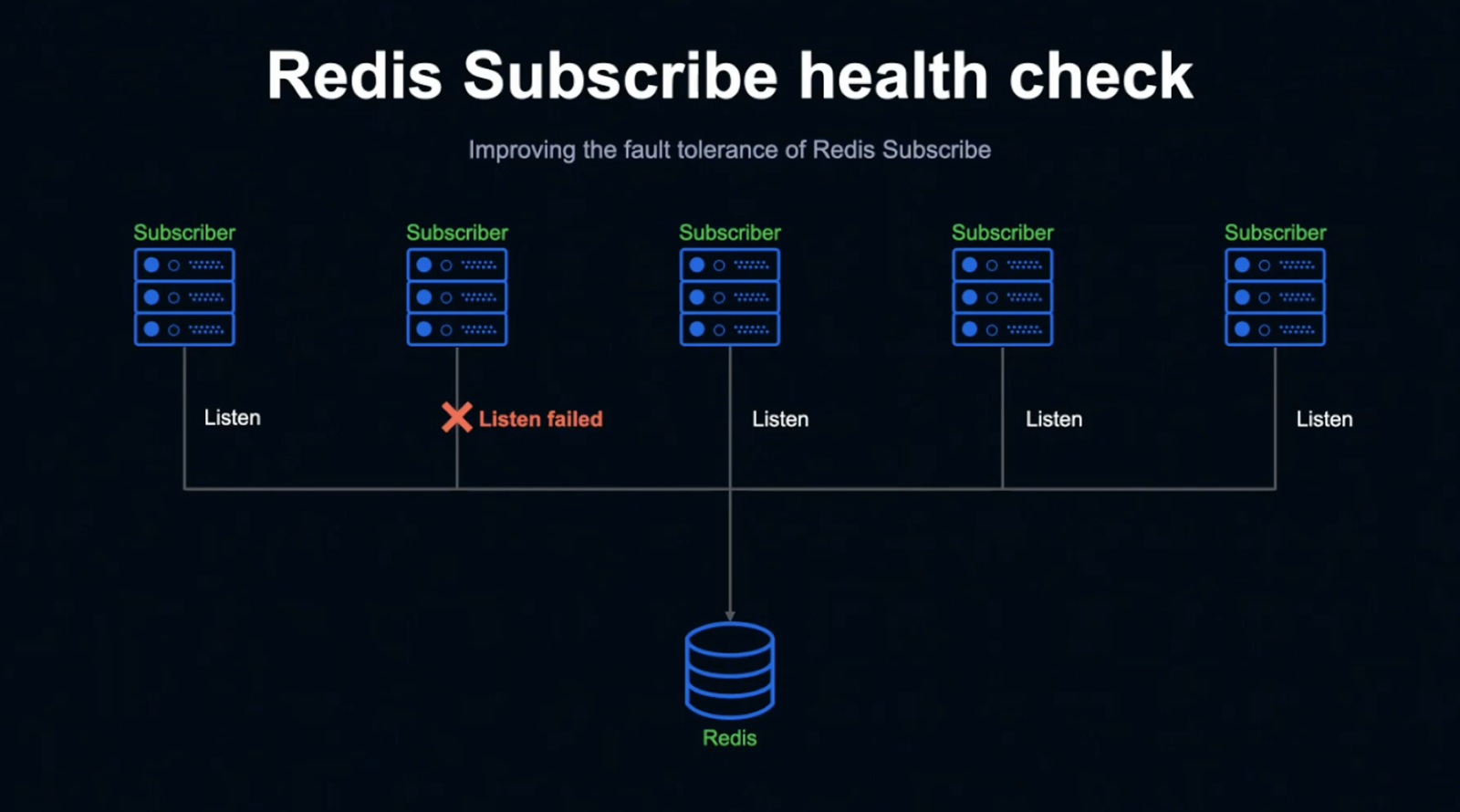
이때 두 번째 Subscriber의 커넥션이 어떤 이유로 Listen 상태지만 Publish 정보를 취득하지 못하는 Fail 상태가 되었다고 가정해 보겠습니다.
대규모 장애는 아니더라도 서버 하나 정도의 네트워크 장애나 불안정한 상태가 발생할 가능성은 충분히 있기 때문에 이런 상황을 미리 고려해 두는 것이 좋습니다.
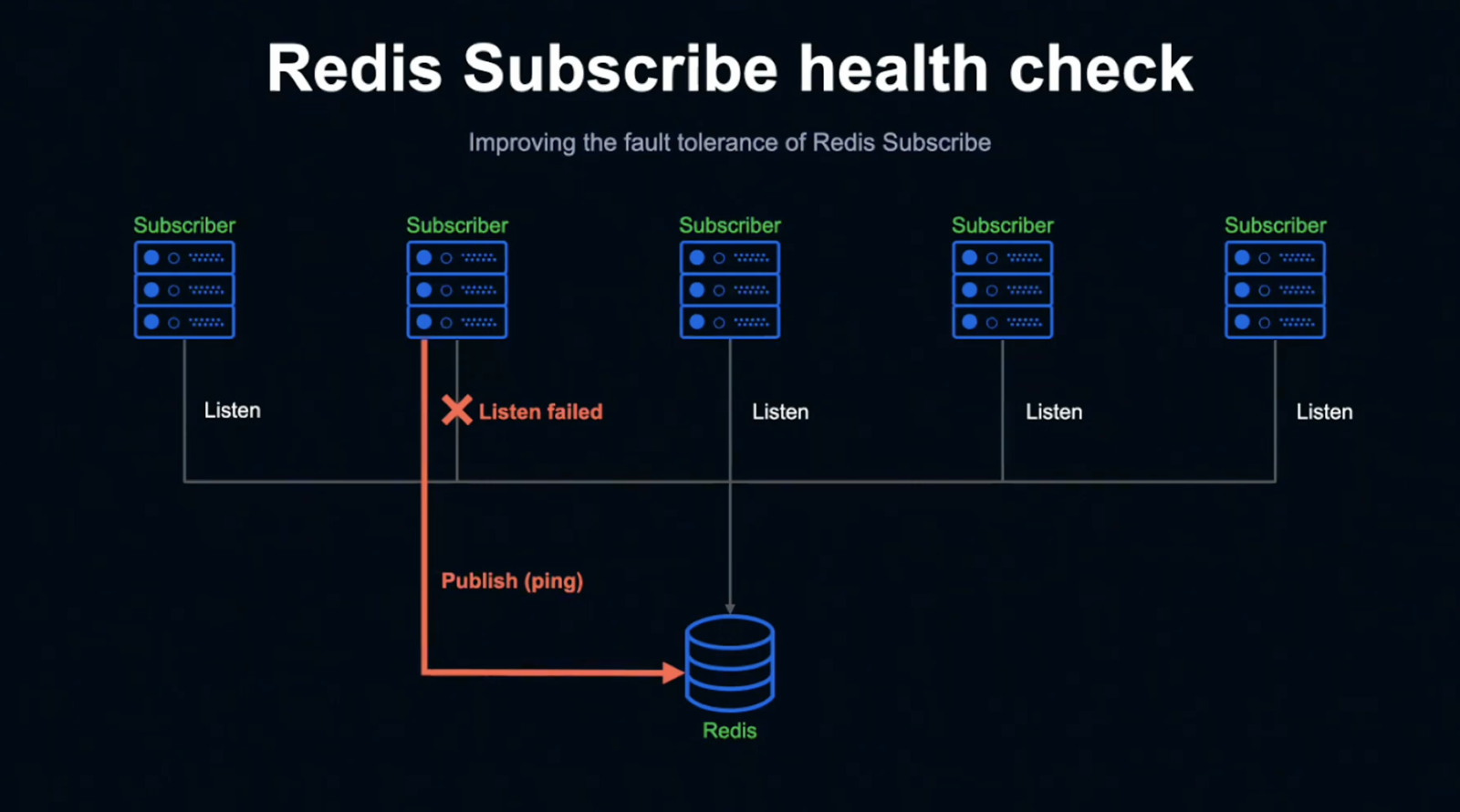
Subscriber는 일정 시간 동안 Subscribe하지 못하는 상태가 되는데, 그럴 경우 직접 Ping을 보내게 됩니다.
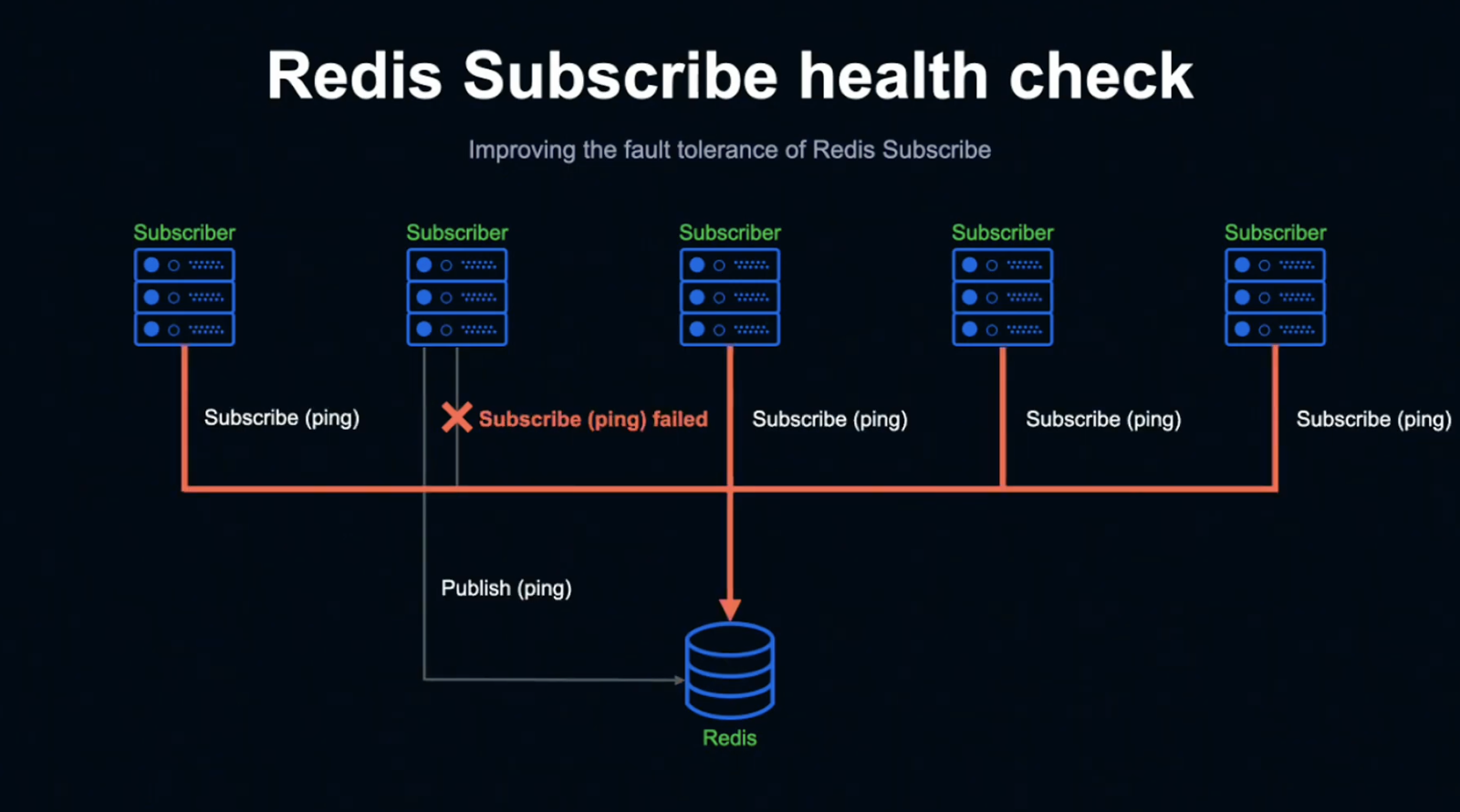
정상적으로 Listen하고 있다면 해당 Ping을 Subscribe할 수 있지만, Fail 상태인 Subscriber는 Subscribe가 불가능합니다.
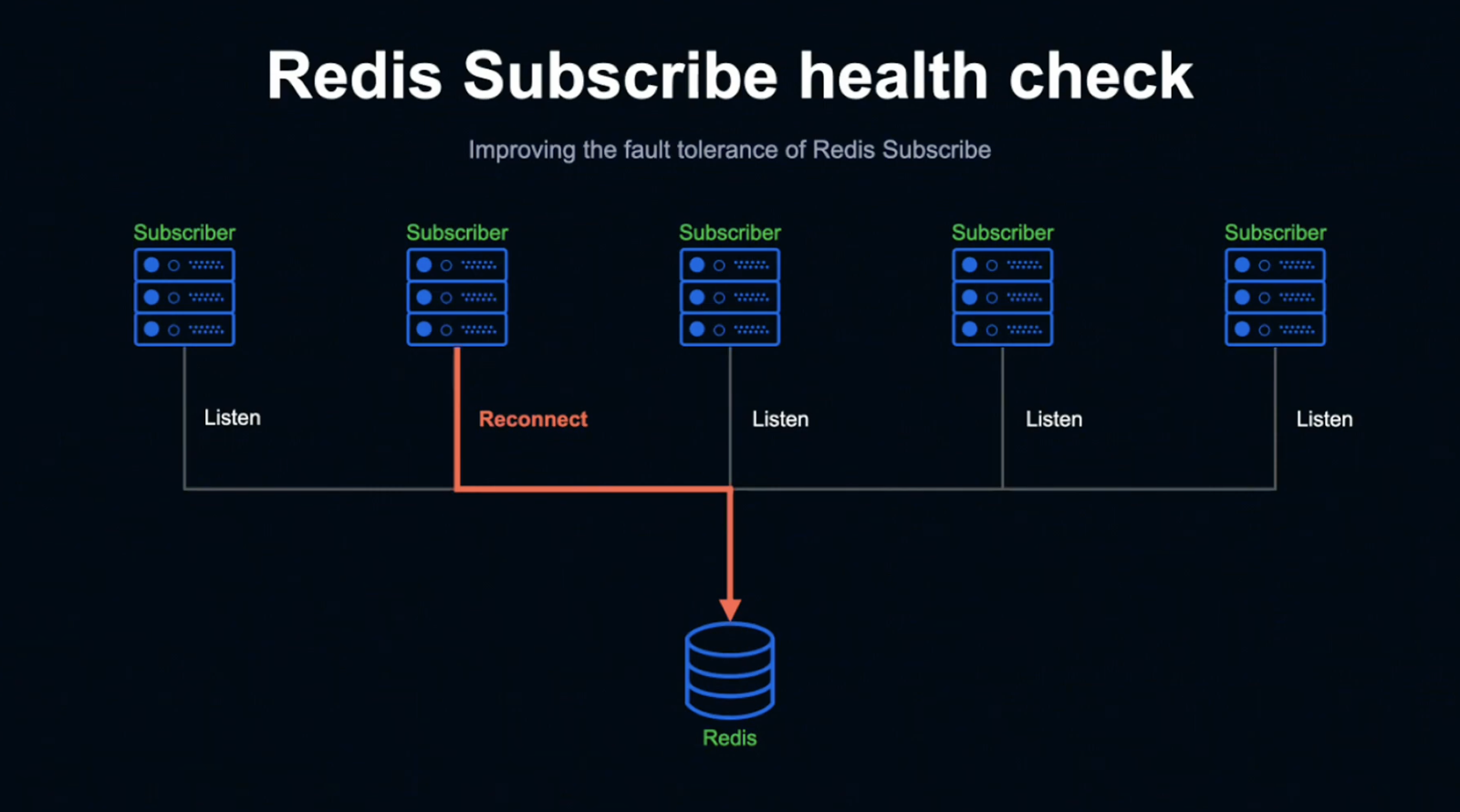
직접 Ping을 전송한 상태에서 Subscribe을 할 수 없는 것이 탐지되면 재접속해 정상적인 Listen 상태로 되돌아가 자동으로 복구됩니다.
이상으로 자동 복구의 설명을 마치겠습니다.
결론

오늘 제가 준비한 내용은 여기까지입니다.
마지막으로 새로운 시스템을 구현한 결과에 대해 공유하고자 합니다.
신규 기능은 좋은 유저 반응을 얻어냈고, 지금까지 대규모 장애 없이 운영되고 있습니다.
또한 이 시스템을 이용하여 언제든 새로운 기능을 구현할 준비가 되어 있습니다.
많은 분들이 참고해 주시면 감사하겠습니다.
이상 발표를 마치겠습니다. 경청해 주셔서 감사합니다.
대규모 음악 데이터 검색 기능을 위한 Elasticsearch 구성 및 속도 개선 방법 - Taku Tada

본 세션의 발표를 맡게 된 Taku Tada입니다.
저는 2020년에 LINE에 입사해, 개발 T 팀에서 서버사이드 엔지니어 업무를 담당하고 있습니다.
주 업무는 LINE MUSIC 개발로서, 음악 레이블 대상 서비스를 개발하고 있습니다.
LINE MUSIC
LINE MUSIC은 구독형 음악 서비스입니다.
약 8500만 곡을 가지고 있으며, 음악 추천 기능과 LINE 앱의 프로필 뮤직을 설정할 수 있는 기능을 갖추고 있습니다.

LINE MUSIC에서 청취할 수 있는 음악은 음악 레이블에서 제공합니다.
제가 소속된 개발 부서에서는 음악 레이블 대상의 납품 및 재생 정보 확인 서비스를 개발 및 운용하고 있습니다.
예를 들자면 곡 정보를 열람할 수 있는 CMS 웹 UI, 곡 정보를 취득할 수 있는 API 등이 있습니다.
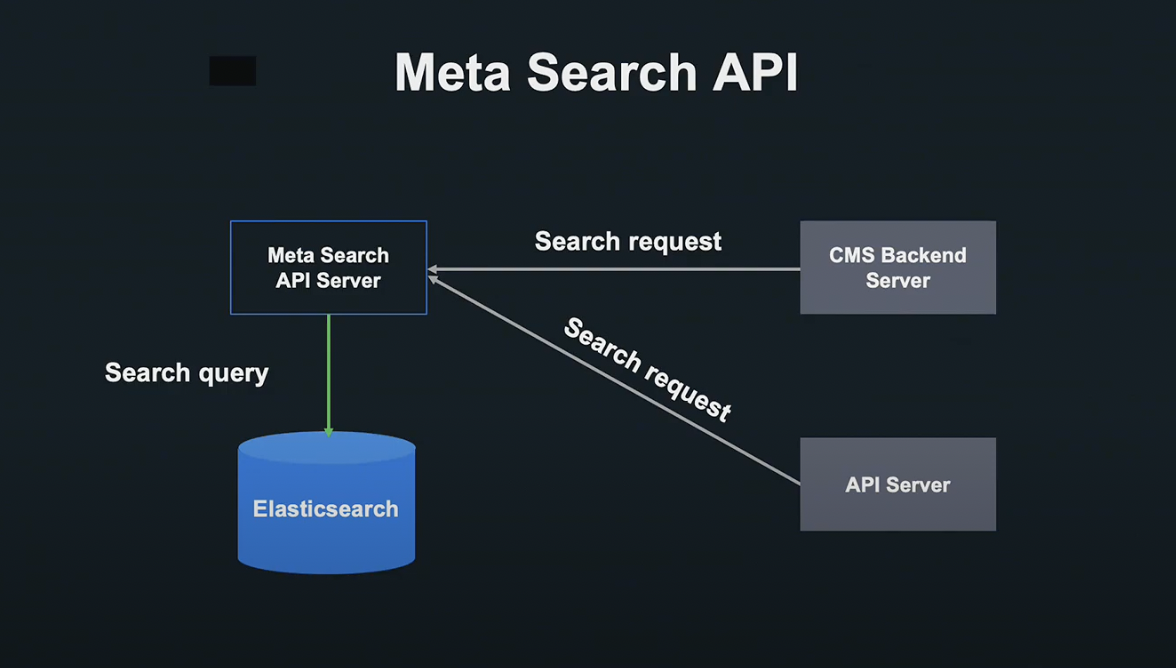
이러한 음악 레이블 대상 서비스는 곡 정보 검색 API를 갖는 Meta Search API 서버로 작동합니다.
유저가 곡을 검색할 경우 이 Meta Search API 서버에 요청을 보내 Elasticsearch를 활용해 검색을 하게 됩니다.
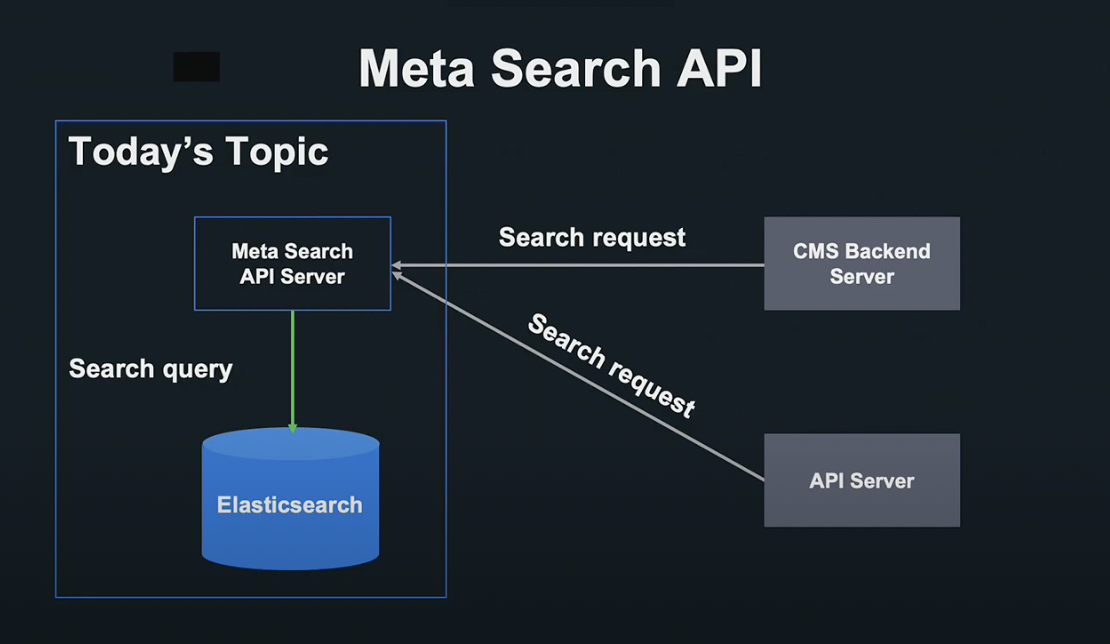
이번 세션에서는 Meta Search API 서버와 Elasticsearch의 개발에 초점을 맞춰 설명드리겠습니다.
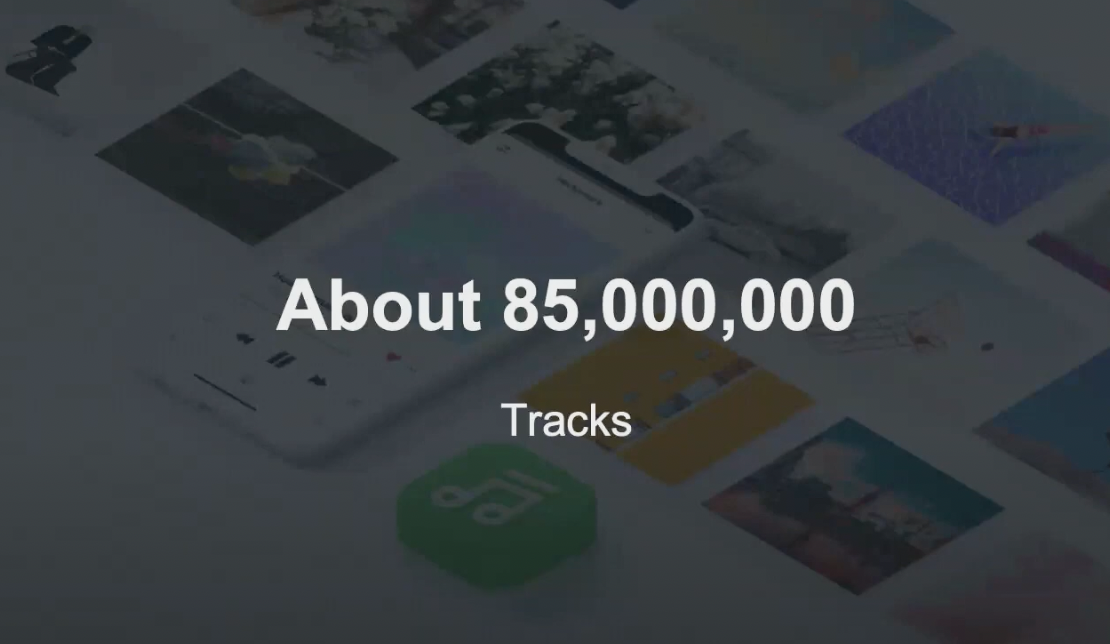
Meta Search API 서버에서 이용중인 Elastic Search에는 약 8500만 곡의 데이터가 저장되어 있으며, 매년 증가 중입니다.
방대한 양의 데이터는 개발 추진에 있어 걸림돌이 되었습니다.
본 발표에서는 대량의 데이터 검색 기능 개발에서 부딪힌 문제와, 해결 방안을 사례와 함께 말씀드리겠습니다.
Agenda

본 발표에서는 두 가지 사례를 말씀드리겠습니다.
- CMS 검색 기능 개발
- 음반 회사 API
Search feature in CMS
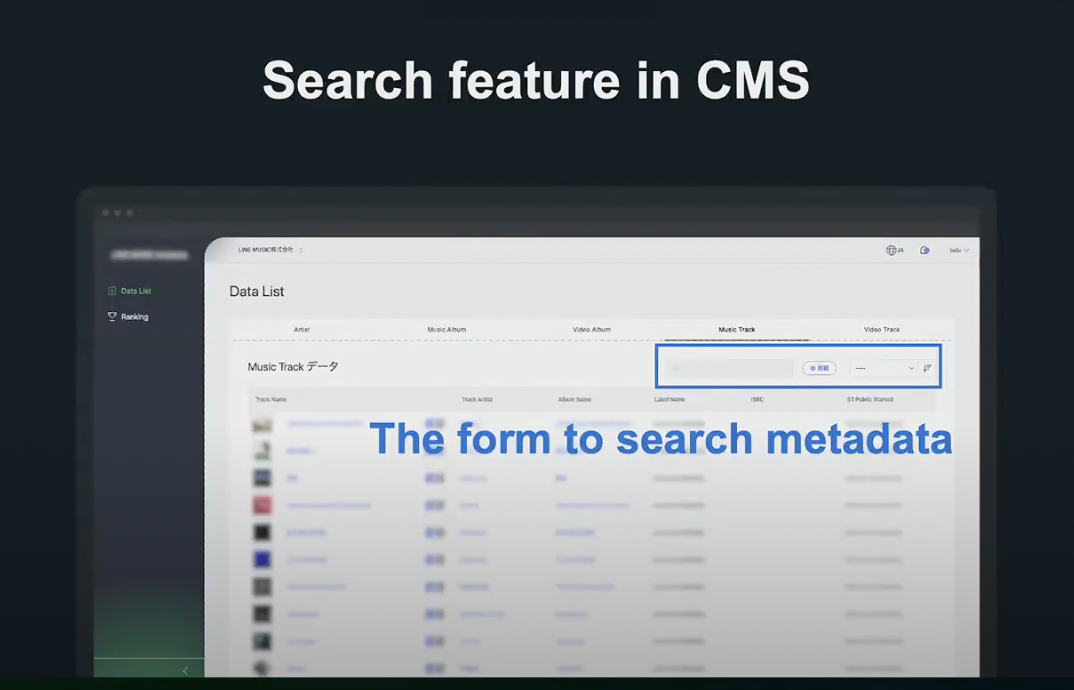
LINE MUSIC CMS에서는 곡 검색 기능이 있어, 검색 키워드를 입력하면 부분 일치하는 결과들이 리스트 형식으로 표시됩니다.
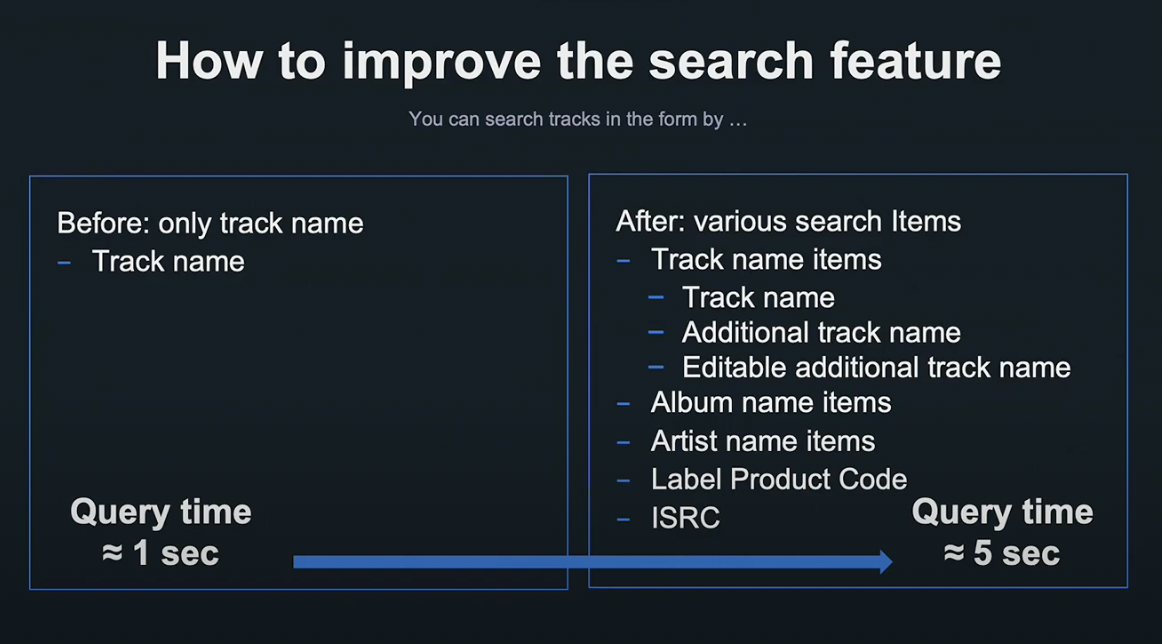
이 검색 기능에는 기능 개선 업데이트가 있었습니다.
검색 기능은 원래 곡명만 검색을 지원했습니다. 하지만 그럴 경우 앨범, 아티스트 등의 검색이 불가능했습니다.
그래서 정식 명칭 외 별칭, 앨범명, 아티스트명 등으로도 검색 가능한 기능을 업데이트했습니다.
그렇지만 예전의 검색 방법에 단순히 항목만 늘리는 방법으로는 검색 시간이 5초나 소요되었기 때문에, 기존 방법을 재고할 필요가 있었습니다.

그렇다면 기존의 검색 방법은 왜 느렸을까요?
과거에는 검색 항목 데이터를 Elasticsearch의 데이터형인 Keyword형으로 저장했습니다.
Keyword형은 단순 데이터형으로, 데이터를 저장할 때 문자열 그대로 입력하고, 위 그림의 ‘bc’와 같이 와일드 카드를 사용해 패턴을 기술하는 쿼리인 와일드 카드 쿼리를 사용해 검색합니다.
하지만 뒷부분이 일치하는 데이터의 경우 검색 퍼포먼스가 저하되는 단점이 있습니다. 이번에는 이 선형 탐색 방식이 퍼포먼스 저하의 근본적인 원인이었습니다.

애시당초 Keyword 형을 사용한 이유가 뭘까요?
검색 기능 개발 초기에는 신속한 릴리즈를 위해 속도를 우선시했습니다.
Elasticsearch 성능 자체는 키워드형보다 텍스트형이 빠르지만, 텍스트형을 사용하려면 말 뭉치로 문자열을 분열하는 Tokenize가 필요한데 곡 데이터와 같이 짧고 고유 명사가 많은 경우에는 일반적으로 사용하는 사전 기반 Tokenize가 효과적이지 않았습니다.
이런 데이터를 잘 다루기 위한 개발을 위해서는 많은 공수가 필요했기 때문에, 개발 초기에는 키워드형을 통한 빠른 가치 제공을 목표로 했습니다.

항목 확대 기능을 위해서는 검색 성능을 높일 필요가 있었습니다.
저희는 고속화를 위해 데이터 텍스트형을 변경하고, Match Query를 도입했습니다. 그 결과 전치 인덱스를 사용할 수 있게 되었고 대량의 데이터도 빠르게 검색할 수 있게 되었습니다.

Match Query를 사용하기 위해서는 Tokenize가 필요합니다.
저희는 사전 기반의 Tokenize가 아닌 n-gram 방식을 도입했습니다.
n-gram은 문자를 n개의 연속된 줄로 분할하는 방법입니다.
- 1-gram(유니그램)은 a, b, c, d, e
- 2-gram(바이그램)은 ab, bc, cd, de
- 3-gram(트리그램)은 abc, bcd, cde
그렇다면 n-gram으로 Tokenize된 데이터에 Match Query를 사용할 경우 어떻게 될까요?

Elasticsearch는 Tokenize된 문자열을 전치 인덱스로 작성해 어느 문자열이 어디에 포함되어 있는지 표현합니다.
그 결과 검색할 때마다 전치 인덱스를 사용하여 모든 문자가 포함되어 있는 문서만 찾기 때문에 불필요한 스캔이 없어지고, 처리 속도가 빨라집니다.
그렇지만 그림의 kyoto의 예시와 같이 불필요한 결과가 포함되는 의도되지 않은 상황이 발생하기도 합니다.

Full Text Query의 경우 문자열 순서가 보장되지 않았기 때문에, 동적 쿼리로 변경시켜 문제를 해결했습니다.
검색할 문자열 크기에 따라 n-gram의 n을 변경합니다.
미리 Document에 유니그램, 바이그램, 트리그램의 데이터를 작성해 두고, 문자열의 길이에 따라 각각 대응하는 필드로 매칭시킵니다.

아까의 Tokyo 예도 트리그램으로 처리하면 웬만하면 순서가 바뀌어 나오지 않기 때문에 검색 결과의 정확도를 높일 수 있습니다.
이번 검색 개선에서는 검색 데이터형을 텍스트형으로 만들고, n-gram과 동적 쿼리를 융합시켜 검색의 정확도를 높였습니다.
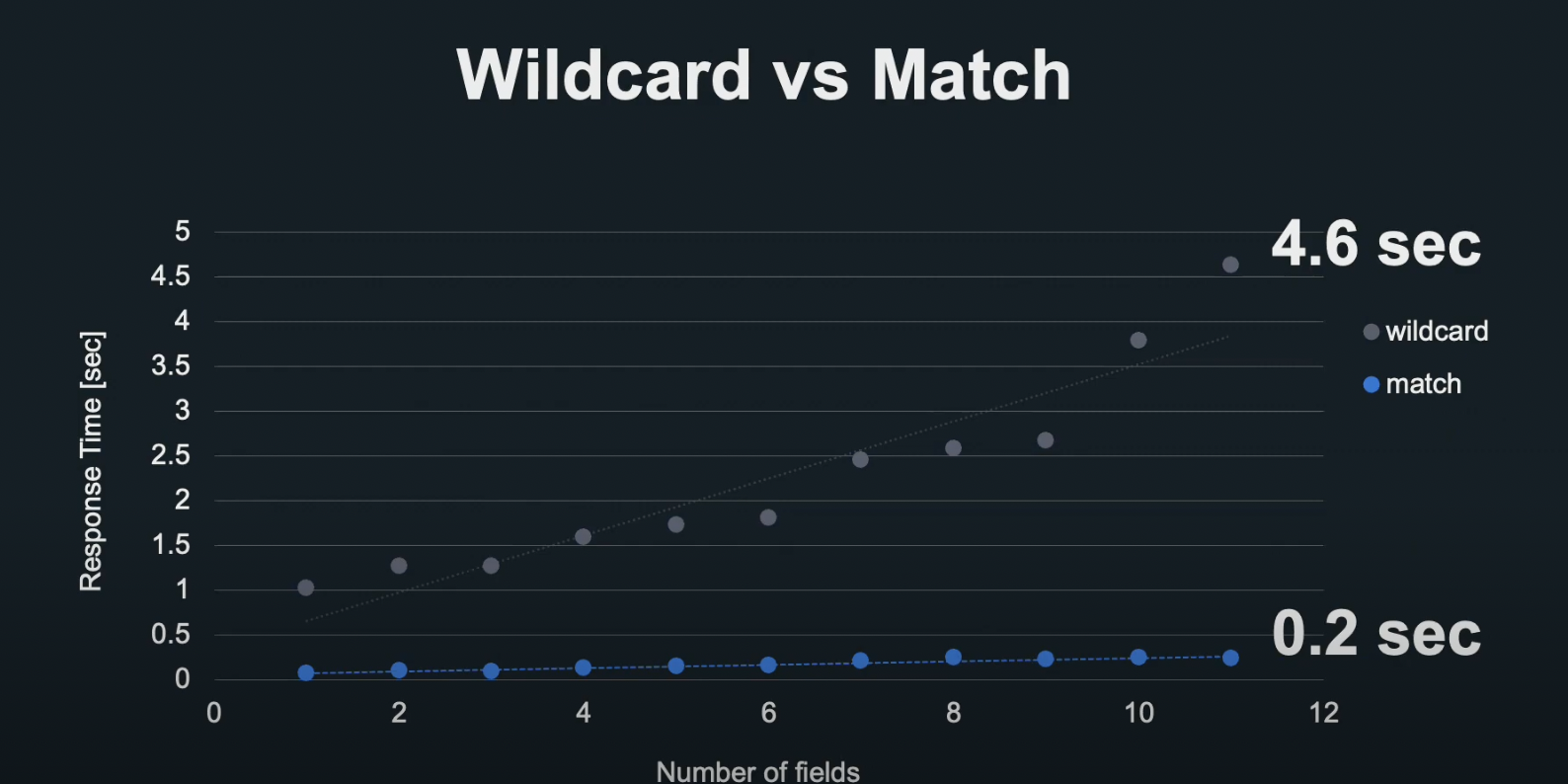
위의 도표는 개선 전(와일드 카드)과 개선 후(매치 쿼리)의 속도를 비교한 데이터입니다.
실제 환경과 동일한 데이터를 사용했고, 가로축은 검색 항목 수, 세로 축은 각각 와일드 카드, 매치 쿼리입니다.
항목이 늘어날수록 속도가 급격히 느려졌던 와일드 카드에 비해 매치 쿼리는 항목이 늘어나도 0.2초의 높은 성능을 보여주고 있습니다.

검색 기능을 개발하며 얻은 교훈에 대해서 정리하겠습니다.
와일드카드를 사용한 후방 일치 쿼리는 방대한 데이터를 처리할 때 속도가 느려지기 때문에, 매치 쿼리로 변경시켜 고속화 하는 것을 검토해 볼 가치가 있습니다.
또한 곡 데이터같이 짧고 고유명사가 많은 데이터의 경우, 사전 기반 Tokenize가 힘들기 때문에 n-gram과 동적 쿼리를 사용해 데이터 정합성을 향상시키고 빠른 속도를 구현할 수 있습니다.
이러한 개선을 통해 쉽고 빠르게 검색할 수 있게 되어 좋은 유저 경험을 얻을 수 있게 되었습니다.
API for Record Labels

지금부터 음악 레이블 대상 API 개방 사례에 대해서 말씀드리겠습니다.
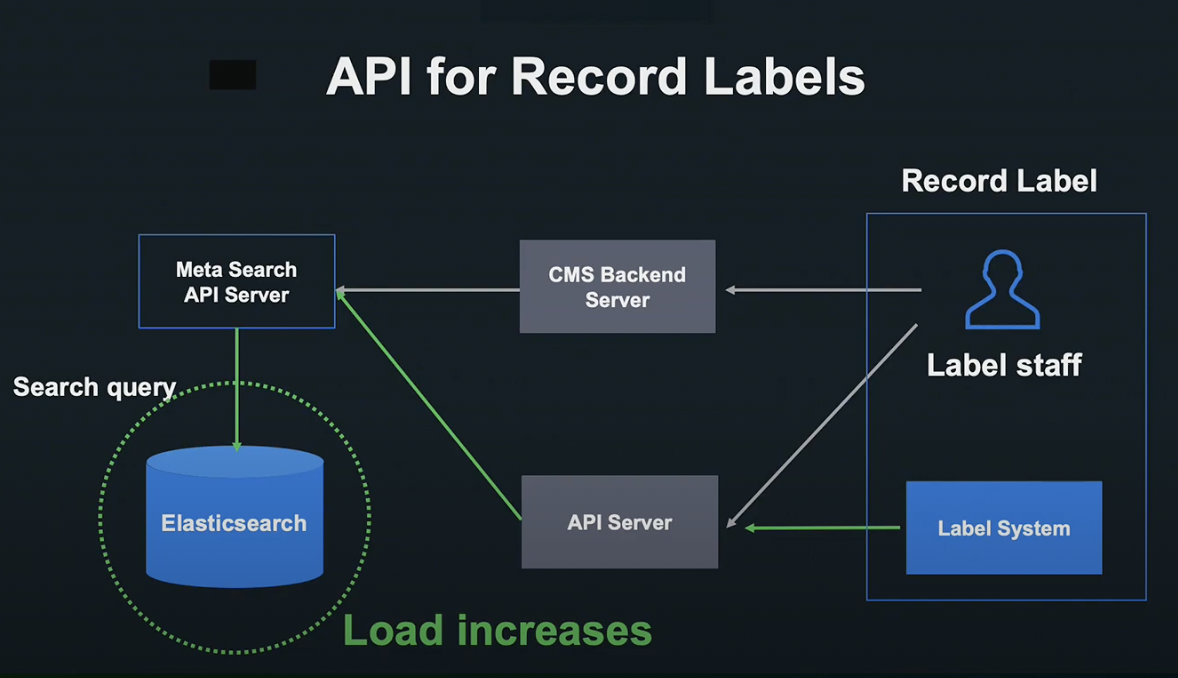
과거에는 음악 레이블 직원이 CMS를 조작해 요청했지만, 지금은 기능을 API로 개방했기 때문에 레이블의 자체 시스템에서도 요청이 오게 되었습니다.
그렇기 때문에 서버는 많은 요청에 견딜 수 있어야 했고, 시스템에 부하 테스트를 실시한 결과 많은 데이터 양으로 인해 곡 정보 검색은 부하를 견디지 못했습니다.
더 조사해보니 Elasticsearch가 병목 현상을 초래하고, 노드 CPU를 100% 사용해 요청이 막히게 된다는 것을 알게 되었습니다.
처음에는 쿼리 관련 튜닝을 시도했지만 크게 개선된 점이 없었고, 인프라 강화를 시도하게 되었습니다.
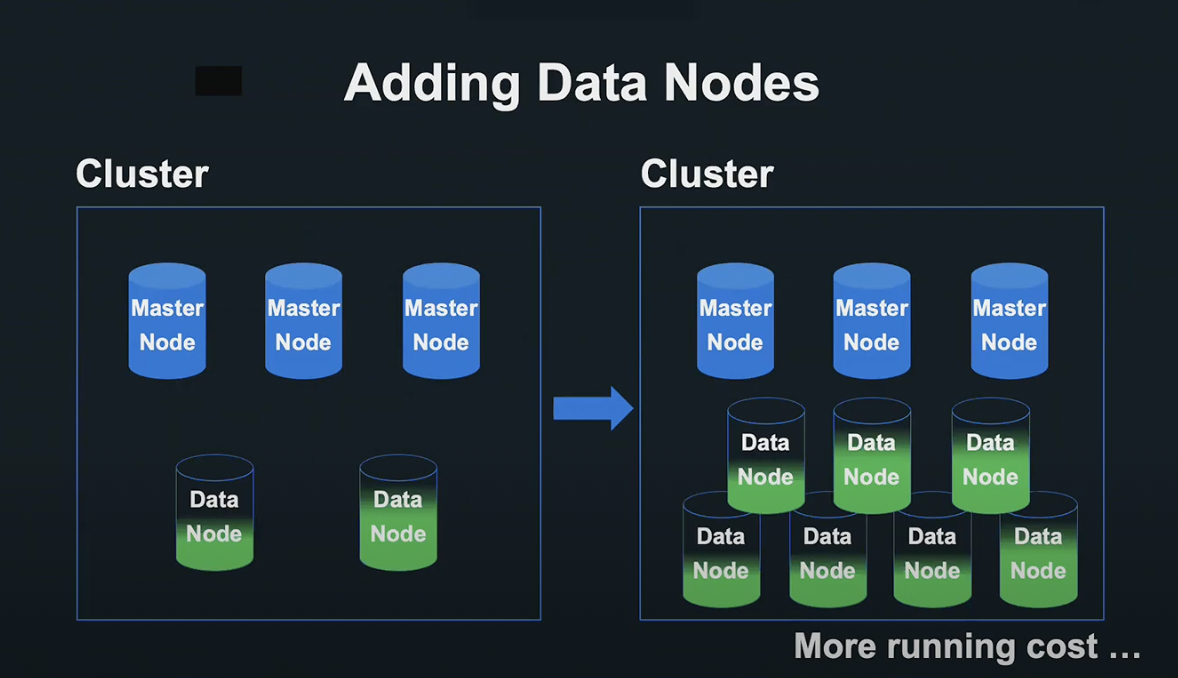
Elasticsearch 클러스터는 처리를 제어하는 마스터 노드와 데이터를 분산 처리하는 데이터 노드 두 가지가 있습니다.
데이터 노드를 늘림으로서 검색 처리를 여러 노드로 분산시켜 검색 성능을 향상싴리 수 있기 때문에, 데이터 노드를 추가하기로 했습니다.
하지만 노드의 증가에는 현실적으로 한계가 있었기 때문에, 추가적인 방안을 고려해야 했습니다.
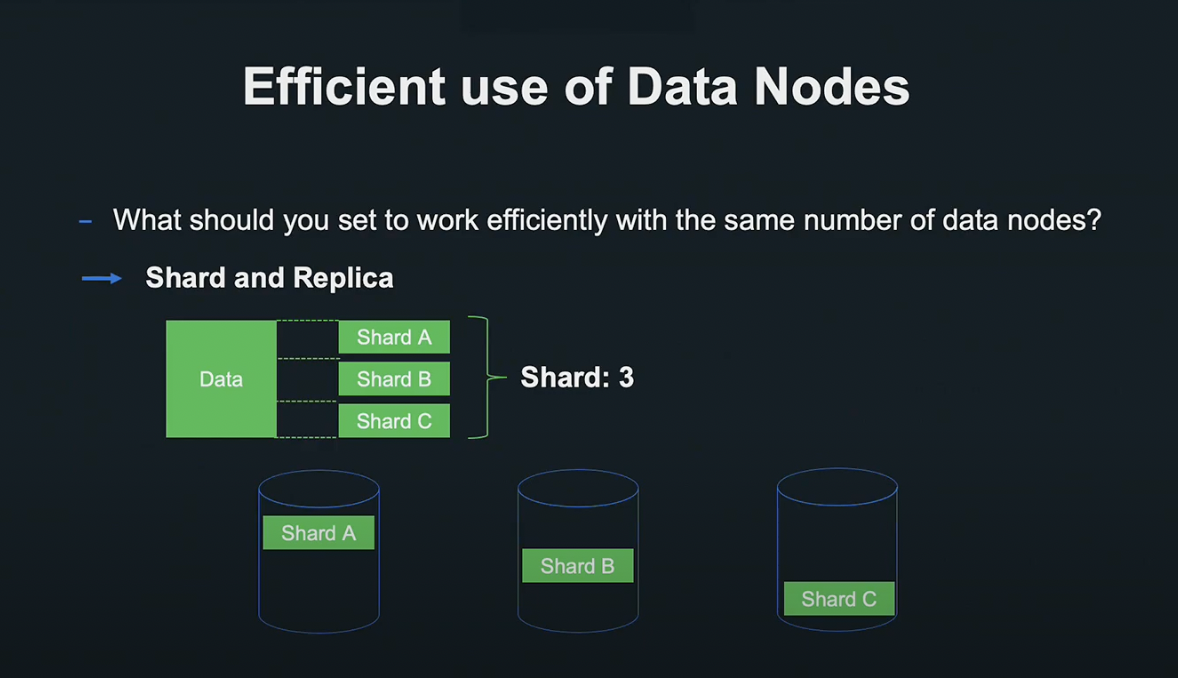
한정된 수의 노드를 효율적으로 작동시키기 위해 Shard와 Replica의 설정을 최적화시키기로 하였습니다.
Shard는 데이터를 수평 분할시킨 단위로서, 분할된 Shard를 각 데이터 노드에 하나씩 배치하면 데이터의 분산 처리가 가능합니다.

Replica는 Shard의 복제 단위로서, 하나의 Primary Shard를 몇 가지 Replica Shard에서 복제할지 설정할 수 있습니다.
복제된 Replica Shard를 여러 데이터 노드에 배치함으로서 가용성을 증가시키고, 부하 성능을 개선할 수 있습니다.
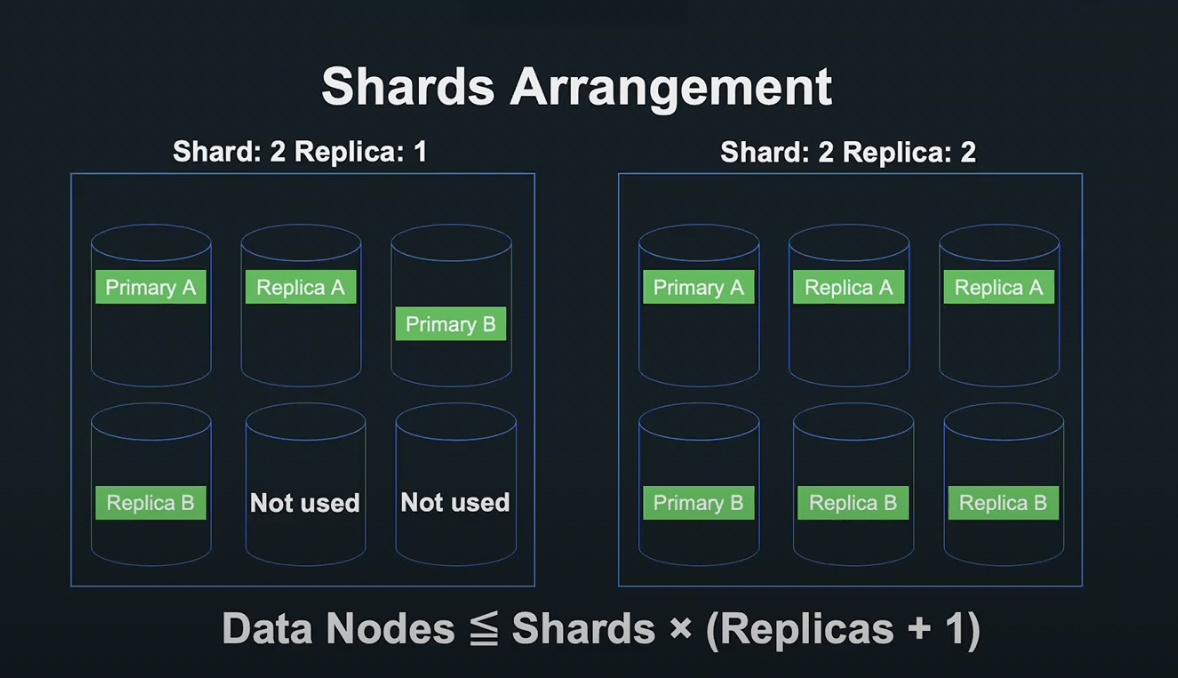
Shard x (Replica + 1)이 데이터 노드의 숫자 이상이 되도록 결정하여, 가용성을 높이고 최대한 처리를 분산할 수 있도록 설정했습니다.
하지만 실제로 Shard는 데이터 수평 분할 크기와 쿼리에 따라서도 성능이 바뀌기 때문에, 실제로 성능을 측정해서 결정할 필요가 있었습니다.
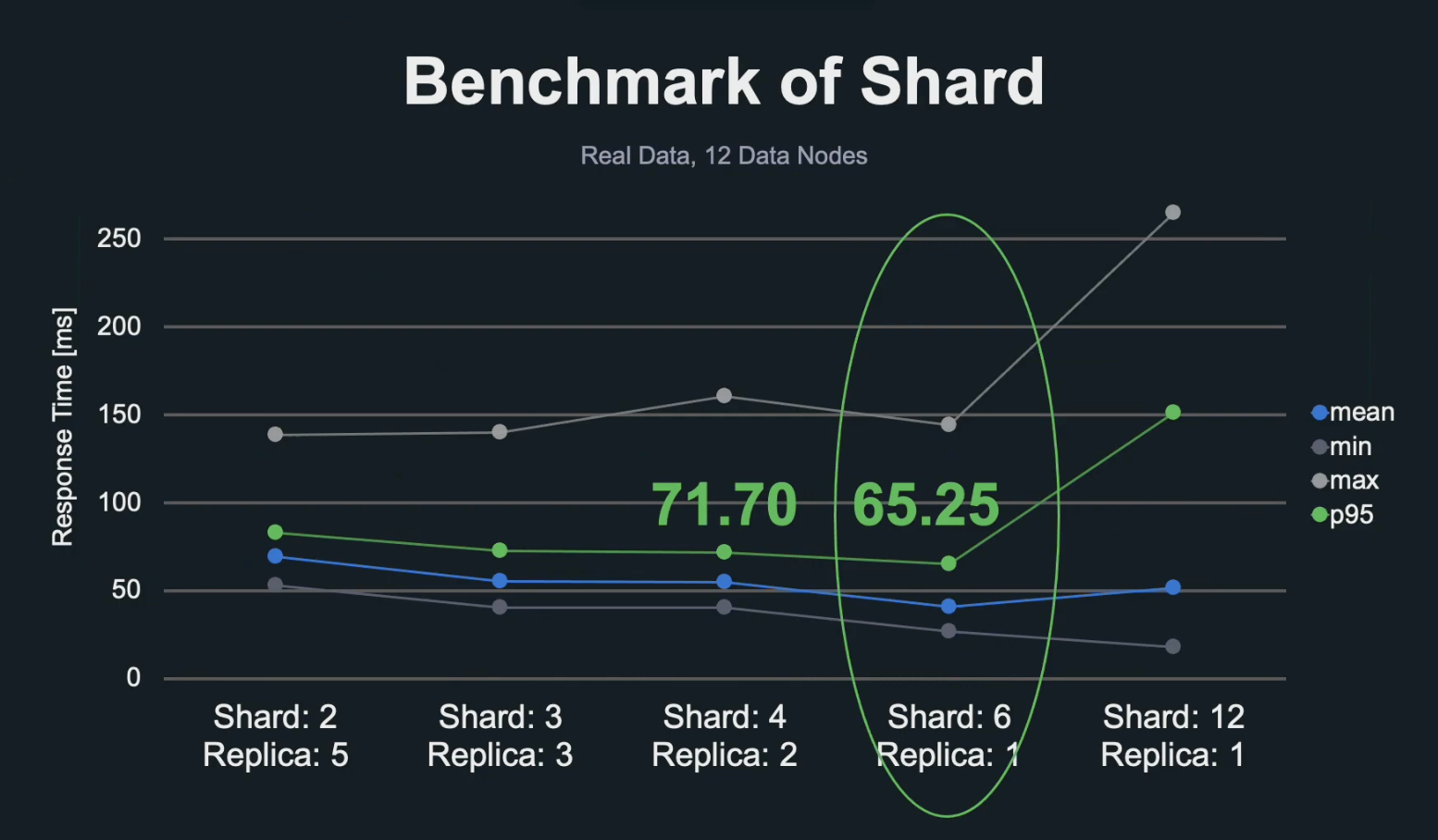
위 그림은 여러 조건의 Shard, Replica로 실시한 부하 시험의 응답 시간 그래프입니다.
7,500만 곡의 데이터와 12개의 데이터 노드로 응답을 측정한 결과 6 Shard, 1 Replica로 6분할 처리를 하는 것이 가장 좋은 성능을 낼 수 있었습니다.
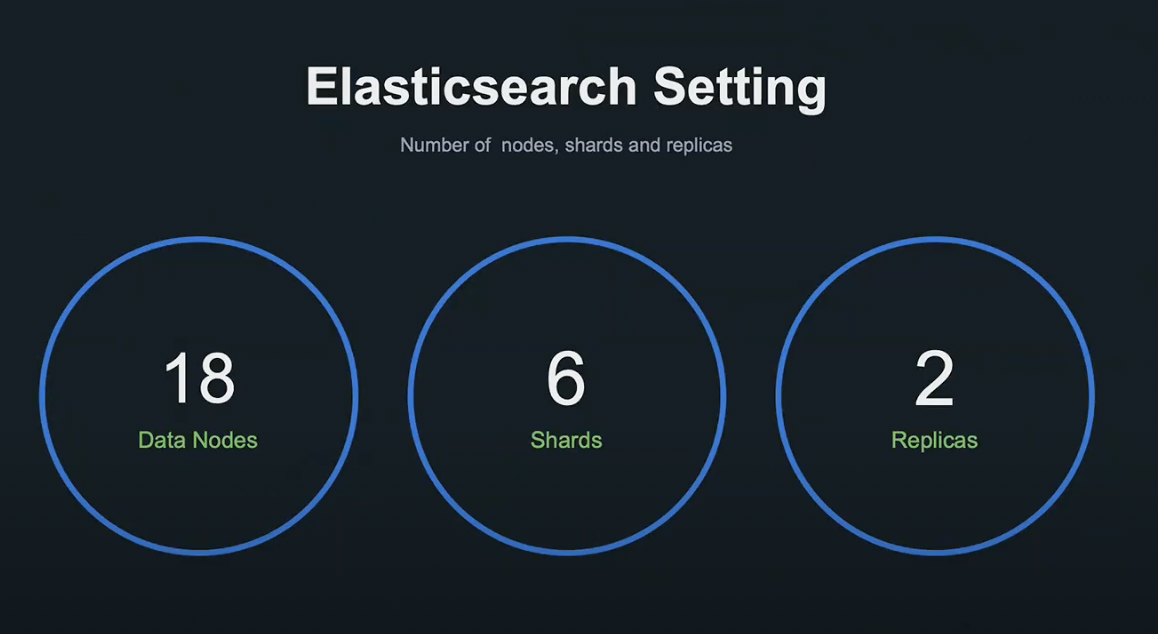
현재 운영 환경은 18대의 데이터 노드에 6개의 Shard, 2개의 Replica로 가동하고 있습니다.
미리 부하 요건을 이러한 설정과 테스트를 통해 확인했기 때문에 안정적인 릴리즈가 가능했습니다.
하지만 데이터가 늘어나면 최적의 Shard 수가 변경되기 때문에, 정기적으로 벤치마킹 환경을 정비하여 알맞게 변경할 필요가 있습니다.
이번 사례를 통해 적절한 Shard 수치를 확보하고 부하 시험의 환경을 정비할 수 있었습니다.
결론

CMS 검색 기능 개선 사례에서는 와일드 쿼리 방식을 텍스트형 매치 쿼리로 변경해 성능을 높였고, n-gram과 동적 쿼리를 사용해 사전 기반 Tokenize를 효율적으로 대체했습니다.
음악 레이블 대상 API 개방 사례에서는 데이터 노드 증설과 Shard/Replica 튜닝을 통해 Elasticsearch의 부하를 효과적으로 감소시킬 수 있었습니다.
여러분도 저희가 사용한 방법을 서비스에 적용하여, 성능을 개선시킬 수 있으셨으면 좋겠습니다.
이상으로 발표를 마치겠습니다. 감사합니다.
후기
LINE 조직이 일하는 법, 대규모 아키텍처 설계 등등.. LINE이라는 조직의 제품에 녹아 있는 고민과 열정을 느낄 수 있었습니다.
회사나 개인 프로젝트에서 사용 중인 아키텍처를 다시 한번 생각해 보게 되네요.
이것저것 일이 밀려 생각보다 늦게 작성하게 되었습니다.
영상을 글로 옮기는 작업이 생각보다 오래 걸렸네요.
긴 글 읽어주셔서 감사합니다.
Reference
마케팅 데이터 플랫폼 ‘Business Manager’ 개발기
8년간 유지해 온 Perl 프로덕트를 Kotlin으로 바꾼 이야기

{kind=link}