
LINE DEVELOPER DAY 2021의 Day 1 Server-Side 세션들을 정리해 보았습니다. 혹여 잘못 이해한 부분이 있거나, 오탈자가 있는 경우엔 댓글로 알려주시면 감사하겠습니다.
| 세션 | 발표자 |
|---|---|
| Hbase Kafka 데이터 파이프라인 활용 사례 | Shinya Yoshida |
| LINT-HTT/2와 TLS를 통한 네트워크 현대화 | 이벽산 |
| LINE 앱을 위한 확장 가능한 멀티 데이터 센터 ID 제너레이터 | Masahiro Ide |
| LINE 플랫폼 서버의 장애 대응 프로세스와 문화 | 이수안 |
| TCP로 인한 대규모 Kafka 클러스터 요청 지연 문제 해결 사례 | Haruki Okada |
| LINE Home Tab에 컨텐츠를 전달하기 위한 고범용성 시스템 | Zhixin Li |
Line Messaging 플랫폼에서 HBase와 Kafka 데이터 파이프라인 활용 사례 - Shinya Yoshida

Agenda

본 세션의 Agenda는 다음과 같습니다.
- LINE Messaging Platform에서의 HBase 활용
- HBase-Kafka Data Pipeline과 활용 사례
Line Messaging Platform Server-Side 기술 스택
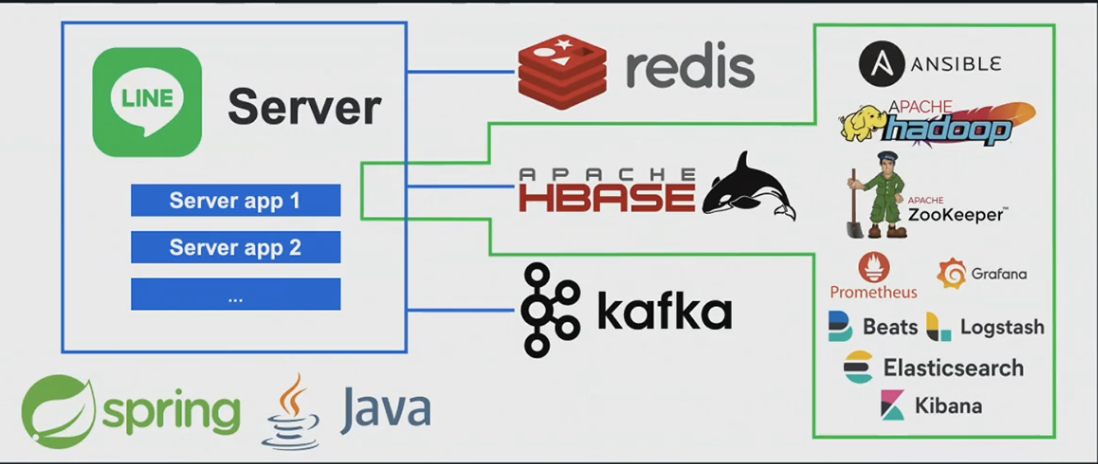
- Application - Java & Spring
- DataSource - Redis, HBase, Kafka
- Hbase Cluster - Hadoop, ZooKeeper
- Monitoring - Prometheus, Grafana, ElasticSearch, Kibana
- Provisioning - Ansible
Line HBase Unit 팀에서는 HBase Cluster의 구축&운영과 Batch, Server-Side 어플리케이션 내 HBase 접속 전략&로직, Hadoop & Zookeeper Cluster에 대한 구축&운영을 담당하고 있습니다.
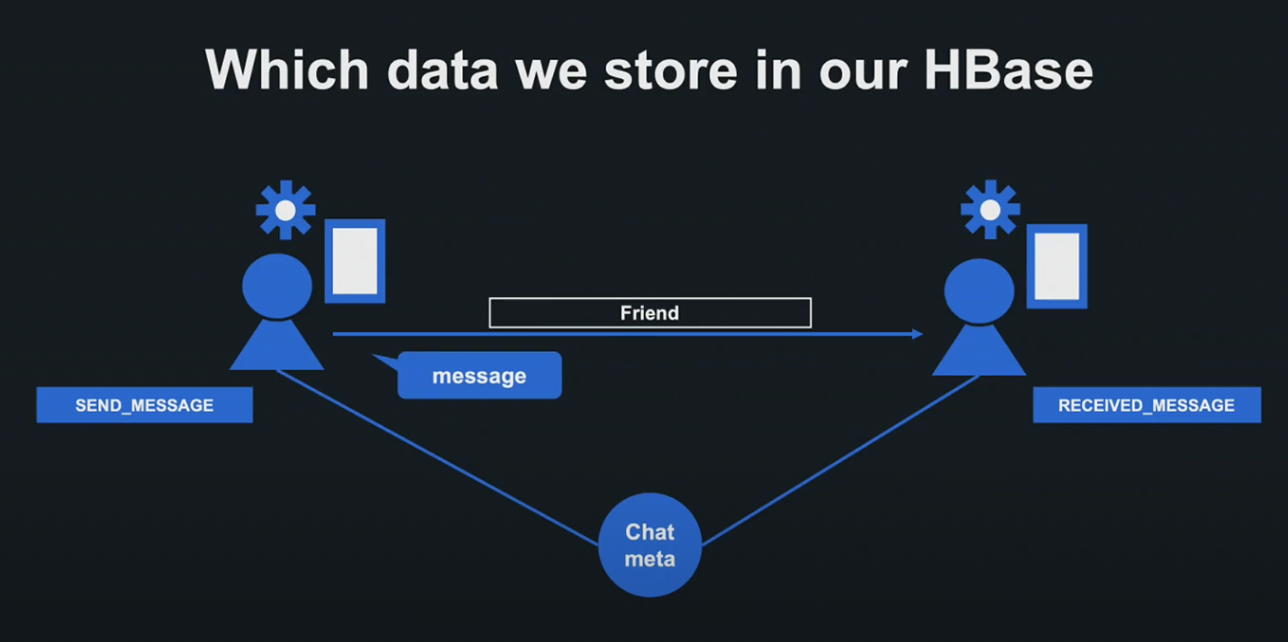
Messaging Platform의 Hbase Cluster에는 유저 정보, 디바이스 정보, 세팅 정보, 메세지 이벤트 정보 등의 다양한 데이터가 저장됩니다.
HBase Architecture
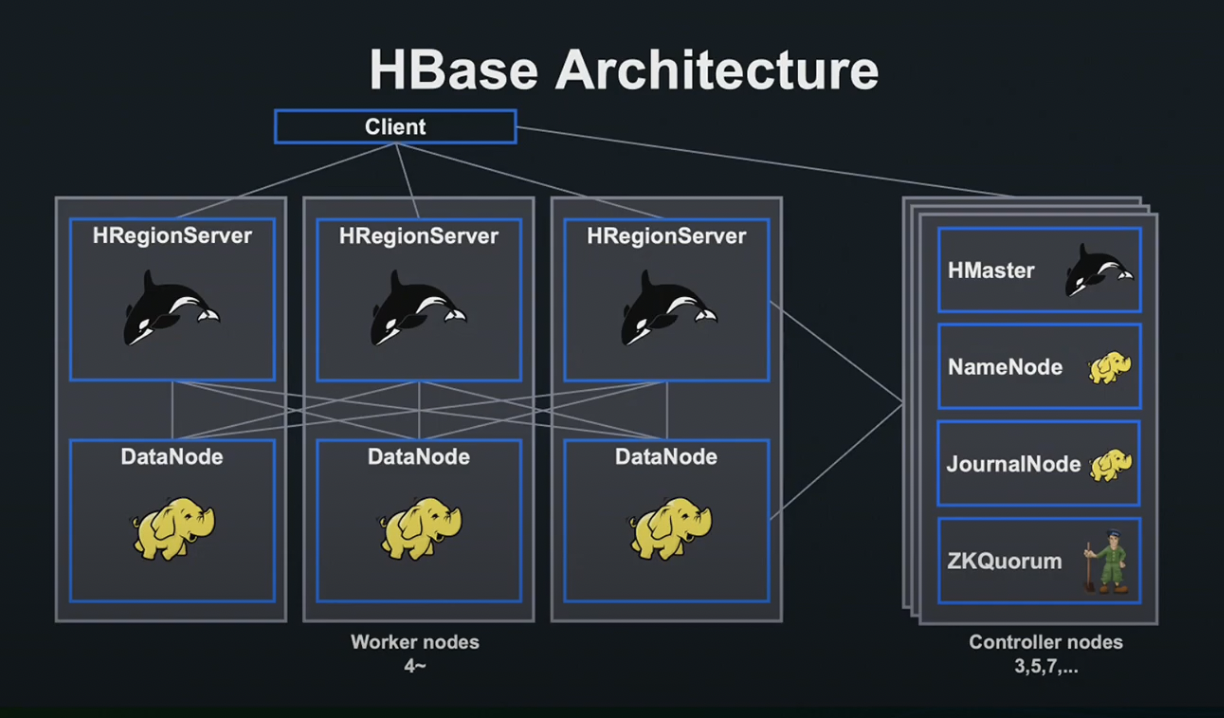
HBase는 Hadoop과 ZooKeeper에 의존하고 있습니다. 또한 HBase Cluster는 홀수의 Controller Node, 대규모의 Worker Node로 구성되어 있습니다.
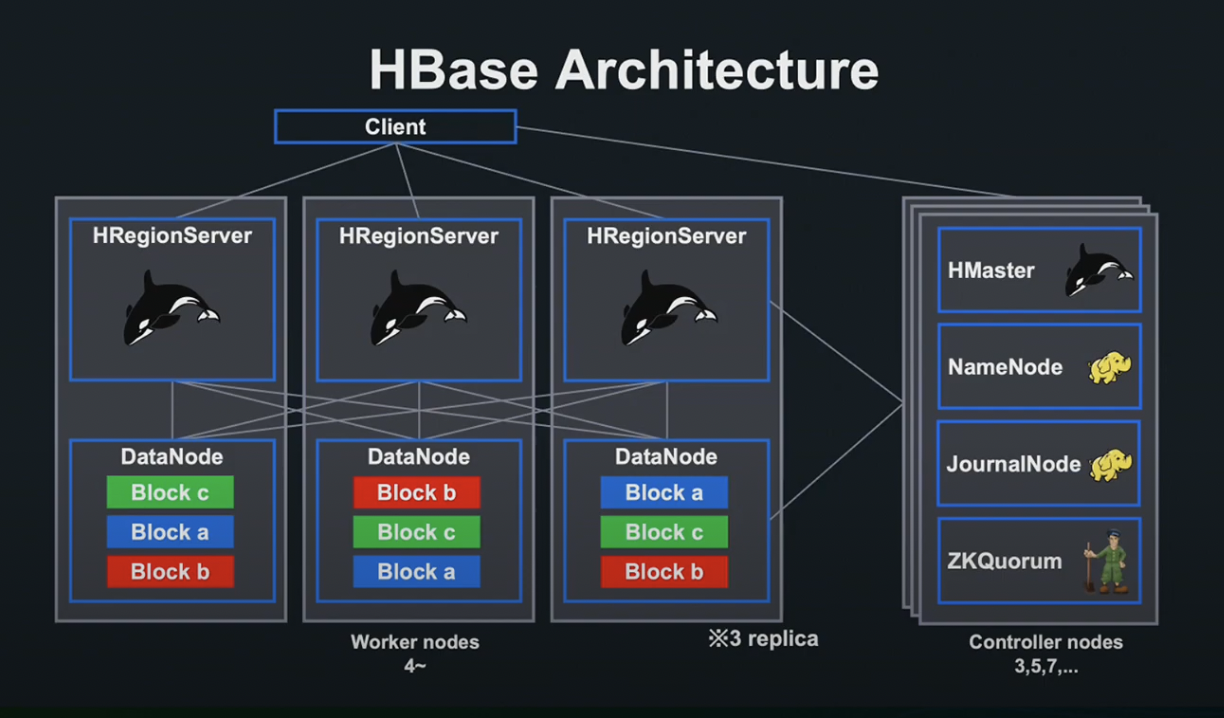
파일은 복수의 블럭으로 분할되어 데이터 노드에 저장됩니다. NameNode는 파일이 어떤 블럭에 의하여 구성되어 있는지, 어떤 데이터 노드에 저장되어 있는지를 관리합니다.
HMaster와 HRegionServer는 Controller Node와 Worker Node를 작동시킵니다.
Client는 접속을 하고자 하는 데이터에 대응한 Region이 할당되어 있는 서버에 Request를 송신합니다. 각 Region 서버는 데이터 노드상 블록에 접속하여 Request에 응답합니다.
한 대의 Worker Node에 장애가 발생하더라도, 3개의 Replica 덕분에 각 블록에 접속이 가능하여, 타 리전 서버에 할당 후 계속해서 응답이 가능합니다.
HBase internal write flow
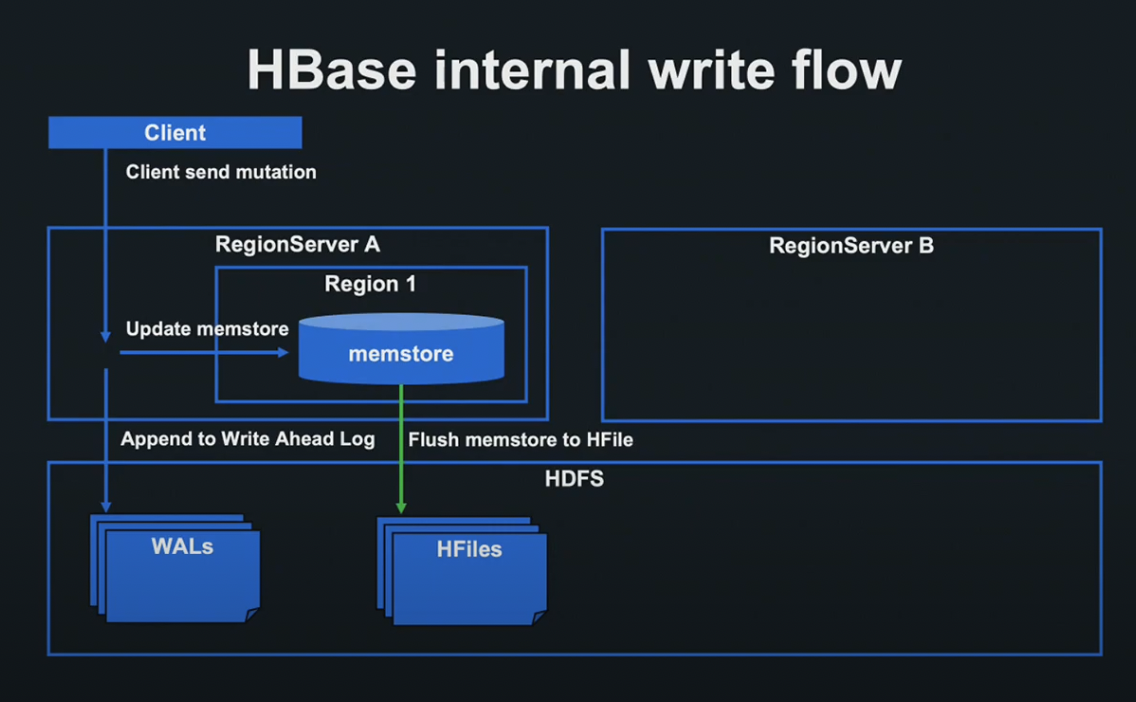
Client는 원하는 데이터에 대응한 Region이 할당되어 있는 서버에 Request를 송신합니다.
Request를 받은 Region Server는 Region마다 존재하는 메모리 상의 Data Store - Memstore를 갱신하고, HDFS 상의 WAL(Write Ahead Log) 파일에 입력합니다.
WAL 파일의 쓰기에 성공한 단계에서 영속화 성공으로 간주하여 Client에 응답합니다. 실패 시 Memstore를 Rollback합니다.
Memstore가 일정 용량에 도달하거나 일정 시간이 경과할 때마다 Memstore의 내용을 HFiles에 Flash합니다.
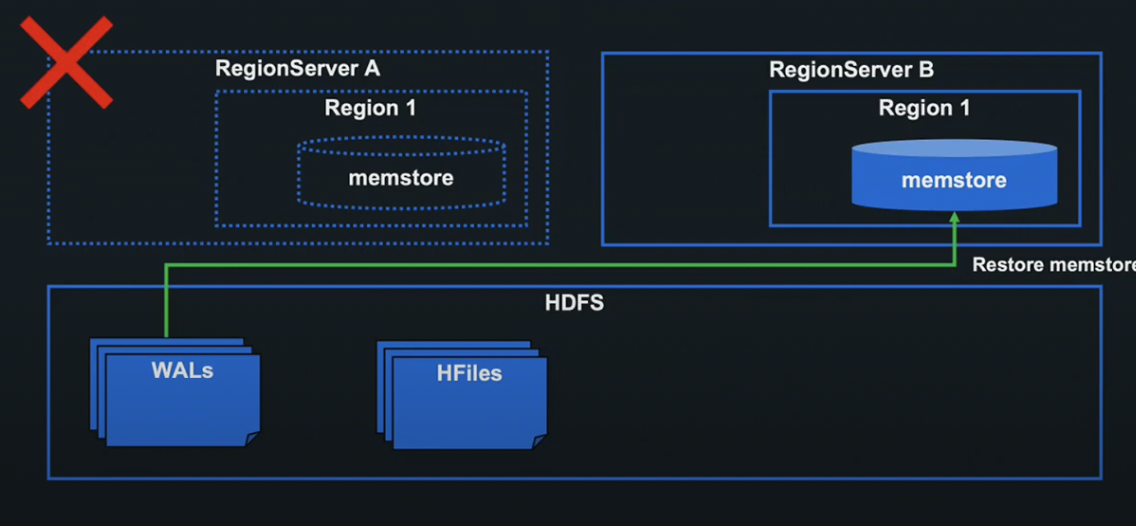
Region Server A에 장애가 발생하더라도 WAL, HFiles로 Restore가 가능합니다.
HBase replication and reliability
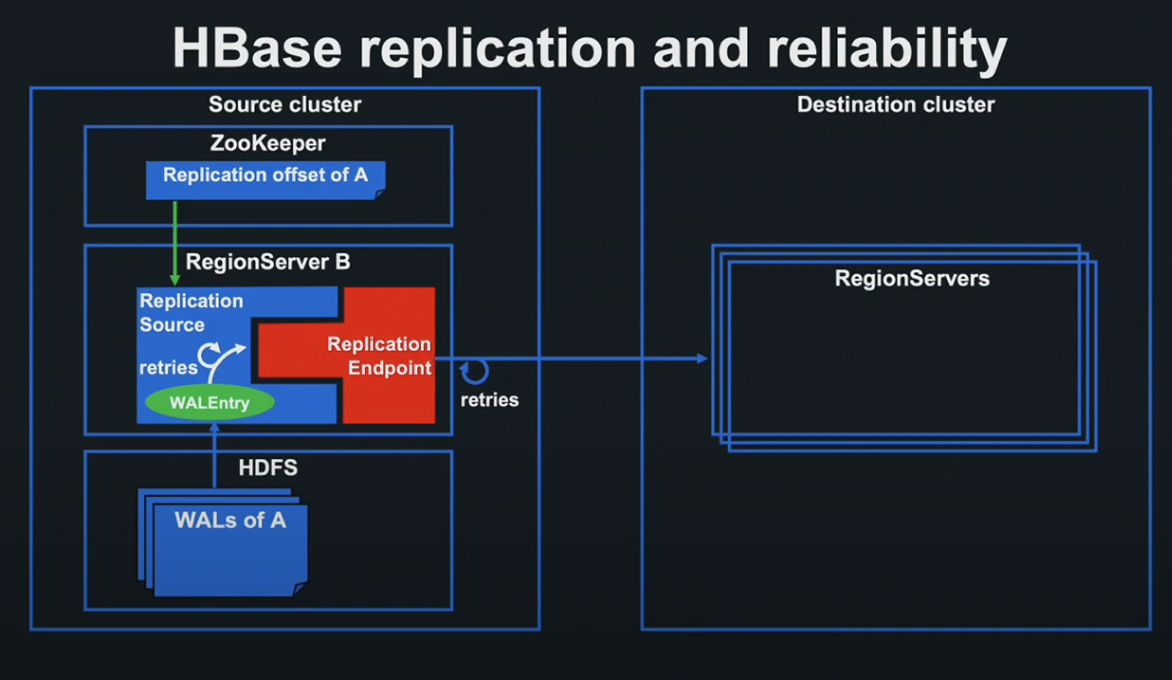
Source Cluster에서 Replication을 Setup한 경우, 각 Region 서버에서는 Replication Source라는 Thread가 가동됩니다.
Replication Source는 HDFS상의 WAL 파일을 읽어 WAL의 각 Entry를 Replication Endpoint로 넘겨줍니다.
각 Endpoint는 Plugable한 형태로 제공되어 있으며, 지정된 Destination Cluster의 각 Region Server에 WALEntry를 송신하고, Region Server는 Entry를 Replace함으로서 Replication을 완성합니다.
송신에 실패할 경우 HBase Client의 Retry 로직과 Replication Source에서 성공할 때까지 Entry를 Endpoint에 계속 전송합니다.
Replication Source는 마지막으로 Endpoint 처리가 성공한 WALEntry의 위치를 Offset으로서 ZooKeeper에 저장합니다.
Region Server A에 장애가 발생하더라도 ZooKeeper에 저장된 offset을 받아 Replication 처리를 빠짐없이 완료합니다.
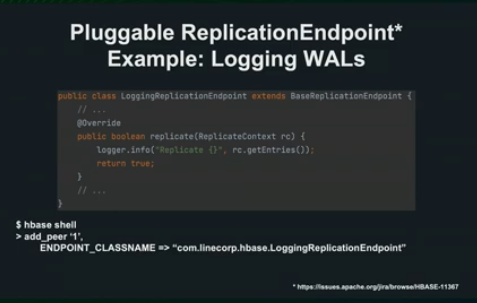
Plugable한 Replication Endpoint를 독자적으로 정의하기 위해서 Endpoint 인터페이스를 상속하는 클래스를 정의합니다.
Hbase and Kafka pipeline
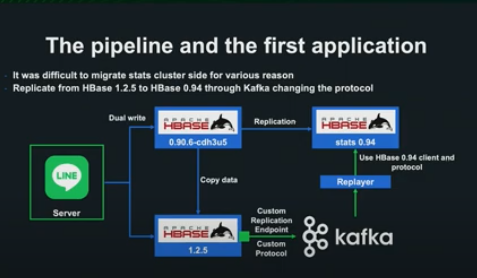
pipeline이 처음 구축된 것은 2017년으로, 당시 HBase의 새로운 버전으로의 Migration이 필요했으나, 버전 호환성 문제로 Replication을 지원하지 않았습니다.
HBase Kafka Data pipeline을 구축함으로서, 해당 문제를 해결했습니다.
Endpoint가 WALEntry를 독자적 프로토콜로 Kafka에 송신하고, Kafka로부터 데이터를 전달받은 Replayer가 Stats Cluster에 데이터를 전송합니다.

본 pipeline은 일반적으로는 변경 데이터 캡처라는 이름으로 알려져 있으며, 데이터베이스의 변경에 따른 처리를 간단하게 실현할 수 있고, 매우 높은 신뢰성을 실현합니다.
한편으로는 비동기적 처리가 이루어지므로 딜레이 발생 가능성이 있으며, 변경 시점에 다른 Data에 접속하기 위해서는 데이터베이스에 접속할 필요가 있습니다.
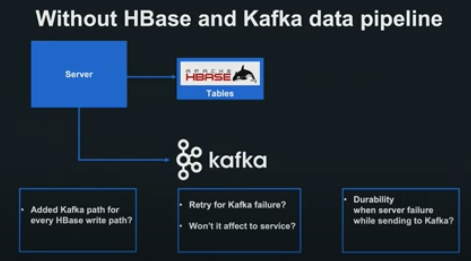
pipeline 구조를 사용하지 않고 같은 처리를 어플리케이션 내에서 처리할 경우, HBase에 쓰기에 성공한 후 그 정보를 Server-Side App 내에서 송신하는 구현을 고려해 볼 수 있습니다.
그러나 모든 쓰기 경로에 송신 경로를 추가할 수 있는지, Retry 로직의 영향도가 어떻게 되는지 등 우려할 사항이 많아지고, 장애 발생 시 모든 HBase 쓰기를 송신 못할 가능성이 존재합니다.
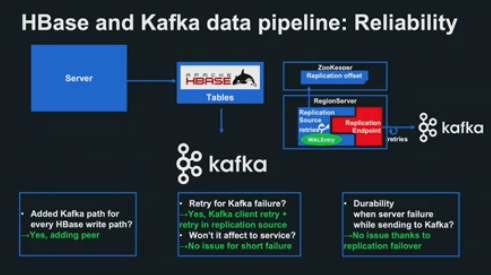
pipeline 구조를 사용함으로서 이런 우려사항과 문제를 간단히 해결할 수 있습니다.
- 쓰기 패스 대응 : Replication Source가 지정 테이블의 모든 쓰기를 처리 대상으로 삼기 때문에, App이나 Replication을 셋업하기만 하면 간단히 해결
- Retry 처리 : Kafka Client Retry Logic + Replication Source에 구현되어 있는 자체 Logic으로 높은 신뢰성
- 신뢰성 : ZooKeeper 상의 Offset 저장, Replication FailOver로 Region Server에 장애가 발생해도 모든 HBase의 쓰기를 확실하게 Kafka에 송신
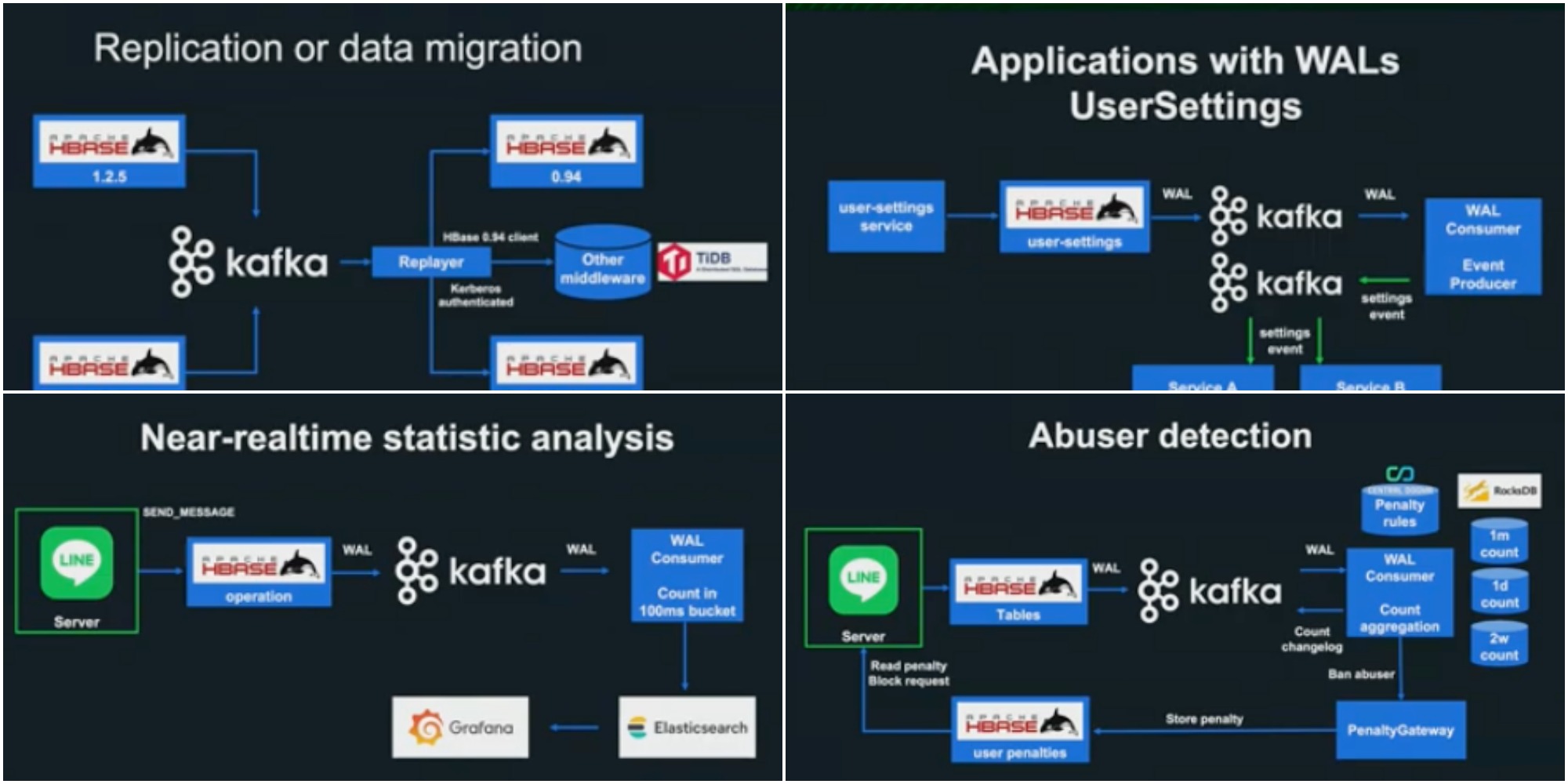
Line에서는 마이그레이션, 리얼타임 통계, 어뷰저 검출 등 다양하게 pipeline을 활용하고 있고, 향후에도 Secondary Index, Incremental Backup 등 다방면의 pipeline 사용을 검토하고 있습니다.
마무리
HBase-Kafka pipeline은 HBase의 구조를 사용해 구축한 pipeline으로, 데이터베이스의 변경에 의거해 처리를 하기 위한 신뢰성 높은 Powerful한 방법입니다.
여러분들의 서비스에서도, 변경 데이터 캡쳐를 실천해 보시면 어떨까요?
LINT-HTT/2와 TLS를 통한 네트워크 현대화 - 이벽산

Agenda

본 세션의 Agenda는 다음과 같습니다.
- 배경 사항
- 연결성 향상을 위해서 취했던 방식
- 발표 요약
LINE Messaging Architecture
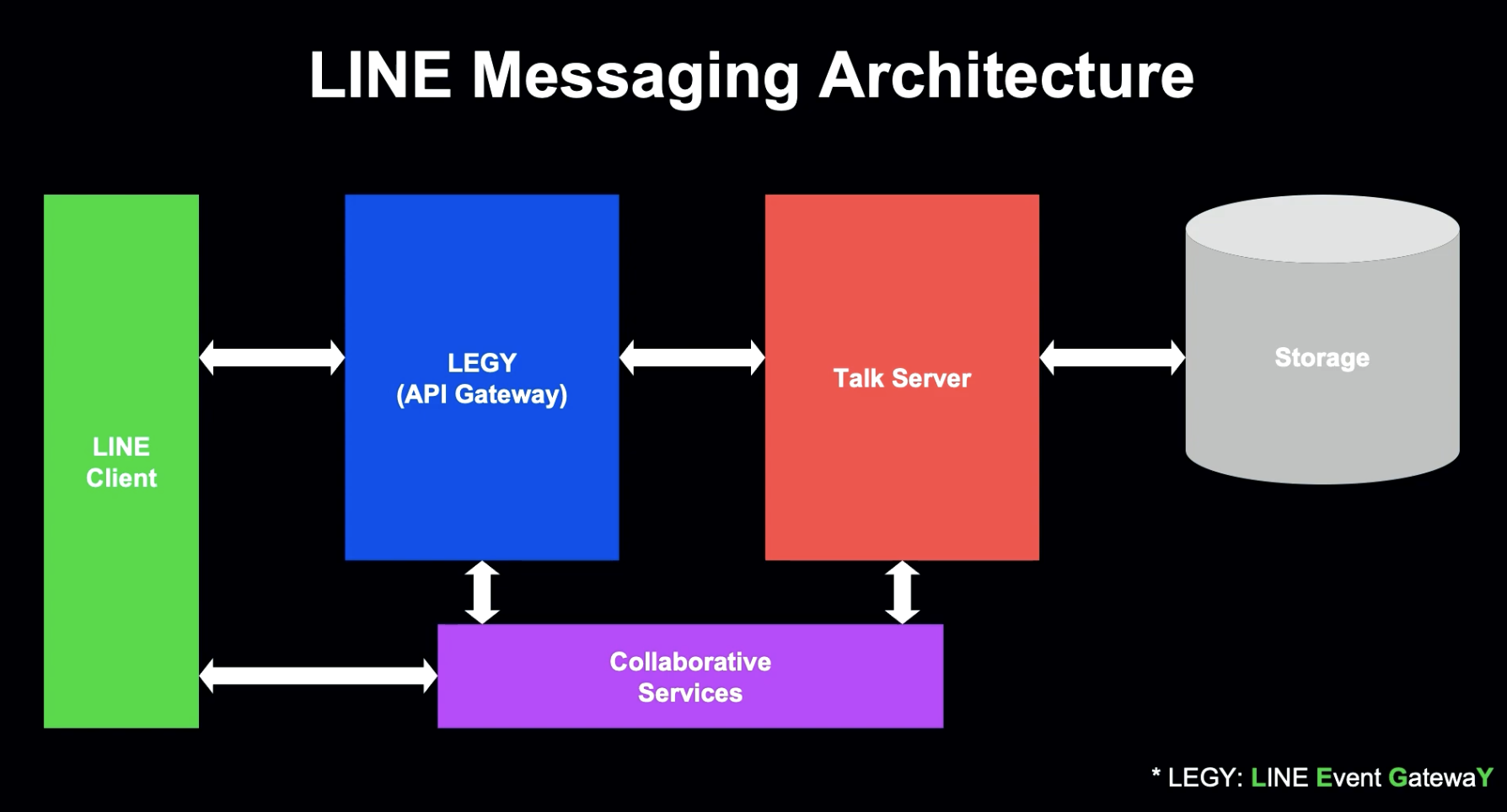
LINE Event GatewaY - LEGY의 주요 업무 중 하나는, 클라이언트와의 연결을 관리하는 것입니다.
이 발표에서는, Line Client와 LEGY 간 Communication에 중점을 둡니다. LINE 서비스의 대부분의 트래픽은 LEGY를 통해 들어오기 때문에, LEGY는 효율적이고 안전한 처리를 할 수 있어야 합니다.
History of LEGY Protocol
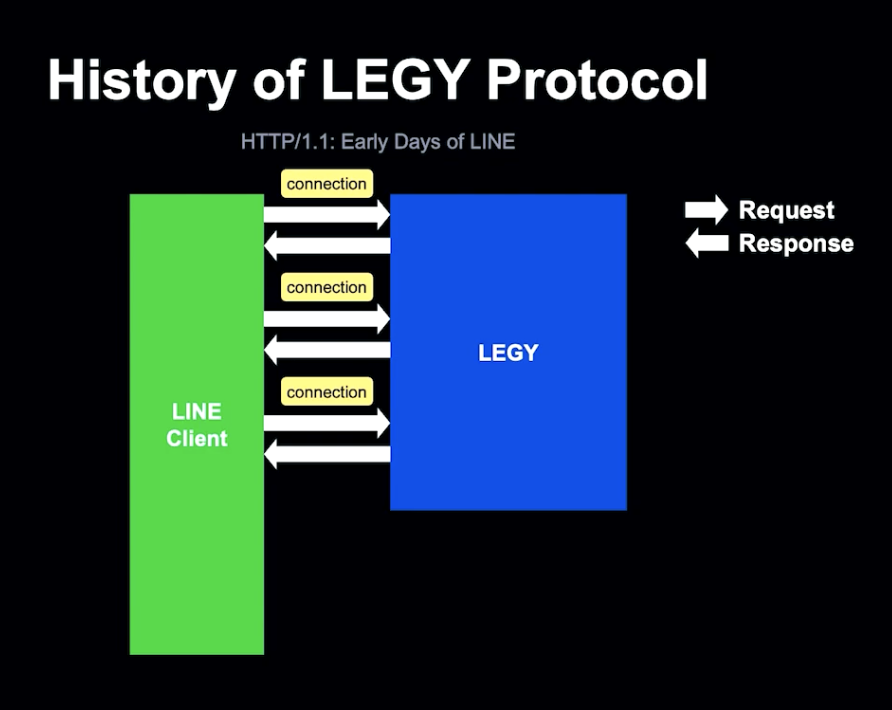
LINE이 2011년 처음 서비스를 시작할 때, LINE은 HTTP 1.1을 사용했습니다.
LINE의 주요 기능 중 하나는 Client에 새로운 메세지가 도착했다는 것을 HTTP 1.1을 통해 알리는 것이었습니다.
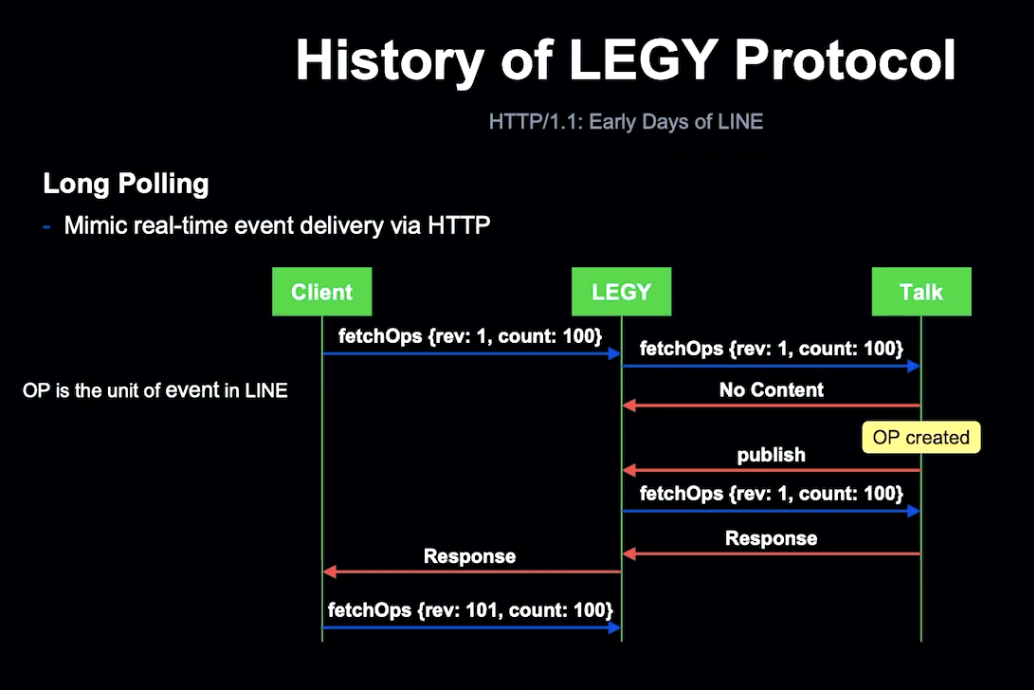
이를 위해 Long Pooling 테크닉을 사용했습니다. Client는 작업을 변환하는 API인 fetchOps를 통해 작업을 동기화합니다.
LEGY는 Client 요청을 받은 직후 Talk 서버로 전달합니다. Talk 서버가 응답하지 않는다면, LEGY는 Talk 서버로부터 Publish 요청을 기다리게 됩니다. 새 작업이 생성된 후, Talk Server는 LEGY로 Publish 요청을 하게 되고, Publish를 가져온 LEGY는 fetchOps를 Talk Server에 다시 송신하고, 응답을 Client로 보냅니다.
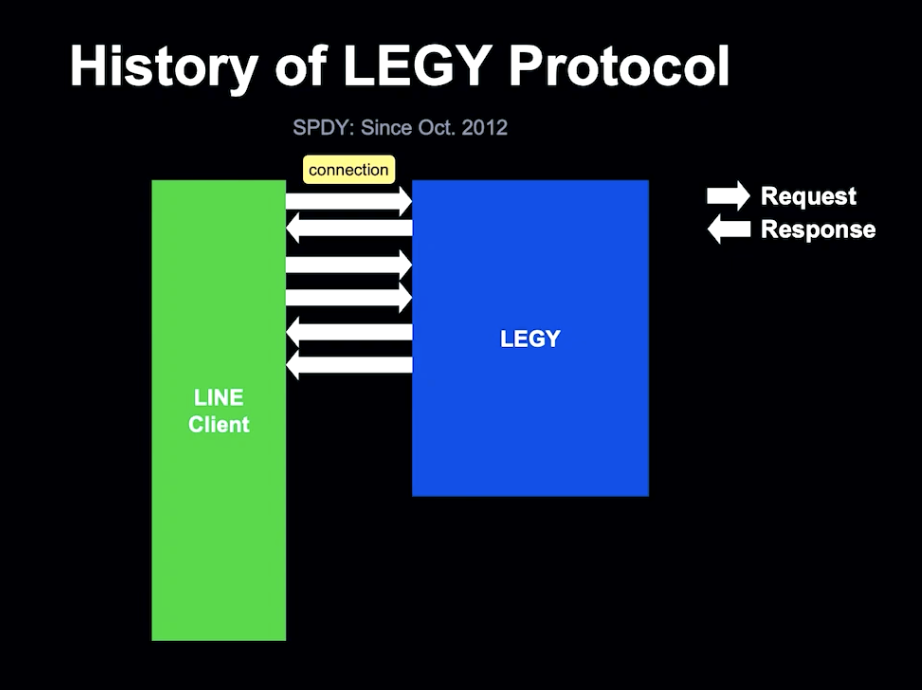
2012년 말부터 LEGY는 HTTP/2에 기반한 SPDY를 사용하게 되었습니다.
HTTP 1.1과 다르게 SPDY는 하나의 TCP 커넥션을 설정하고, 여러 요청과 응답이 하나의 커넥션에서 다중화됩니다.
HTTP Header 압축을 통해 네트워크 대역폭을 줄일 수 있었지만, LEGY의 메모리 사용량이 높아지고 동일한 Http Header가 존재할 가능성이 있었습니다.
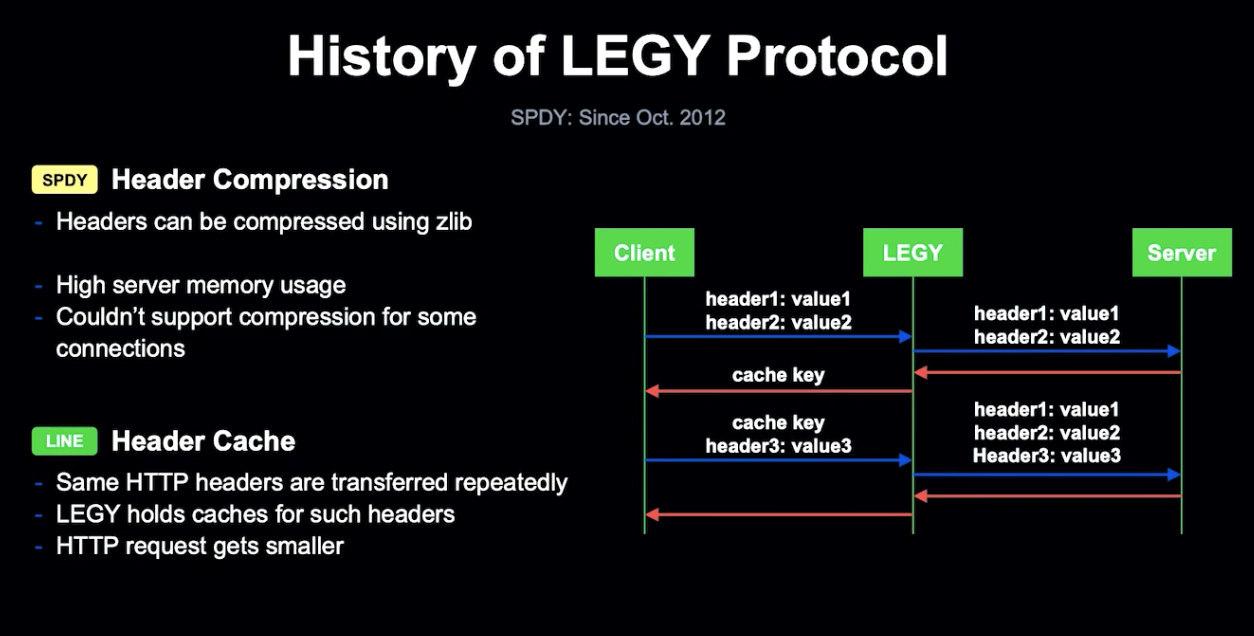
네트워크 대역폭과 메모리를 줄이기 위해 LEGY의 반복적 요청을 캐싱하게 되었습니다.
LEGY가 요청을 받으면 메모리에 캐시 가능한 Header를 보유하고, Client에 Cache Key를 반환합니다.
Client는 반환된 Cache Key를 Http Header에 첨부하여 LEGY가 BackEnd Server에 요청하기 전 Cache를 복원할 수 있게 합니다.

SPDY의 두 번째 개선점은 Server Push로, 단일 요청에 대해 여러 응답을 가능하게 합니다.
Server Push를 통해 추가 리소스를 확보하여 빠른 웹페이지 렌더링을 하는 것이 목표였지만, 결국 Server Push를 위해서는 Client의 요청이 필요했습니다.
일부 LINE 서비스는 Subscription Push 패턴이 필요했지만, SPDY 스펙에서는 유효하지 않은 방법이었고, 기존 fetchOps 방식은 해당 방식이 아닌 Long Pooling 방법을 사용하고 있었습니다.

SPDY는 보안을 위해서 TLS의 사용이 장려됩니다. 하지만 도입 당시 3G 네트워크의 속도 문제로 인하여 Wi-fi 네트워크에서만 TLS를 사용하고, 모바일 네트워크에서는 자체 암호화 방식인 LEGY Encyrption을 도입했습니다.
LEGY Encryption에서는 민감한 Header를 본문으로 이동시켜 암호화하고, Header에는 암호화 메타데이터를 추가하여 전체 연결이 아닌 Message Body와 민감한 헤더만 암호화하는 방식을 사용했습니다.

하지만 SPDY는 더 이상 사용되지 않는 기술이기 때문에 자체 SPDY 코드를 개발 및 관리해야 했습니다.
또한 표준이 아닌 프로토콜이기 때문에, 네트워크 디버깅이 어려워지는 단점이 있었습니다.
TLS가 사내 암호화 방식보다 안전하지만, 모든 커넥션을 사용하지 않는 문제점이 있었습니다.
LINT

더 신뢰할 수 있고, 안전한 LINE 서비스를 위해 LINT(LINE Improvement for Next Ten years)가 다음 10년을 준비하기 위한 프로젝트가 되었습니다.
LINT의 목표는 기존 SPDY 프로토콜을 HTTP/2로 교체하고, 표준을 준수하는 Push Mechanism을 사용하며, 모든 연결에 TLS를 도입하는 것입니다.
Migration to HTTP/2

SPDY를 표준 HTTP/2로 변경하게 되면 HTTP/2의 Header 압축 방식인 HPACK이 있기 때문에, 더 이상 헤더 캐시를 사용할 필요가 없습니다.
그럼 지금부터 LINE에서 어떻게 HTTP/2로 Migration 되었는지 말씀드리도록 하겠습니다.

Migration을 실패하게 만드는 요인엔 서버 쪽 원인과 클라이언트 쪽 원인이 있습니다.
수정하는 데 오랜 시간이 걸리는 버그를 수정하는 가장 좋은 방법은 수정될 때까지 HTTP/2를 완전히 비활성화하는 것입니다. 이를 위해서 클라이언트가 HTTP/2를 사용하지 않도록 제어하는 기능이 필요했습니다.
클라이언트 쪽에서 HTTP/2를 사용하지 못하는 버그가 발생할 경우엔, 클라이언트가 HTTP/2가 아닌 SPDY도 사용할 수 있게 하는 기능이 필요했습니다.
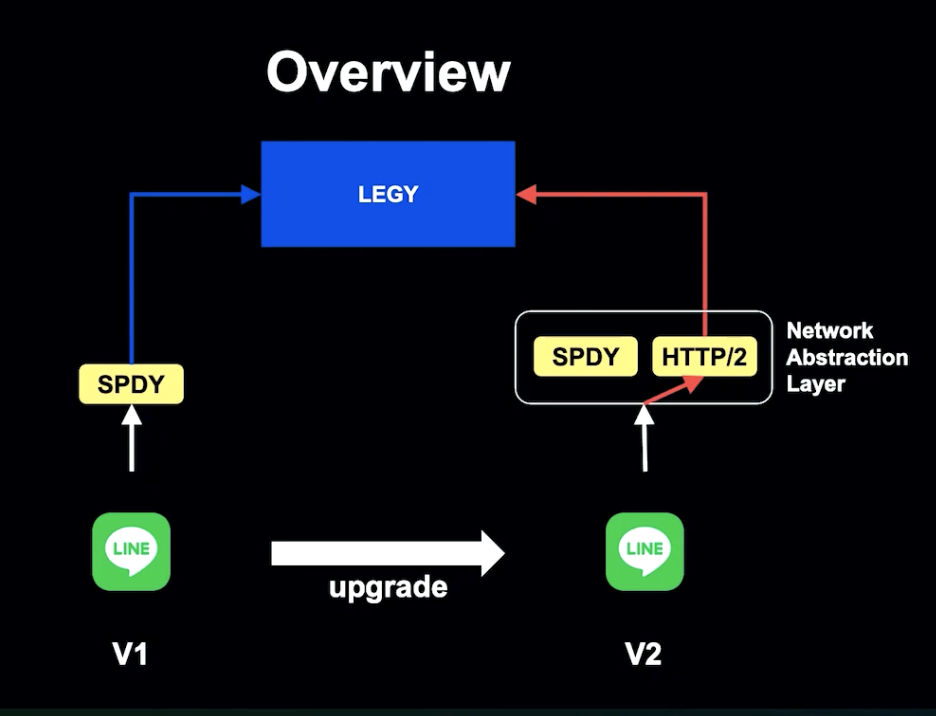
네트워크 추상화를 통해 Client는 어떤 프로토콜로 처리할지 자율적으로 설정할 수 있게 되었습니다. 이는 다른 프로토콜로 업그레이드 시에도 유용하게 사용할 수 있습니다.
문제가 발생할 시 추상화 계층이 감지하고 SPDY로 전환하게 되고, Client는 기존과 같이 서비스를 사용할 수 있게 됩니다.
HTTP/2를 비활성화해야 하는 경우엔 외부 Config가 업데이트되고, 업데이트된 Config는 Client 추상화 계층으로 전파하여 사용 가능한 목록에서 HTTP/2를 제외하게 됩니다. HTTP/2를 다시 활성화할 경우 다시 HTTP/2가 사용됩니다.

Client를 Config하기 위해서는 LEGY에 정의된 Connection Info가 필요합니다. Client는 이를 가져와 Network behavior를 결정합니다.
Connection Info는 HTTP 사용을 고려하기 전부터 사용 중이었습니다. 왜 그랬을까요?

이는 신뢰도를 위한 것이었습니다.
LINE은 글로벌 서비스이기 때문에 전 세계의 여러 개의 LEGY PoP 중 적절한 위치에 연결해야 하고, 국가별 네트워크 특성이 다르기 때문에 동일한 정책을 사용하는 것은 불가능합니다.
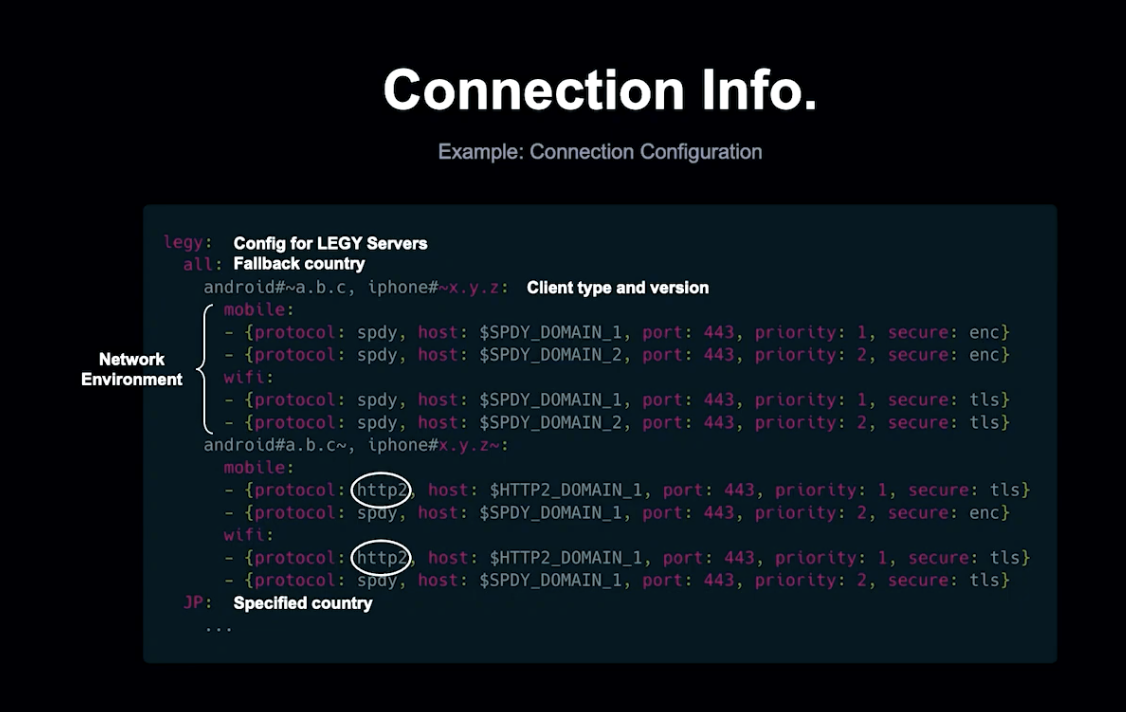
각 클라이언트는 실행 플랫폼에서 성능 최적화를 위해 고유한 Config를 컨트롤하여 다양한 유형(국가, Client, Version)에 맞게 조정할 수 있습니다.
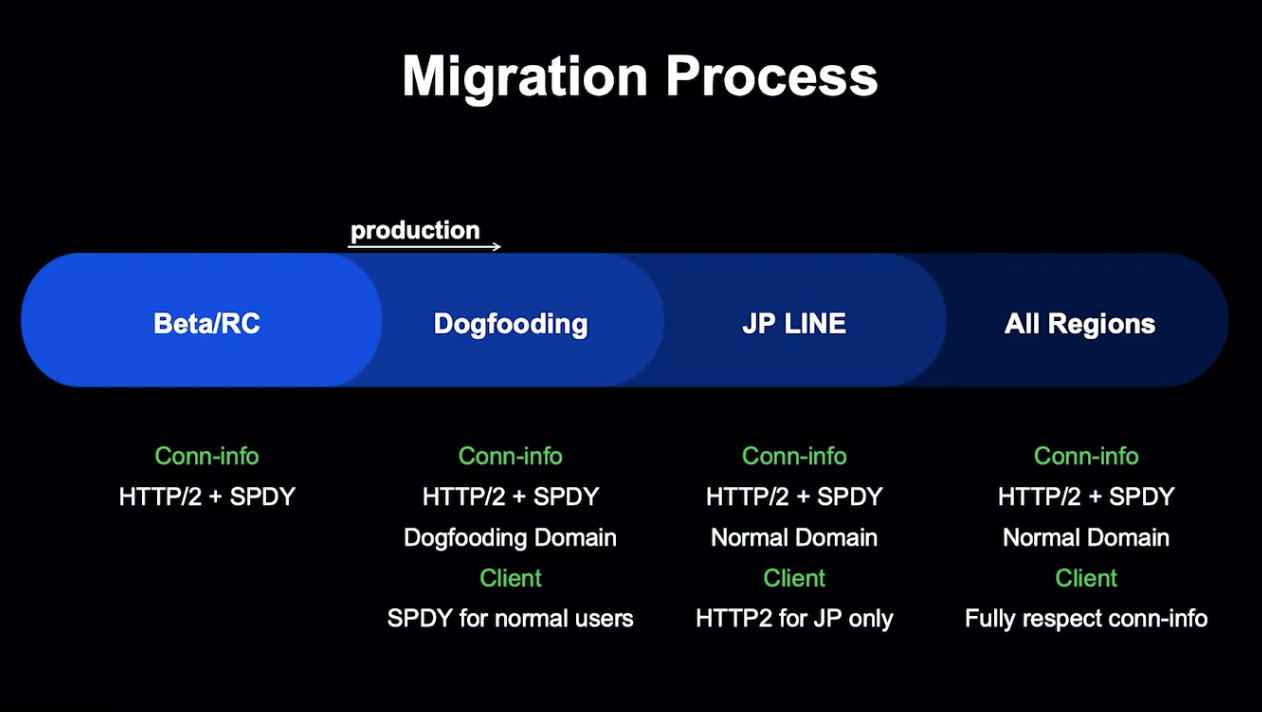
Beta -> 사내 테스트 -> JP Line -> 모든 지역 순으로 Migration을 진행하였습니다.
현재 LINE의 80% 이상의 Client가 HTTP/2를 사용 중이며, SPDY 코드를 완전히 제거하기 위한 준비 중입니다.
Streaming Push

Streaming Push는 HTTP/2 표준을 따라야 하고, 사용하기 쉬워야 하며, 요청하지 않은 Push를 사용 가능해야 합니다.

HTTP/2는 Push From Frame을 정의합니다.
Push를 보내기 전, Server는 PUSH_PROMISE를 Client에 전송하여 PROMISE의 존재를 알리고, 각 PUSH는 별도의 Stream으로 전송됩니다.
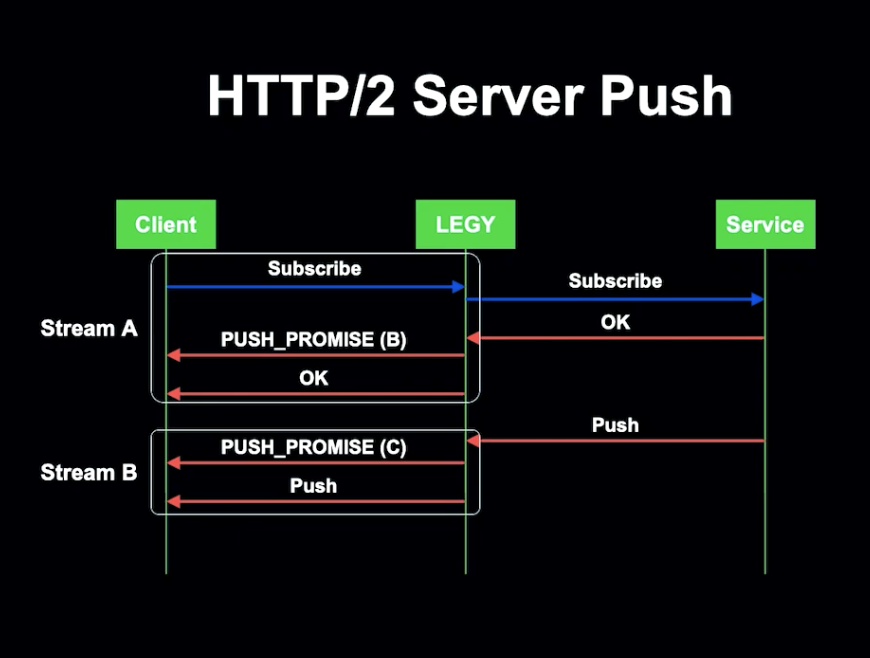
LEGY는 Push Promise를 모든 전송 Subscription 응답과 함께 전송합니다. 각 Push는 다음 Push를 위해 Push Promise를 전송합니다.
하지만 HTTP/2 표준에 따르면 Push Promise는 Client 요청 스트림에서 사용되어야 하기 때문에, 이 Push 모델은 표준을 준수하지 않는 모델이었습니다.
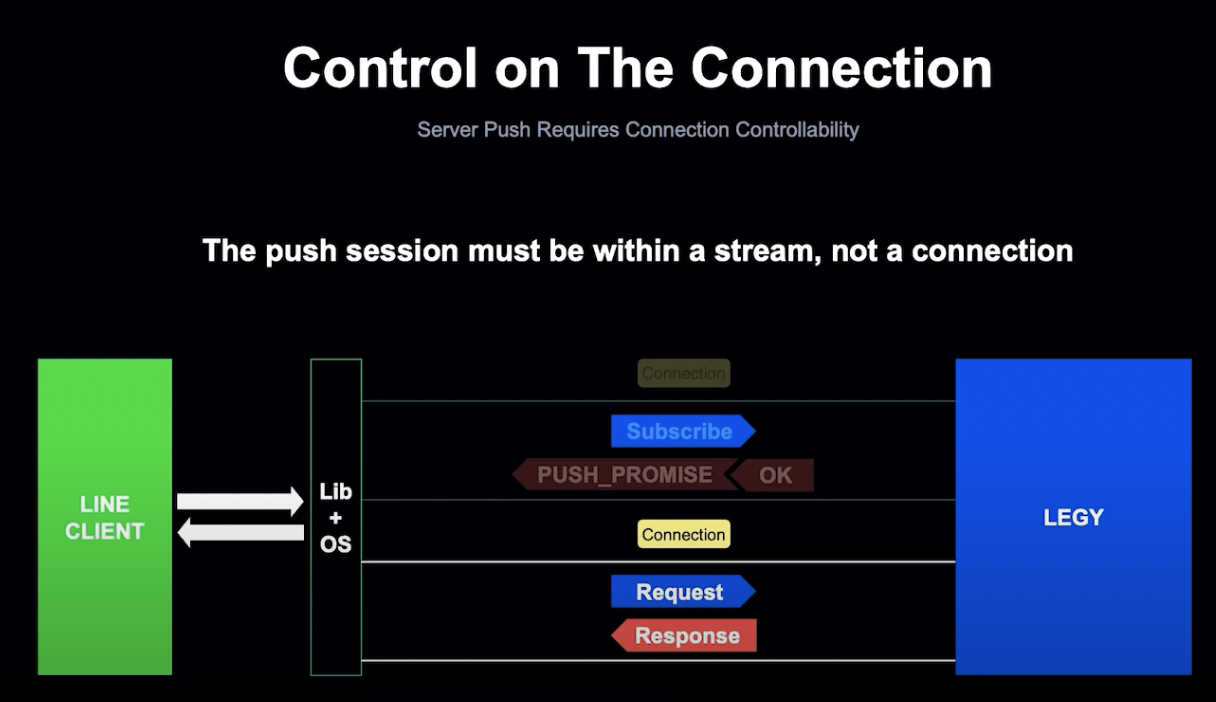
표준 준수 이외에도 고려해야 할 사항이 있었는데, Client가 이전 Push Model을 사용한다고 해도, 연결은 라이브러리나 OS가 제어하게 됩니다.
Push를 받기 위해서는 Client가 Subscription Request를 보내야 하는데, Client가 연결을 제어할 수 없기 때문에 라이브러리나 OS는 Request가 전송된 이후에 연결을 받게 됩니다.
LEGY 쪽에서는 Client가 연결이 끊기고 Subscription이 무효화되는 것으로 보이기 때문에, Push를 보낼 수 없게 됩니다. 하지만 Client는 여전히 Subscription이 살아있다고 믿고 있기 때문에 문제가 발생하게 됩니다.
Client에서는 연결 시작, 중지, 완료 시기를 결정할 수 있어야 하고, 따라서 Push Session을 Stream에서 생산하여 LEGY가 세션 자체가 종료되지 않는 한 언제든지 Push할 수 있도록 해야 합니다.

이것이 바로 Chunk 전송이 필요한 이유입니다.
LEGY는 Subscription 요청에 Chunked 전송으로 응답하게 되는데, HTTP/2에서는 본문을 여러 데이터프레임으로 나누어 Stream으로 다중화하여 Data Stream을 지원합니다.

이러한 HTTP/2의 Streaming Push를 사용해 별도의 변경 없이 표준을 준수하며 Push와 Unsolicited Push를 지원할 수 있게 되었습니다.
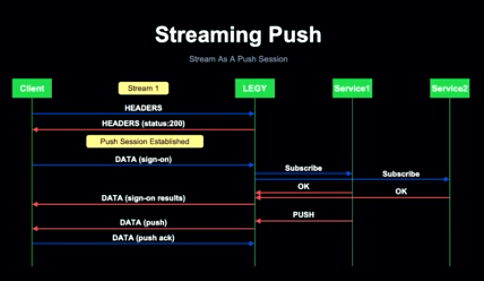
Client가 특정 경로에 대한 Stream을 열면 Client와 Server 둘 다 해당 스트림이 스트리밍 푸시에 사용된다는 것을 알게 됩니다.
LEGY는 200 Header를 수신하여 Push Session이 열린 직후 응답하고, Subscription 요청은 Sign-on 데이터로 세션 내에서 전송됩니다.
LEGY는 필요한 서비스를 Subscription 후 Client에 반환하고, 서비스가 Push Data를 보낼 때마다 LEGY는 Unsolicited Push를 Client에 보내고, Push 유형에 따라 Client는 Push Ack에 대한 승인을 LEGY로 보낼 수 있게 됩니다.
Long Polling 시에는 Client는 Sign-on 결과를 수신할 때마다 보내야 하기 때문에 fetchOps는 세션이나 별도 스트림 내에서 작동하게 됩니다.
TLS

앞서 TLS와 LEGY 암호화를 사용하여 암호화를 한다고 말씀드렸습니다.
TLS가 왜 느렸는지, LEGY 암호화를 어떻게 대체했는지 말씀드리겠습니다.
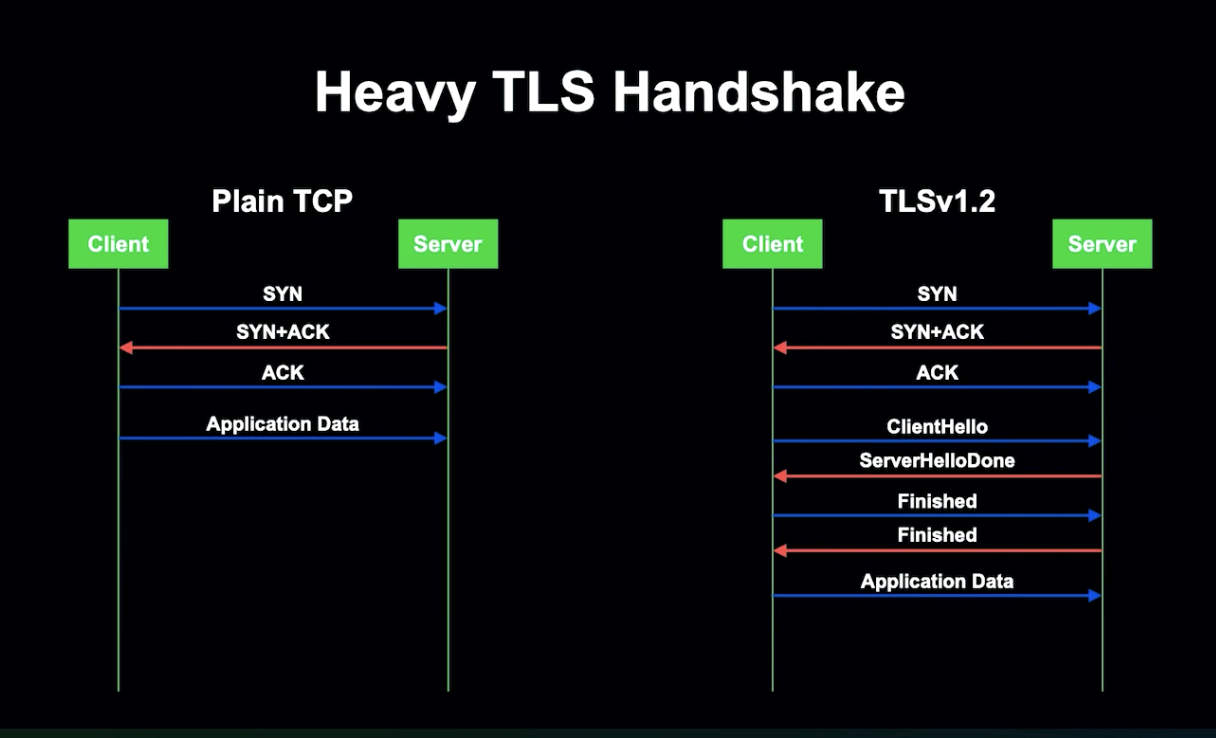
TLS는 프로토콜에 관계 없이 TCP를 Transport로 사용하고 있습니다.
일반적인 TCP는 간단한 3 Way Handshake 기법으로 1 RTT가 소요되며, 애플리케이션 데이터 또한 즉시 전송됩니다. 레기 전송 암호화는 일반 TCP를 사용하고 있습니다.
TLSv1.2는 데이터 전송 전에 TLS 세션에서 TLS Handshake를 수행해 암호화 파라미터를 협상해야 하는데, 협상을 위해서는 2개의 추가 RTT 수행되어 네트워크가 느려지게 됩니다.

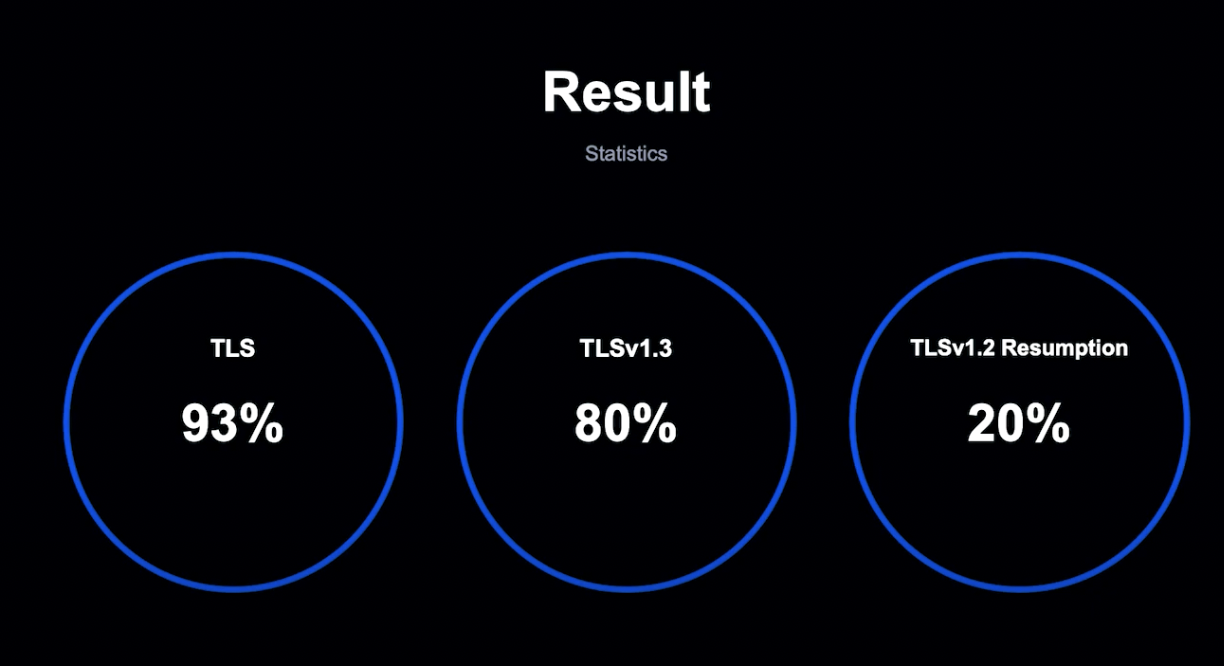
TLSv1.3에서는 협상 Handshake를 개선하여 비용이 1RTT로 줄어들었습니다. TLSv1.3을 도입하여 REGY 암호화 사용을 대체하려고 했으나, 20%의 서비스는 아직도 TLSv1.2를 사용하고 있었기 때문에 완벽한 해결 방법은 아니었습니다.
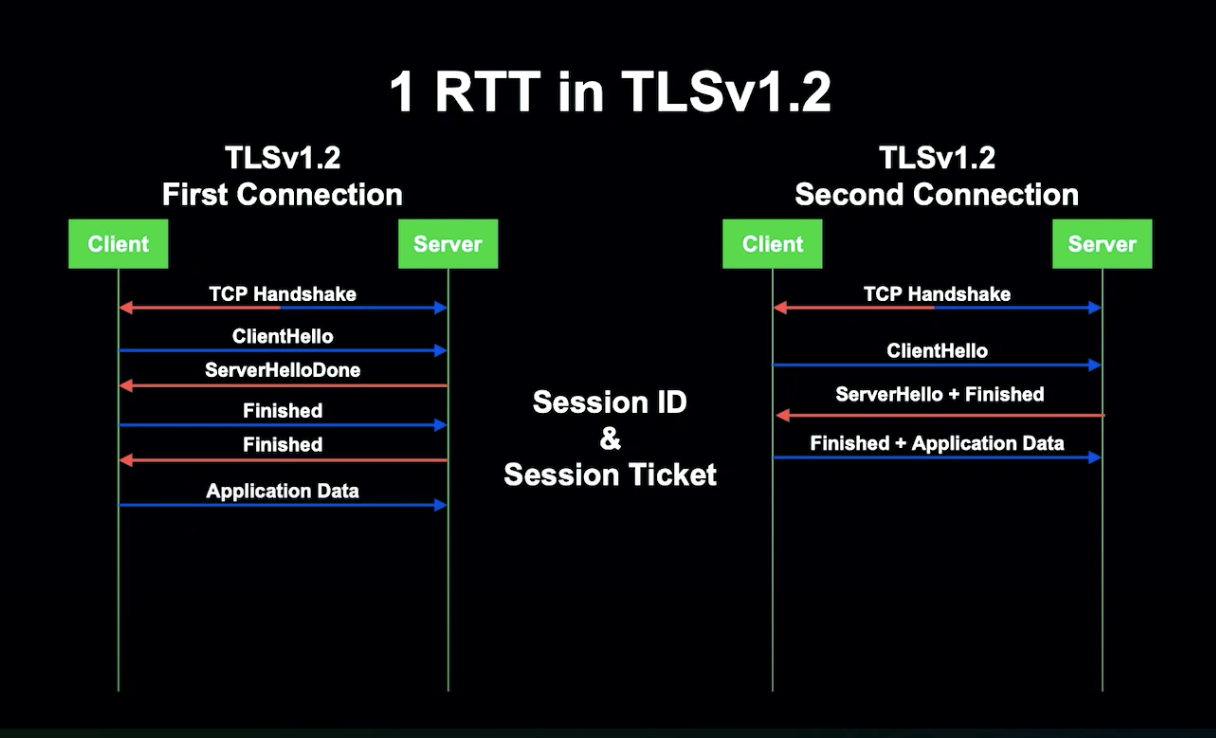
그렇다면 TLSv1.2에서 1RTT 협상을 할 수는 없을까요?
서버에 다시 연결될 때 첫 번째 연결에서 사용한 암호화 파라미터를 재사용한다면 어떨까요? Client 서버가 세션 정보를 기억해 재사용한다면요?
이를 세션 재개라고 합니다. 세션 재개를 위해선 Session ID와 Session Ticket이라는 기술이 필요했습니다.
Session ID는 서버에 암호화 파라미터를 저장하고 각 세션에 ID를 부여하는 방식입니다.
Client가 다시 REGY에 연결하려고 하면 다른 서버에 연결할 가능성이 높은데, 그럴 시 LEGY는 Session ID를 알지 못하기 때문에 다시 Handshake를 수행해 2 RTT의 비용이 들게 됩니다.
Session ID의 작동을 위해서는 모든 인스턴스가 Session Storage를 공유해야 합니다. 각 세션은 Rendezvous Hashing을 사용해 Redis Instance에 저장되고, Client가 재연결 요청 시 서버에서는 세션 정보를 복원한 후 Handshake를 1 RTT로 완료할 수 있게 됩니다.
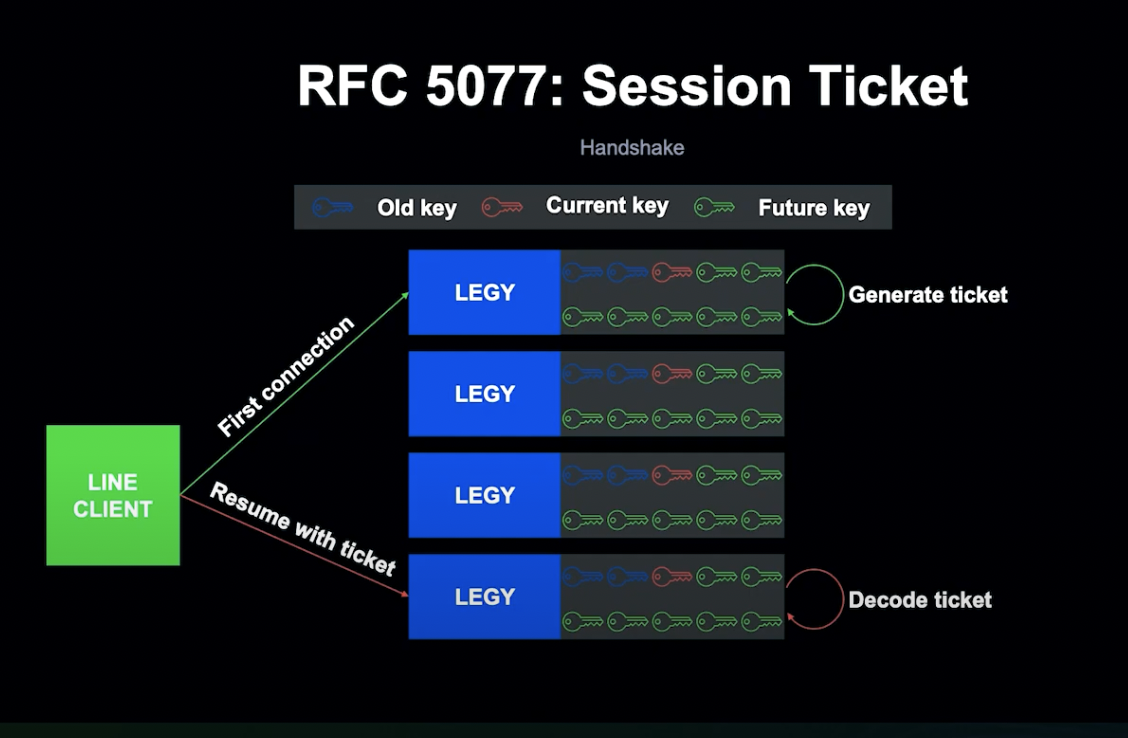
하지만 Session ID는 모든 세션에서 ID를 저장해야 하기 때문에, 리소스 사용을 줄이기 위해 Session Ticket 기술도 같이 사용하게 되었습니다.

ID와 다르게 세션 티켓은 Stateless 방식입니다.
LEGY는 Ticket이라는 세션 데이터를 생성해 클라이언트에게 Return하고, Client는 LEGY가 추출한 세션 정보와 Ticket을 결합합니다.
Ticket은 LEGY Secret Key로 암호화되어 Client가 조작할 수 없고, Key가 없는 상황을 방지하기 위해 LEGY는 키를 미리 Provisioning합니다. 이를 통해 Instance 간의 키 동기화가 쉬워지게 되고, Server-Side는 Key 관리만 하면 됩니다.
Client가 두 번째로 접속하면 Ticket을 LEGY로 전송하고, LEGY는 이를 검사합니다. 성공 시 LEGY는 Ticket에서 세션 정보를 추출하여 Client와 연결하게 되고, 오직 Ticket이 만료될 시에만 TLS Handshake를 수행하게 됩니다.
현재는 모든 서비스가 TLS 세션 재개를 사용 중이고, 모바일과 Wi-Fi 상황에서도 TLS 지원 준비 중입니다.
마무리

LINE은 안정성, 확장성, 보안성을 통한 좋은 유저 경험이 양질의 서비스의 핵심이라는 것을 알고 있습니다.
좋은 유저 경험을 위한 목표의 첫 단계로서 네트워크 스택을 개선했습니다.
보안성을 위하여 TLS를 적극적으로 도입했습니다. 성능 개선을 위하여 TLSv1.2, TLSv1.3, Session ID, Session Ticket 등의 다양한 기술을 사용했으며, 연결의 93%를 TLS로 개선했습니다.
안정성을 위하여 오래된 SPDY 프로토콜을 걷어내고 표준 HTTP/2를 채택했습니다. 연결의 85%가 HTTP/2를 사용 중이며, 곧 모든 Client가 HTTP/2를 사용하도록 할 계획입니다.
확장성을 위하여 Streaming Push 메커니즘을 개발했습니다. Long Polling, Subscription 요청을 마음대로 처리하고, Long Polling의 Migration이 가능하게 되었습니다.
네트워크는 끊임없이 변화합니다. LINE은 변화하는 네트워크 환경에 발맞추어 연결성을 지속적으로 확장시킬 것입니다.
LINE 앱을 위한 확장 가능한 멀티 데이터 센터 ID 제너레이터 - Masahiro Ide

LINE Messaging Application
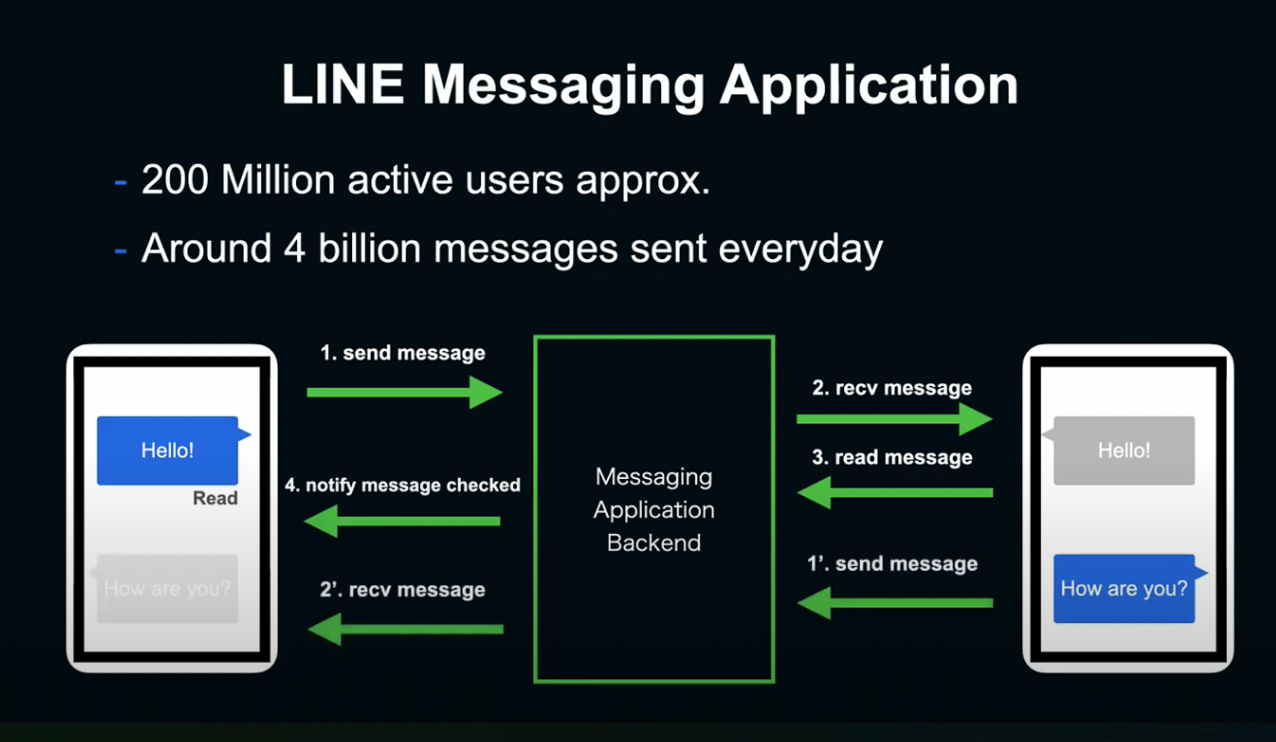
LINE에서는 하루에 2억 유저명의 40억 개의 메시지를 주고받습니다.
LINE은 전형적인 Client-Server 모델로, User가 보낸 메세지는 BackEnd로 전송되고, Backend는 수신자에게 메세지를 전달합니다. 메세지를 수신한 Client는 메세지 확인을 송신 측에 통지하게 됩니다.
이런 과정이 초당 약 4~5만개 발생하게 됩니다.
Generate Message ID
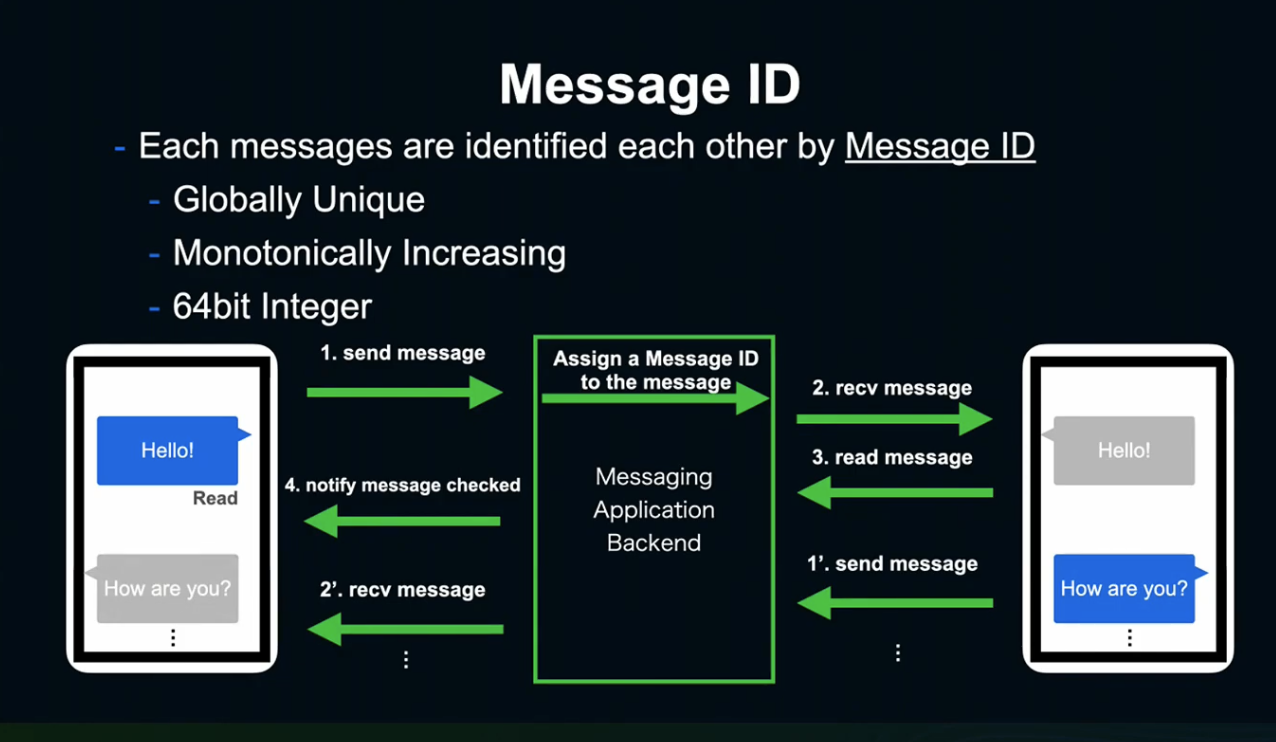
LINE이 정한 Message ID의 생성 규칙은 단일하고, 64bit에, 형식을 보존하며 증가하는 방식이었습니다.
ID는 메세지가 송신자에게 보내질 때 Backend 서버에서 아이디를 할당받아 수신자와 송신자에게 전송되는 형태를 취하고 있습니다.

ID 생성에서 요구되는 사항은 빠르고, 단순하며 유지비용이 낮아야 한다는 것이었습니다.
요구사항을 충족시키기 위해, 이미 다수의 서비스에서 사용 중이던 Redis를 선택하게 되었습니다.

요구사항을 충족하기 위해서는 Single Master-Replica setup이 가장 간단하고 빨랐습니다. 또한 실제로 Backend에서 필요로 했던 퍼포먼스도 발휘했습니다.
하지만 몇 년동안 운영하다 보니, 이 setup을 정말 믿고 쓸 수 있는지, 확장 가능한지 의문을 갖게 되었습니다.

첫 번째 케이스는 Redis Host가 갑자기 죽는 케이스입니다.
이미 수천 대의 Redis Instance를 운영하는 관점에서는 일상적으로 일어나는 문제입니다.
Master만 죽었을 경우엔 Replica 쪽으로의 Fallback을 하는 것이 간단하지만, Redis는 비동기적 Replication을 실시하기 때문에 Replication이 완료되기 전에 Master가 죽었을 경우 마지막에 생성된 ID를 알 수 없게 됩니다.
만약 복구 시 잘못되어 이미 생성된 아이디의 번호를 부여한다면, ID 중복이 발생하게 되고 복구까지 더 오랜 시간이 걸리게 됩니다. 서버 운영 상으로는 반드시 회피해야 할 문제입니다.

두 번째 케이스는 여러 개의 네트워크에 걸친 LINE에서는 종종 발생하는 문제입니다. 네트워크 문제로 Master-Replica와 Backend가 분단되면 ID 생성을 실시할 수 없고, 최종적으로는 메세지를 송신할 수 없습니다.
문제 해결을 위해서는 네트워크 분단이 해결될 때까지 기다려야 하는데. 얼마나 오랜 시간이 걸릴지 아무도 모르고, 해결될 때까지 유저는 대화할 수 없게 됩니다.
How to fix it?

ID는 단일하고, 단조롭게 증가해야 합니다. 또한 ID에 의존하거나 ID를 사용하는 기존 기능들이 많기 때문에, Breaking Change가 없어야 합니다. 또한 네트워크 분단과 같은 하드웨어 장애에 내성을 가지기 위해서는 높은 확장성이 필요했습니다.

요구사항을 만족하면서 확장성이 높은 방법은 없을지 찾다 보면, 트위터가 선택한 Snowflake ID Format에 도달하게 됩니다.
Snowflake는 3가지 요소를 통해 요구사항을 층족합니다.
-
Timestamp - 1ms별로 갱신되는 필드로, 단조롭게 증가하는 성질을 만족합니다.
-
WorkerId - 생성한 Worker를 표시합니다.
-
Sequence - 같은 Timestamp, 같은 Worker에서 생성된 ID를 Unique하게 만듭니다.
이러한 Snowflake를 그대로 시스템에 적용해도 되지만, 저희는 조금 바꾸어서 적용하기로 했습니다.
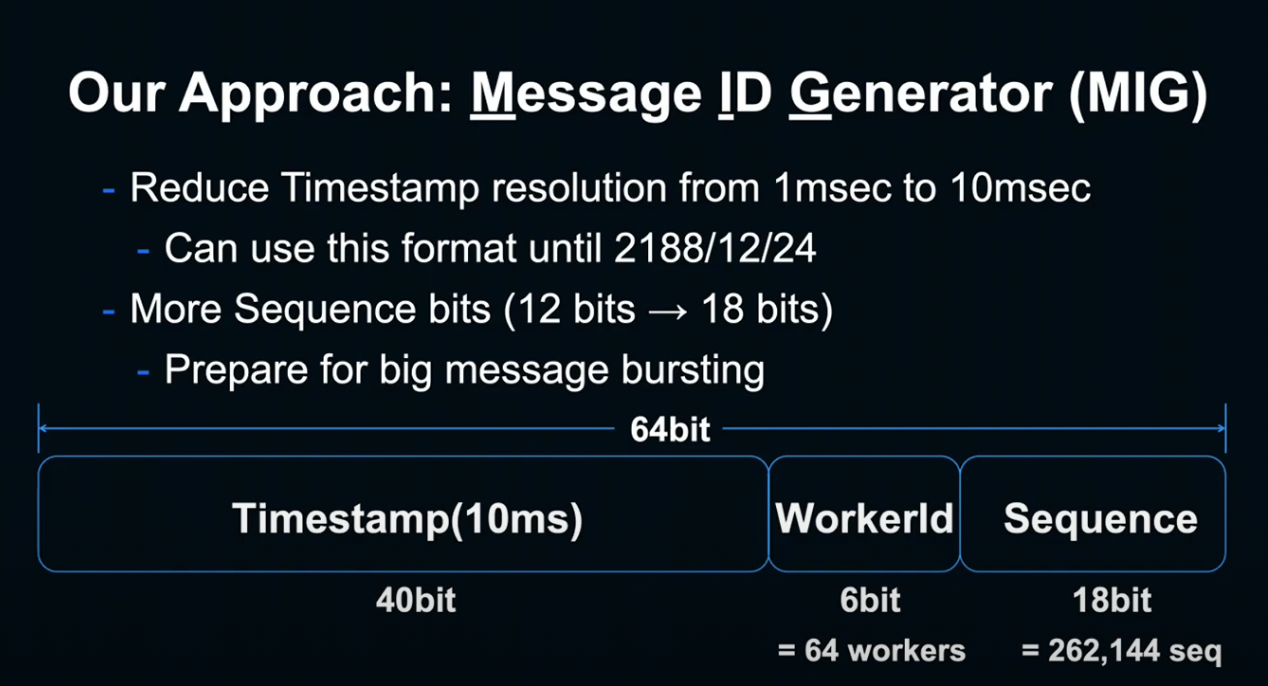
MIG(Message ID Generator)라는 이름으로, Snowflake와 두 가지 다른 점이 존재합니다.
첫 번째는 Timestamp의 간격입니다. 1ms였던 간격을 10ms로 변경해, 원래 69년만 사용 가능하던 Timestamp를 약 200년간 이용할 수 있게 되었습니다.
두 번째로 Sequence를 18bit로 변경했습니다. 하나의 Worker에서 10ms 안에 생성할 수 있는 간격을 늘려, 갑작스러운 메세지 증가에 대응했습니다.

하나의 Redis Master-Replica setup과 달리 MIG에서는 여러 대의 MIG를 나열시켜 Load Balancing을 할 수 있게 되었고, 모든 Host 간의 단조로운 증가를 보장할 수 있게 되었습니다.
State 공유가 없기 때문에, MIG가 죽더라도 다른 Instance에서 이어서 할 수 있고, 간단히 Host를 추가할 수 있습니다.
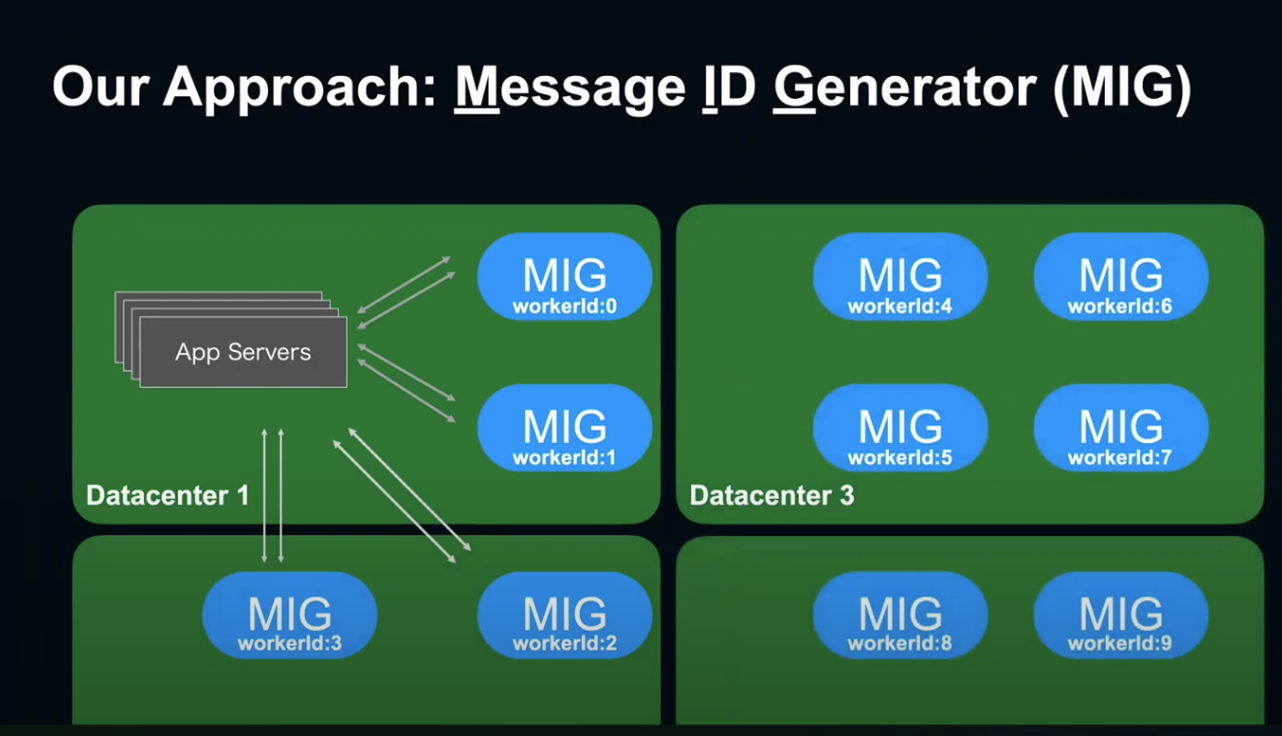
하나의 데이터 센터에만 있었던 ID Generator를 여러 개의 데이터 센터에 간단히 배치할 수 있게 되었고, 아까 말씀드린 문제점들도 해결할 수 있게 되었습니다. 굉장히 해피😀한 상태이죠.
But..

하지만 ‘MIG를 도입함으로서 Client-Backend 간에 중복이 없고 단조롭게 증가하는 ID를 사용할 수 있다’는 가정이 무너지는 현상이 발생하게 되었습니다.
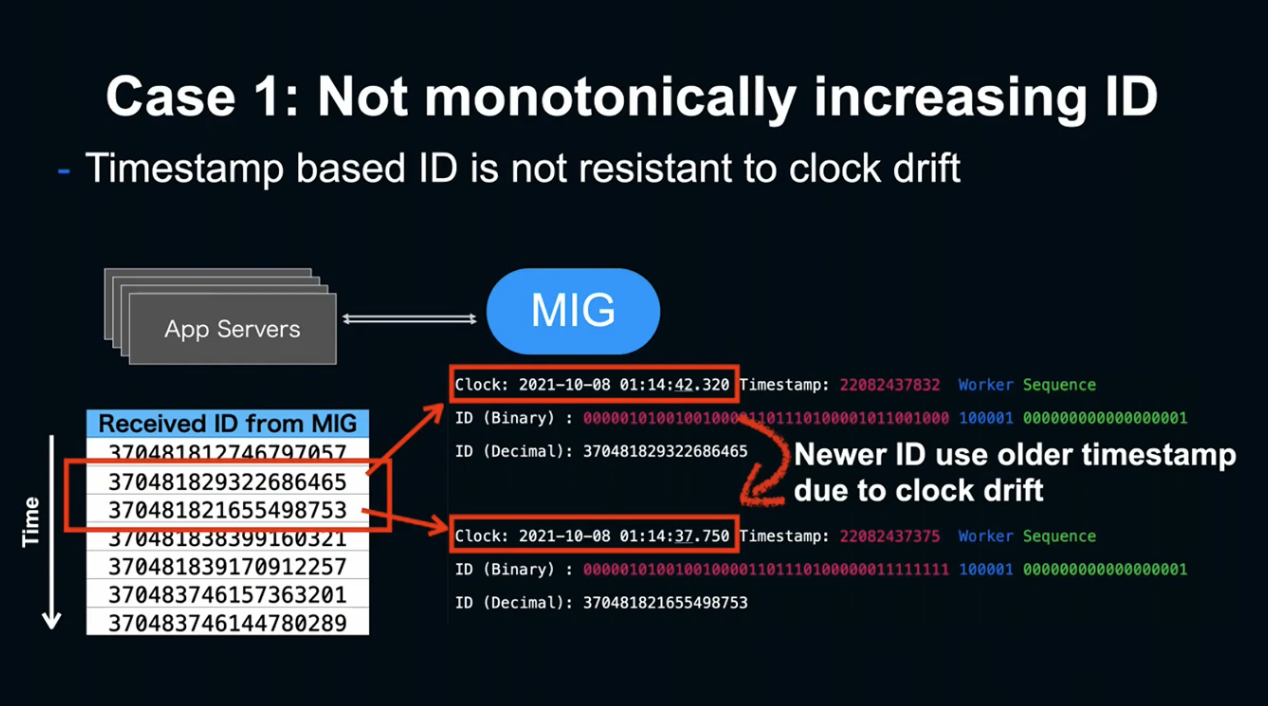
첫 번째 케이스는 아이디가 단조롭게 증가하지 않는 문제입니다.
Timestamp 기반의 증가는 윤초나 NTP에 의한 시간 조정이 발생하면 단조성이 깨지는 문제가 있었습니다.
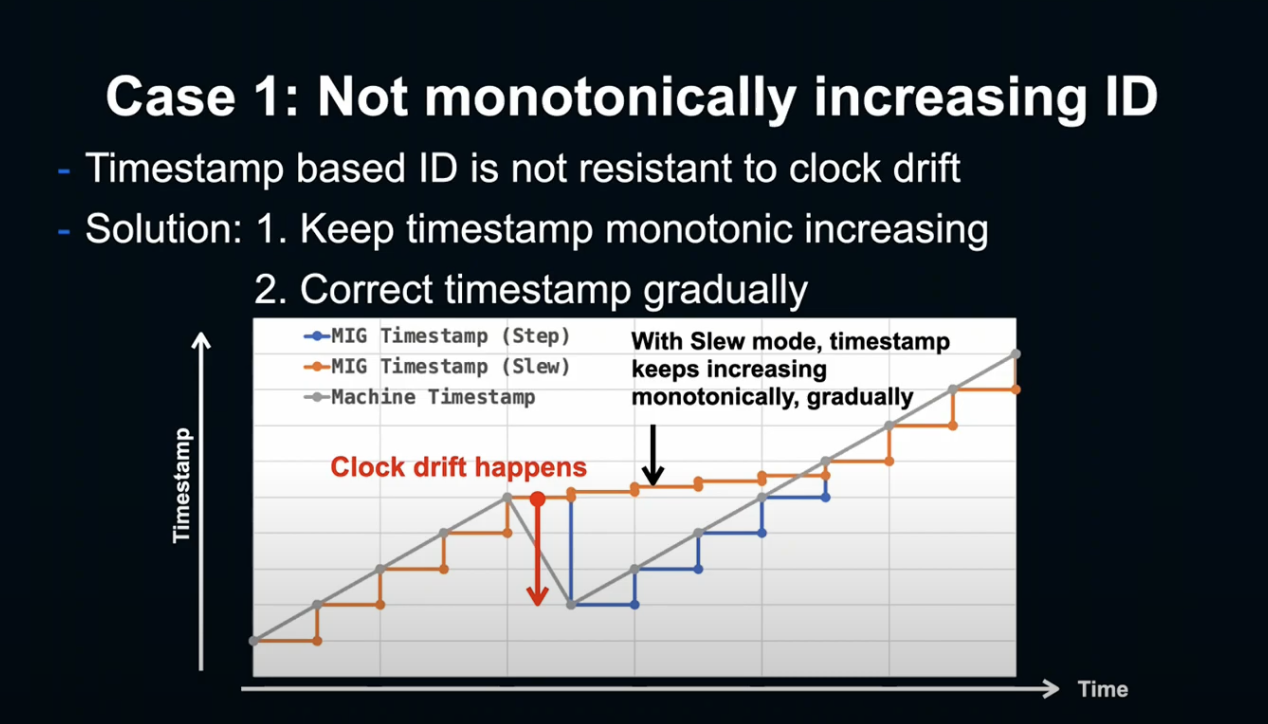
이 문제는 Clock Drift 발생 시, 실제 Timestamp(회색 선)을 MIG Timestamp(파란 선)이 갑자기 따라감으로서 발생되는 문제입니다.
그렇기 때문에 NTF 서버의 Slow mode처럼 Timestamp가 서서히 증가하여 올바른 Timestamp로 수정하는 방법을 사용했습니다. 이 방법을 사용하면 언젠가는 ID가 단조롭게 돌아오게 되고, 문제 발생 없이 Timestmap를 수정하게 됩니다.
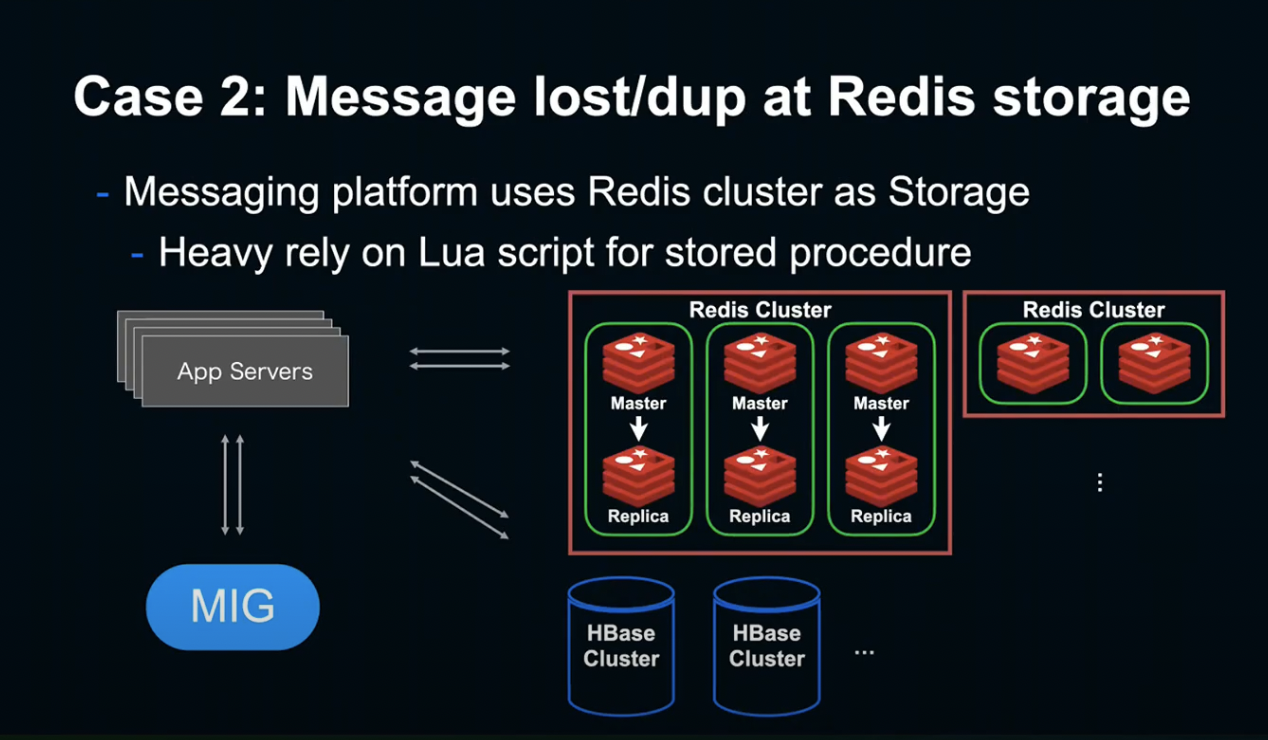
두 번째 케이스는 Backend Storage에서 발생한 문제입니다.
LINE은 HBase나 다른 Storage 이외에 Redis Cluster 여러 개를 Storage로 사용 중입니다.
또한 여러 개의 Redis Command를 Atomic하게 통합하기 위해 Redis Lua Script를 사용해 Storage를 운영 중입니다.

이 Sample Script의 경우 User ID, Last Message ID를 GET해 실제로 Redis상에 저장된 Message Object를 취득합니다.
하지만 실행을 해보면, 뭔가 이상합니다.
위의 2개의 GET의 경우 실제로 Message Object가 되돌아 왔는데, 실제 Lua Script에서는 아무것도 되돌아 오지 않았습니다. 즉, 메세지가 발견되지 않았다는 것입니다.
이 Sample에서는 결과 메세지가 사라졌지만, 실제로는 랜덤한 아이디에 관한 데이터가 사라지거나, 연동된 데이터가 중복되는 문제가 발생했습니다.
원인을 조사한 결과, Lua 내부에서 문자열 -> 숫자로 데이터를 전환했을 때 전혀 다른 결과를 얻을 수 있다는 사실을 알아냈습니다.
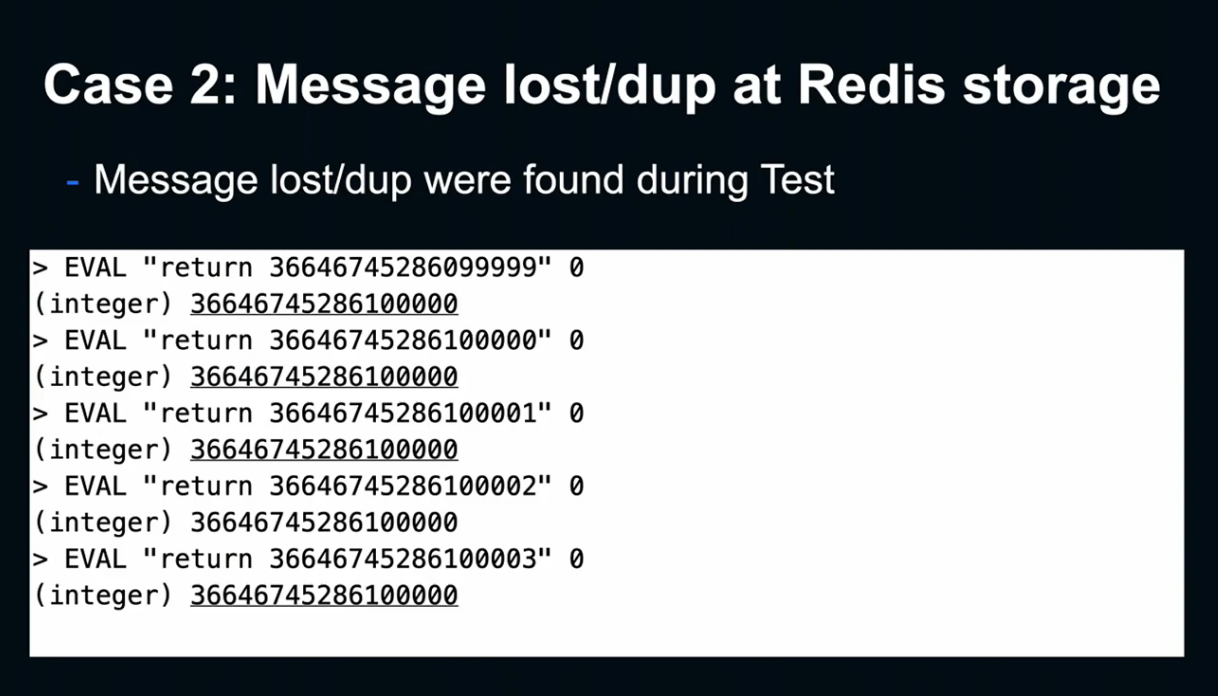
Redis에 포함된 Lua Version의 경우에는 Integer나 Float 전부 Float로 표현하기때문에 MIG에서 생성된 ID를 제대로 표현할 수 없었습니다.
5.3 버전부터는 정수형이 도입되었기 때문에 해결이 되었는데, Version 간 호환성이 없기 때문에 아직 옛날 버전을 사용하고 있습니다.
해결 방법으로는 BigInt를 Lua에서 구현하거나, 수치 변환을 시키지 않고 직접치를 비교하거나, Lua에서 회피 시도를 하는 방식으로 해결했습니다.
그 외에도 많은 문제가 있었지만, 발표 시간이 없기 때문에 자세한 설명은 생략합니다(?)
마무리

LINE은 LifeLINE 플랫폼 신뢰성 향상을 위해 서비스 개시 초기부터 10년간 분산 시스템 기술에 주력해 왔습니다.
앞으로 향후 10년간은 더욱더 분산 시스템을 데이터센터 레벨의 제한을 초월해 확장시키기 위해 필요한 신뢰성을 갖는 시스템 개발을 위해서 노력하겠습니다.
이 세션에서는 그 중 ID Generator의 구현을 설명드렸습니다. Timestamp 기반으로 ID를 생성해 빠르고 멀티 데이터 센터 레벨에서도 높은 확장성을 가능케 했습니다. 또한 과정에서 발생한 버그들도 설명드렸습니다.
여러분도 새로운 기능을 도입하실 때는, Client-Server뿐만 아니라 각각의 내부 구현을 주의 깊게 확인함으로서, 구현할 때는 깨닫지 못했던 점을 발견할지도 모릅니다.
LINE 플랫폼 서버의 장애 대응 프로세스와 문화 - 이수안

Agenda

본 세션에서는 3가지 내용을 소개합니다.
- LINE 플랫폼이 신뢰를 중요시하는 이유
- 문제 발생 시 대응 프로세스
- 이 모든 것을 지탱하는 개발자 문화
LINE Platform Server

시작하기 전, LINE Platform Server에 대해 먼저 소개해드리겠습니다.
LINE 앱의 필수 기능들을 개발하는 이 플랫폼은, 백여 명의 다국적 멤버가 공통의 개발문화를 기반하여 발전시키고 있습니다.
Reliability

유저 생활의 인프라로서, LINE은 신뢰성 있는 서비스를 제공해야 합니다.
신뢰성이란 유저의 기대에 부응하기 위한 것이고, LINE Platform Server는 신뢰성을 가장 중요한 가치로 여깁니다.

저희는 장애는 피할 수 없는 것이라고 생각합니다.
그렇기 때문에 장애를 두려워하는 것이 아닌, 장애를 플랫폼의 신뢰성을 개선하기 위한 귀중한 경험으로 삼는 것이 LINE의 개발 문화입니다.
Outage Handling Process

그렇다면 LINE Platform Server는 어떻게 장애를 대응하고 Handling하는지, 그 체계를 소개하도록 하겠습니다.

LINE Platform 서버에서의 장애 대응을 요약하면 다음과 같습니다.
문제가 감지되면 담당자에게 신속한 연락을 취합니다.
그 후 담당자는 문제를 분류 및 전파하고 수정합니다.
문제가 해결되면 문제 상황을 정리 및 공유하고, 이해 당사자들이 모여 결과를 리뷰하고 개선점을 논의합니다.

장애는 모니터링을 통해 자동 감지되고, 담당자들이 신속히 알게 됩니다. 그렇지 못한 경우, 문제를 확인한 누구든지 담당자에게 연락해 대응할 수 있습니다.
연락 포인트를 관리하여, 누구나 책임자와 보고 채널을 확인할 수 있습니다.

그 다음은 장애 분류 단계입니다. 장애의 영향도에 대한 소통과 사후 관리를 위한 용도로 Product별로 명확한 분류 기준을 가지고 있습니다.
DAU를 기반으로 영향받는 유저 수를 Coverage로 분류하고, 문제가 발생한 기능의 종류 및 형태로 심각성을 결정하여 이 두 정보를 기반으로 레벨을 분류하게 됩니다.

LINE의 서비스는 긴밀한 연관관계를 가지고 있기 때문에, 장애 사항을 신속하게 전파하는 확장 체계가 중요합니다.
담당자들은 정해진 공유 채널을 통해 확장된 장애 정보를 통해 영향도를 확인하고, 대응을 준비합니다.
작성하기 쉽고 누구나 이해할 수 있도록 공유 내용은 템플릿에 기반하여 작성됩니다.

장애 복구는 장애 대응의 핵심 과정입니다. 빠르게 문제의 영향도를 줄이는 방향으로 대응하며, 원인의 파악도 수행하게 됩니다.
장애 관련 부서의 리드가 총 책임을 맡게 되고, 리더의 지시에 따라 멤버들은 대응하며 대응 사항을 리더에게 보고합니다. 장애 처리가 길어지는 경우 추가 상황을 전파하는 것도 리더의 책임입니다. 리더가 모든 것을 할 수 없을 경우에는 공유 담당자를 지정할 수 있습니다.

장애 대응 이후 1 근무일 이내 1차 보고를 하는 것이 원칙입니다.
보고서는 정의된 템플릿으로 작성되며, 정해진 메일링 리스트를 통해 내용을 공유하게 됩니다. 비 개발 부서에서도 이해할 수 있도록 요약 정보를 기술하며, 개발자의 정보 확인을 위해 서비스 상태, 대응 이력 등의 정보도 기술하게 됩니다.
장애에 대해서는 3가지 관점에서 점검하게 됩니다.
-
장애 재발 방지 관점
- 장애 감지 개선 관점
- 장애 대응 자체 관점
각각의 개선 항목들은 Action Item 형태로 개발 Ticket으로 등록되어 관리하게 됩니다.

장애 회고는 장애 복구 이후 5 근무일 이내로 설정됩니다.
가능한 한 많은 사람에게 초대를 보내 참여를 유도하고, 다양한 피드백을 주고받으며 추가적인 개선점을 찾습니다.
이후 보고서 내용을 확정하고 장애 대응을 완료합니다.
개발자 문화

소개해 드린 장애 대응 프로세스는 어느 정도 강제성을 띄고 있는데, 지금까지 이 프로세스가 잘 지켜진 이유는 신뢰성을 우선으로 생각하는 개발자 문화 덕분이라고 생각합니다.
지금부터 신뢰성과 관련된 개발자 문화에 대해서 소개하겠습니다.

개발 품질을 보장하는 가장 좋은 방법은 개발 초기부터 그것을 고려하는 것입니다. 그래서 LINE은 초창기부터 동료 간 엄격한 테스트 문화를 형성되어 도입했습니다. 지금은 테스트 코드 없이는 코드 리뷰가 통과하기 어려운 개발 문화가 형성되었습니다.

LINE Platform 서버는 항시 모니터링이 문제 사항을 감지합니다.
특정 조건에 도달하면 담당 개발자에게 알림이 전달됩니다. 이런 알람을 돌아가며 대응하는 것을 On-Call Duty라고 합니다.
이 제도를 통해 개발자가 문제에 항시 대응하여, 작은 문제가 큰 장애로 이어지는 것을 방지할 수 있는 체제를 운영하고 있습니다.
장애 회고 후 모든 사항은 티켓으로 관리하고, 다른 개발 작업과 동등하게 대응합니다.
이러한 장애 티켓은 장애 대응이 끝나면 관심도가 낮아져 쉽게 기술 부채가 되곤 했습니다.
이를 통해 장애 티켓 관리의 중요성을 깨달았고, OKR 방식을 사용하고 있습니다. OKR 방식에서는 조직의 목표로 장애 티켓 해결을 설정하며, 각 팀에서는 상황에 맞게 목표를 재정의하는 방식으로 공통의 가치를 실현합니다.
2021년 현재 등록된 티켓의 83%가 해결된 상태입니다. 저희는 다른 개발 업무의 부담이 있는 상황에서도 장애 티켓 해결을 위해 노력하고 있습니다.
Outage Handling Case

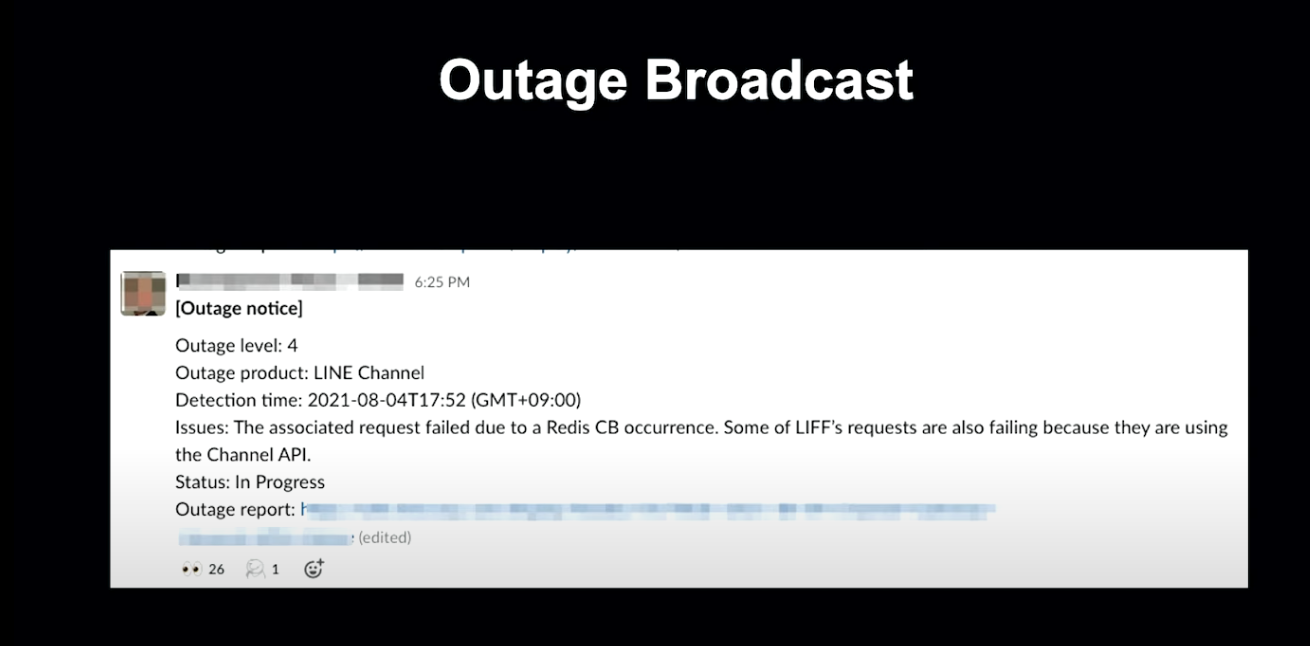
위 장애는 8월 4일에 공유된 장애입니다. 이와 관련된 장애 보고서의 일부를 소개하겠습니다.

장애 대응 보고서의 상단에는 정보가 요약되어 기술되어 있습니다.
왼편에는 분류 정보, 오른편에는 장애 대응의 영향도에 대해서 정리되어 있습니다.
해당 장애는 중계 Proxy 서버의 설정 미스로 인해 Request를 정상적으로 송신하지 못한 Backend 재기동 서버가 불안정한 동작을 했던 장애였습니다.
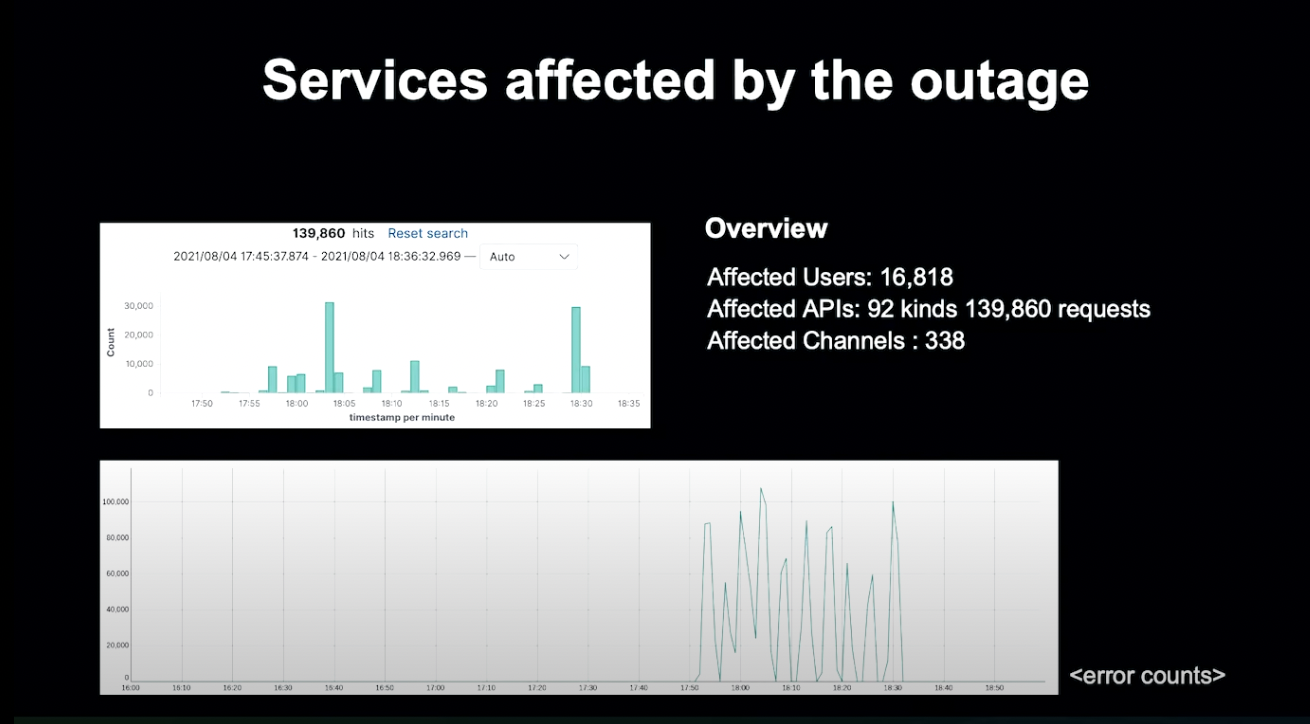
다음으로 상세한 내용을 기술하게 됩니다.
문제 발생 시점의 Log나 Log 발생 양, 실패한 API 등의 Matrix등을 기술하여, 상세한 영향 범위를 적게 됩니다.
영향받은 유저 수나 실패한 API의 종류 등을 기술하여 상세한 상황을 확인할 수 있게 합니다.

장애의 발생과 복구에 관련된 상세한 정보를 타임라인에 기술합니다.
가능한 자세하게 적고, 장애 원인이 된 변경이 발생한 시점, 문제가 발생한 시점, 문제가 인지되고 해결되기 시작한 시점, 복구가 완료된 시점을 기술합니다.

재발 방지를 위해 각 Action Item을 업무용 Jira Ticket으로 관리합니다.
모든 Ticket은 실행 가능해야 하며, 내용은 장애 방지 과정, 장애 탐지 개선 과정, 장애 대응 관점으로 정리됩니다.
이와 같이 LINE은 장애를 통해서 개선책을 찾고, 지속적으로 발전시키고 있습니다.

LINE이 10년간 얻은 교훈들을 말씀드리겠습니다.
첫 번째, 프로세스는 대개 깨지기 쉽습니다. 프로세스는 변화에 맞게 항상 업데이트되어야 합니다. 변화된 프로세스는 영향을 받는 사람들에게 알려져야 활용될 수 있습니다.
두 번째, 프로세스는 문화에 기반합니다. 아무리 잘 정리된 프로세스라도, 인정되고 실행되지 않는다면 아무런 의미가 없습니다.
세 번쨰, 모든 문제는 자율적으로 해결되지 않습니다. Outage Ticket 해결과 같은 문제는 모두가 공감하지만, 실제로는 진척이 쉽지 않았습니다. 현황을 가시화하고 주기적으로 진척을 체크하여 어떻게 해결할지를 논의해 변화를 유도했지만, 쉽지 않아 여전히 도전하고 있는 문제입니다.
마무리
LINE Platform 조직은 유저가 기대하는 LifeLINE 신뢰도를 만족시킬 수 있도록 신뢰도를 중요한 가치로 두고 있습니다.
이를 위해 명확한 문제사항 대비 프로세스를 갖추고, 자발적으로 발전하는 개발자 문화를 통해 신뢰성을 만족시킬 수 있게 하고 있습니다.
이를 통해 장애는 두려워할 것이 아닌, 플랫폼의 신뢰성을 높이기 위한 귀중한 경험이라고 생각하게 되었습니다.
신뢰성의 가치는 LINE Platform Server의 변치 않는 가치입니다. 저희는 프로세스 문화를 지속적으로 가꾸고 발전시킬 것입니다.
TCP로 인한 대규모 Kafka 클러스터 요청 지연 문제 해결 사례 - Haruki Okada

Speaker

안녕하십니까. 저는 Haruki Okada로, LINE에서 Senior Software Engineer로서 Apache Kafka Platform 운영 및 개발을 담당하고 있습니다.
Apache Kafka

Apache Kafka는 분산 Streaming Middleware로, LINE에서 가장 자주 사용되는 Middleware 중 하나입니다.
높은 확장성과 Multi-Tenancy 운영을 지원합니다.
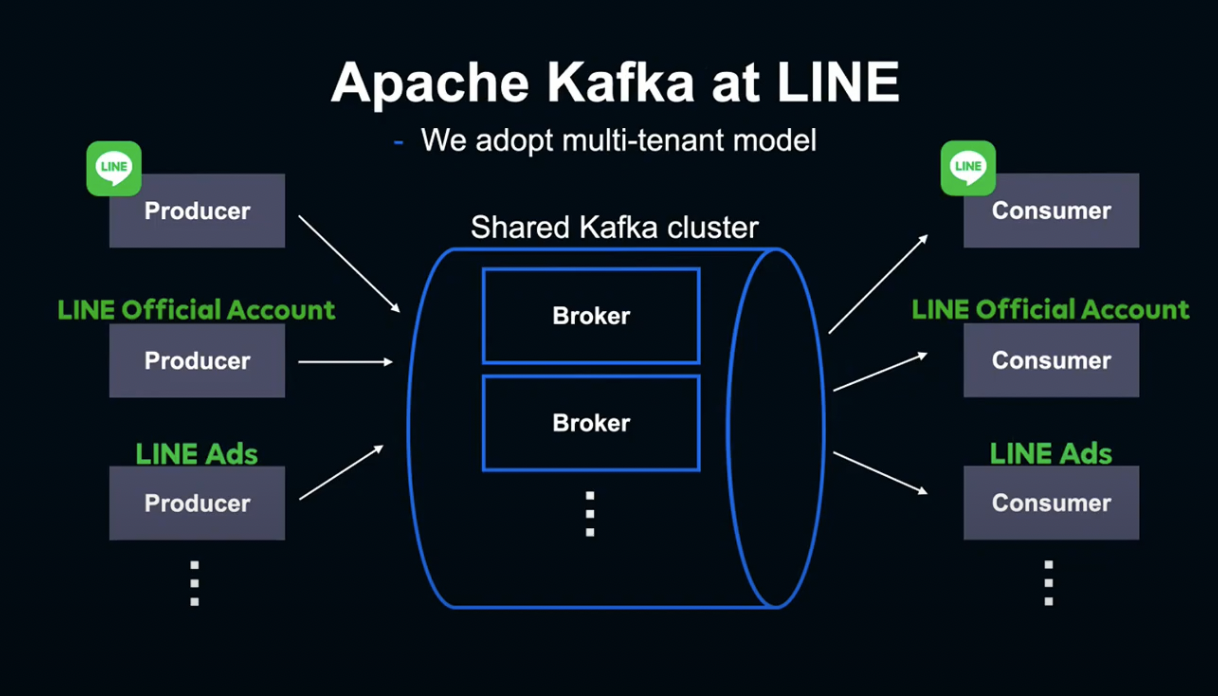
Kafka Cluster는 여러 개의 Broker 서버로 구성되어 있습니다.
Kafka에 메세지를 보내는 Client를 Producer라고 하고, 메세지를 수신 및 처리하는 Client를 Consumer라고 합니다.
LINE에서는 단일 Kafka Cluster를 여러 개의 서비스에서 공유하는 Multi-Tenant Model을 사용하고 있으며, 수많은 LINE 서비스가 Kafka Cluster를 사용하고 있습니다.

현재 LINE Kafka Cluster는 초당 1500만 개, 매일 1.4PB의 데이터를 처리하며, 100개 이상의 서비스가 이용하고 있습니다.
저희는 이와 같은 대규모 Kafka를 높은 수준에서 유지하기 위해 매일 퍼포먼스를 계측하고 최적화하며, 트러블 슈팅에 힘을 쏟고 있습니다.
Agenda

본 세션에서는 저희 Cluster에 발생한 문제와 그 해결 방법에 대해 말씀드리겠습니다.
- Cluster에서 발생한 문제
- 문제 조사 방법
- 문제 해결 방법
Phenomenon

어느 날, Kafka 설정을 변경하기 위해 Rolling Restart를 하고 있을 때였습니다.
서비스 개발자로부터 Kafka Message Produce가 실패된다는 보고를 받았습니다.
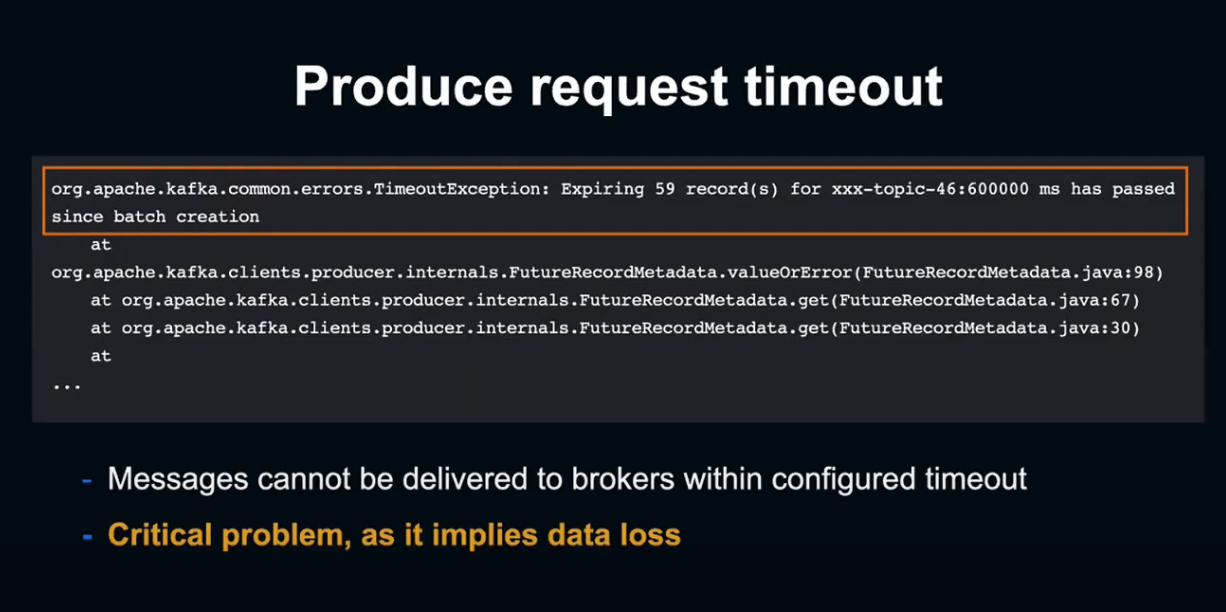
Log에서 Producer Request가 Timeout되고 있다는 사실을 알아냈습니다.
이것은 설정된 Timeout 내에 Message를 Kafka에 송신할 수 없었다는 것을 의미합니다.
송신에 실패한 데이터는 상실되기 때문에, 굉장히 Critical한 Event입니다.
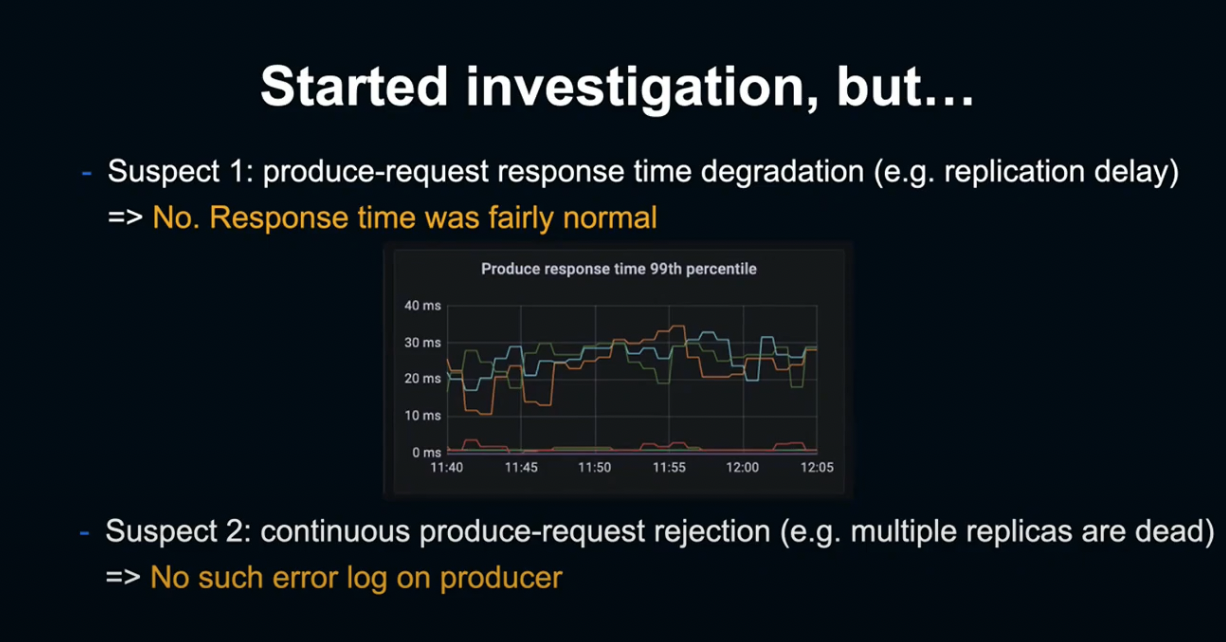
첫 번째로 의심해본 원인은 Replication의 지연 등의 이유로 발생하는 Broker Response Time의 상승이었습니다.
하지만 Broker가 제시하는 Matrix는 지극히 정상이습니다.
두 번째로 의심해본 원인은 Replica Server가 다운되어 발생하는 Producer Request 거절이었습니다.
그렇지만 서버 측에 특별한 오류가 없었고, Producer 측에서도 Request Time Out 이외의 로그는 확인이 불가했습니다.

조사를 더 해봤더니, 굉장히 기묘한 현상을 발견했습니다.
Broker 측에서 계측 중인 Response Time은 정상이었음에도 불구하고 Produce 측에서 계측한 Request latency는 16초 이상으로, Timeout이 일어나고 있었습니다.
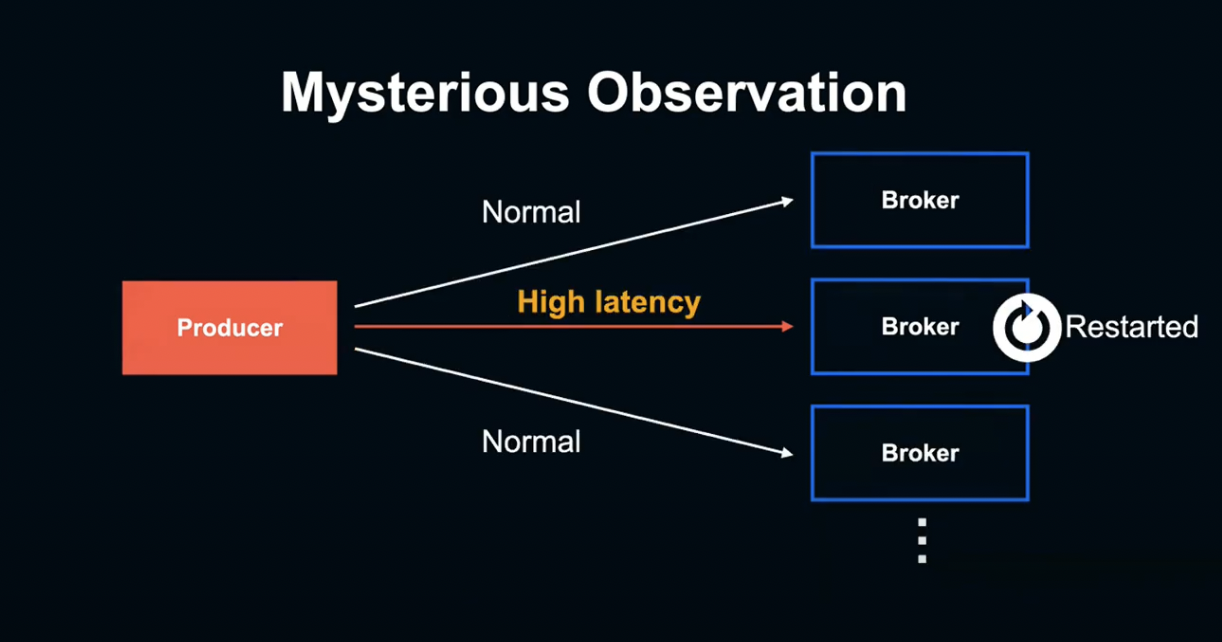
이러한 이상 Latency 상승은 특정 Broker에 Produce할 때만 발생하고, Latency 악화는 특정 Broker를 Restart한 후에만 발생됩니다.
Broker를 Restart한 직후부터 Produce Request Latency가 현저하게 악화되지만, 해당 Broker 측의 Response Time Matrix는 정상적인 문제가 발생하고 있었던 것입니다.

본래는 충분히 조사 시간을 가져야 했지만, 이 시점에서는 근본적인 원인을 알 수 없었고, 한시라도 빨리 데이터 손실에 대처할 필요가 있었습니다.
우선 Broker를 Restart시켜 문제를 멈췄습니다.
상황은 진정되었지만, 재발 방지를 위해서 근본적인 원인 규명이 필요했습니다.
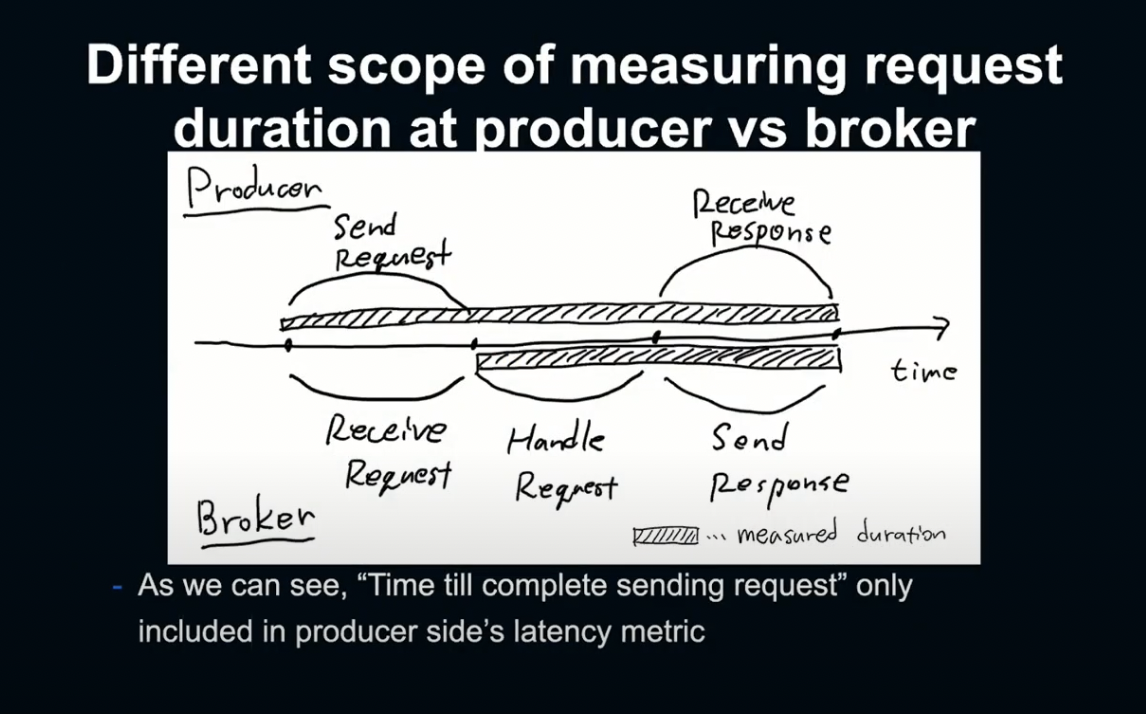
우선 Producer와 Broker 사이의 Matrix Gap을 이해해야 했습니다.
Kafka 코드를 확인해 본 결과, Request 송신 자체에 시간이 걸리면 이런 Gap이 발생한다는 것을 알 수 있었습니다.
Producer 측에서는 Request를 생성해 Broker에게 송신하고, 이것이 처리된 후 Client에게 보내져 수신될 때까지를 Latency로 계산합니다.
하지만 Broker 측에서는 Broker 측에서 Request를 수신하는 지점부터 계측을 시작하고, 이것이 Producer와 Broker 간 Matrix 차이를 만들게 됩니다.

저희는 Producer의 Sender IO 가 어떠한 원인으로 인해 Stack이 되어 Request 송신을 지연시킨다는 가설을 세웠습니다.
이를 검증하기 위 Producer 측의 Debug Log와 JVM Profile과 같은 Client-Side의 상세 정보가 필요했습니다.
그래서 저희는 서비스 개발자에게 협조를 요청해, 재현 실험을 해 보기로 했습니다.
Broker를 재시작하는 실험을 해봤지만 결국 현상을 재현하지 못했고, 실패로 끝나게 되어 현재로서는 Producer가 어떤 이유로 멈추었는지 검증이 어렵다는 사실을 알게 되었습니다.

또한 Producer-Broker의 특정 네트워크 경로에서 송신 지연이 일어나는 것이라는 가설도 세워 보았습니다.
하지만 Latency는 정상이었고, 네트워크를 지연시키는 다른 현상도 발견되지 않았습니다.

이처럼 조사가 난항을 거듭하던 중, 다른 서비스의 브로커에서도 똑같은 문제가 발생했습니다.
이미 몇 번 발생한 사례이기 때문에, 이런 사례에 공통적으로 적용할 수 있는 Request 송신과 관련된 패턴을 모색해 보기로 했습니다.
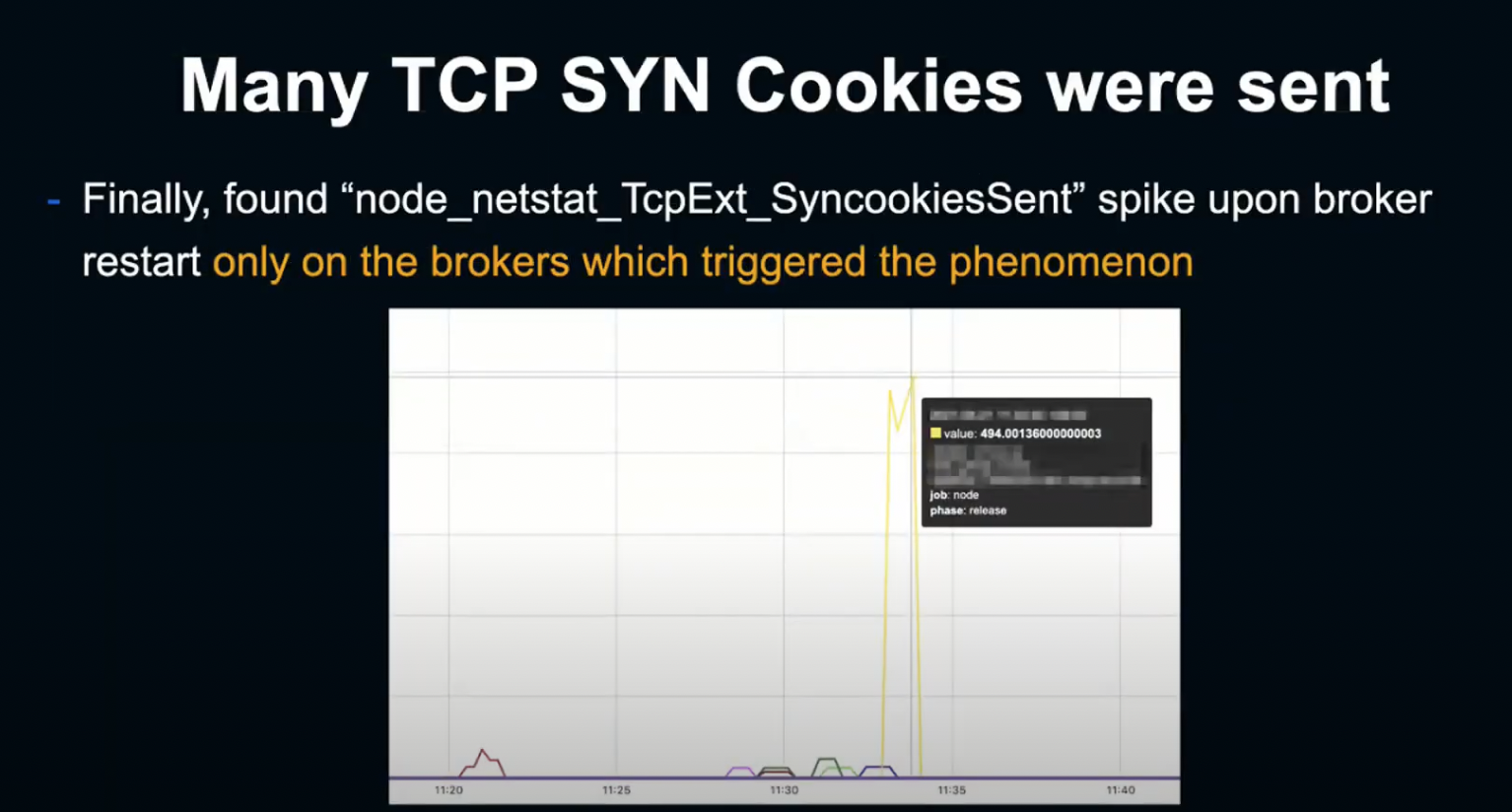
많은 Matrix를 주의 깊게 관찰한 결과, Broker 재시작 시 Node의 SynccookiesSent Matrix가 문제가 발생할 때만 현저한 스파이크를 나타낸다는 사실을 알게 되었습니다.
그렇다면 Sync Cookie의 상승은 무엇을 뜻할까요?
우선 TCN SYN Cookies에 대해서 알아볼 필요가 있습니다.
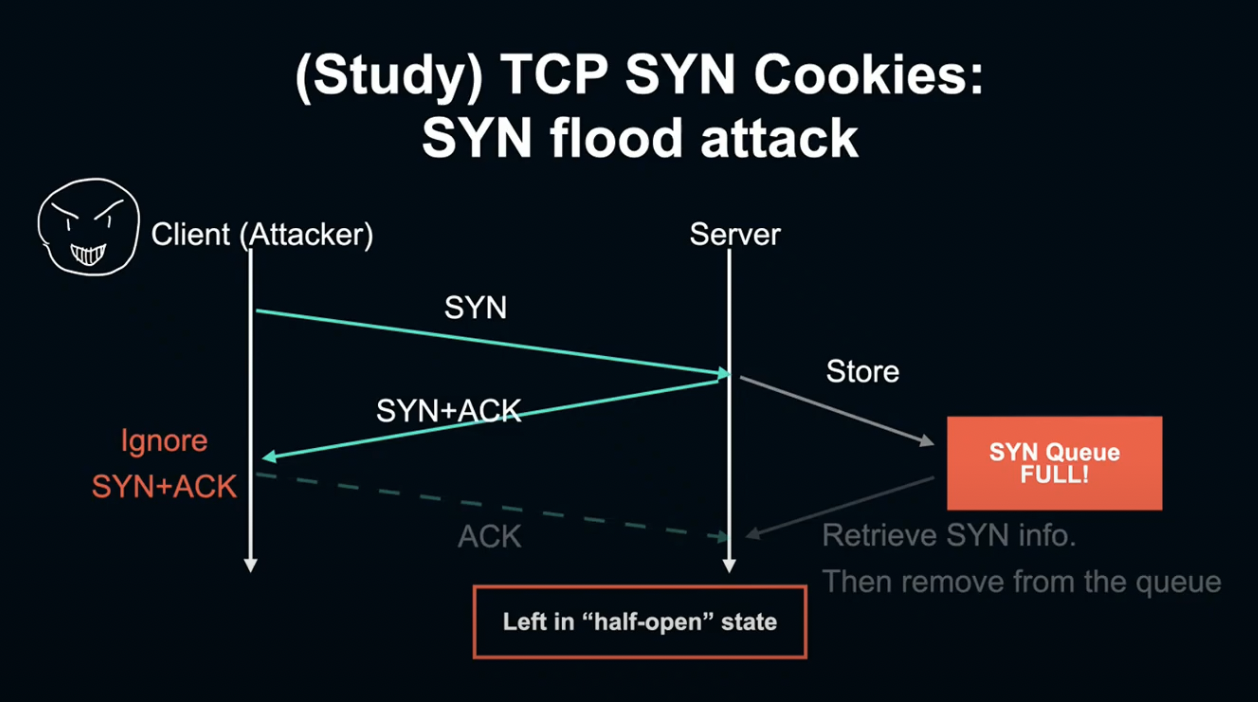
TCN SYN Cookies란 Sync Flood 공격의 대처 메커니즘입니다. TCP에서는 Client가 연결을 열 때 서버에 SYNC 패킷을 송신하고, 서버는 이를 Sync Queue에 적재하고 Sync ACK 패킷을 Client에 전송합니다.
마지막으로 Client가 이것을 받아 ACK를 서버에 다시 전송하고, SYNC Queue에 두었던 Sync ACK를 꺼내 연결을 확립시켜 Handshake를 완료시킵니다.
하지만 악의적인 Client가 SYNC ACK를 고의적으로 보내지 않게 되면, 서버는 계속 완료되지 않은 Sync를 Queue에 유지해야 하고, 다른 Client가 접속할 수 없게 됩니다. 이를 SYN Flood attack이라고 합니다.
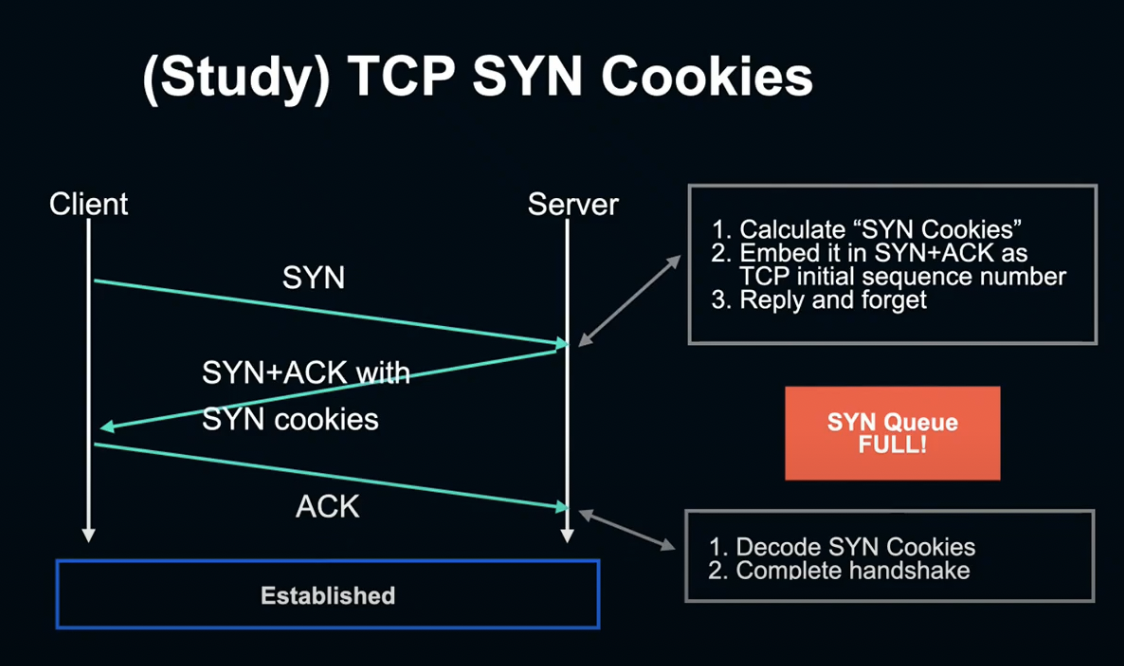
SYN Cookies는 Flood가 일어난 상태에서도 Client가 접속할 수 있도록 하기 위한 구조입니다.
SYN Flood가 일어나 SYN Queue가 꽉 차게 되면 SYN 패킷을 Queue에 보관하는 대신 SYN에 포함된 정보를 패킷에 쿠키로 인코딩하여 Client에 전송합니다.
나중에 Client가 ACK를 다시 전송하면, 서버는 쿠키를 디코딩하여 SYN 정보를 꺼내 연결을 완료합니다.
Send Matrix의 스파이크는 Queue가 가득 차 있기 때문에 SYN Cookies 방식으로 연결한 수를 나타내는 것입니다.
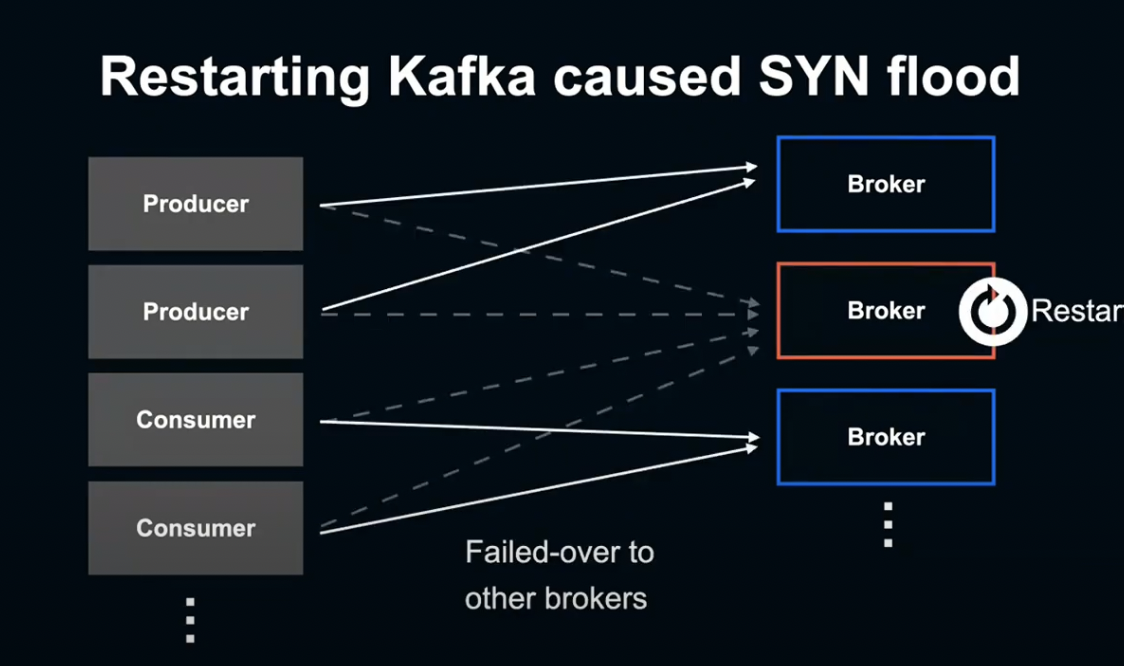
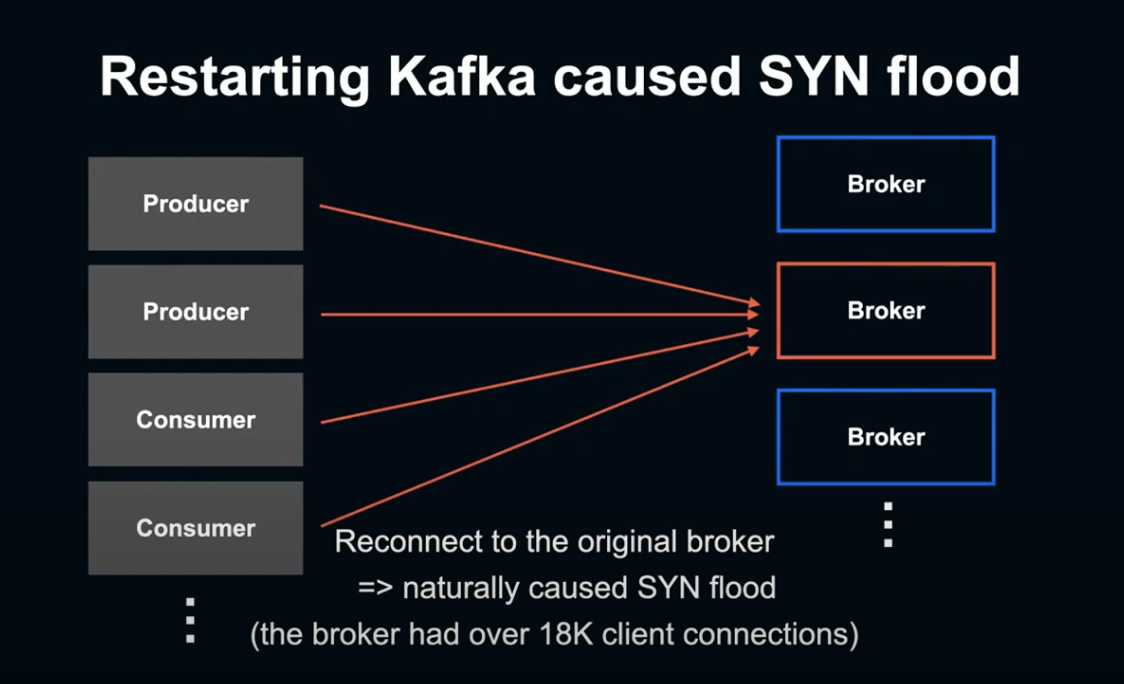
Cluster에는 다양한 Producer, Consumer 같은 Client가 접속해 있습니다.
Broker를 리셋하게 되면 해당 브로커에 접속되어 있던 Client는 전부 다른 Broker에 Failover하게 되고, 해당 Broker의 Restart가 완료되면 원래 접속되어 있던 Client들이 한 번에 원래 Broker에 다시 접속하게 됩니다.
그렇기 떄문에 공격 같은 상황이 발생해, SYN Flood 상태에 빠지게 되는 것입니다.
이렇게 Broker가 SYN Flood됨에 따라, 일부 Client의 연결이 SYN Cookie를 사용하는 쪽으로 대체되었다는 것을 알게 되었습니다.
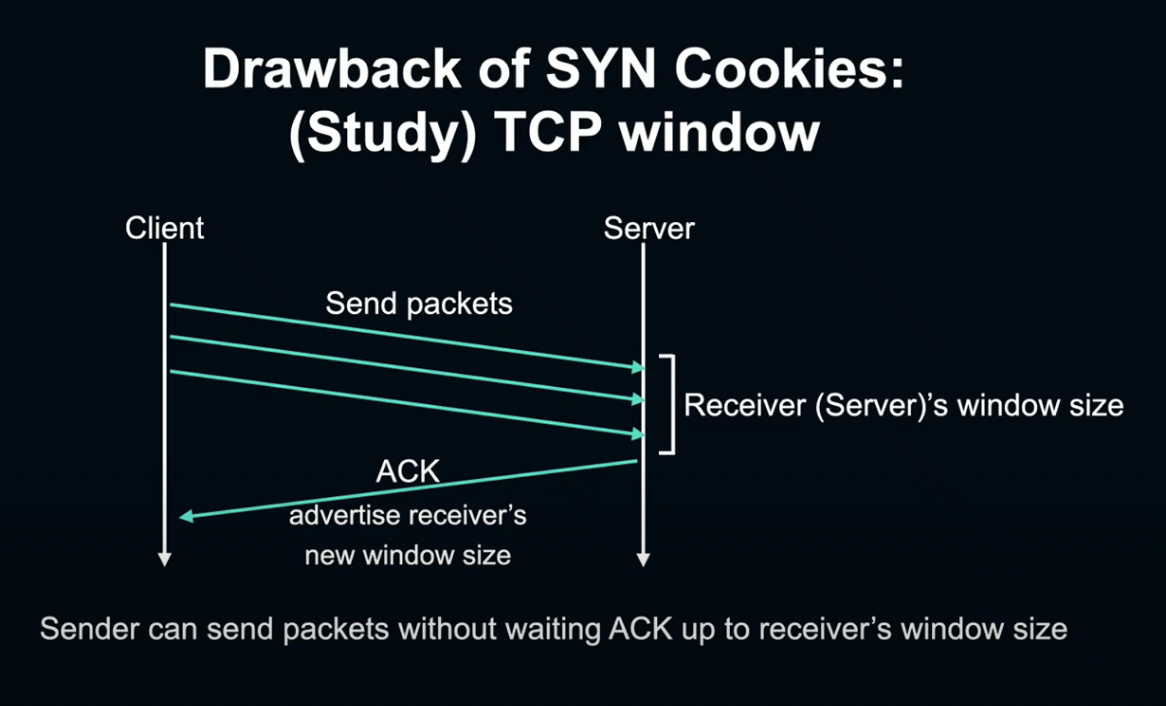
SYN Cookie는 성능 상 약점이 있는데, 설명드리기 전 우선 TCP window에 대해 설명드리도록 하겠습니다.
TCP window는 TCP에서 요청 양을 제어하기 위한 시스템입니다.
TCP의 수신 단에서 현재 얼마나 많은 데이터가 수신 가능한지를 패킷에 반영해, 송신자가 Window size에 따라 전송 양을 조절할 수 있게 합니다.
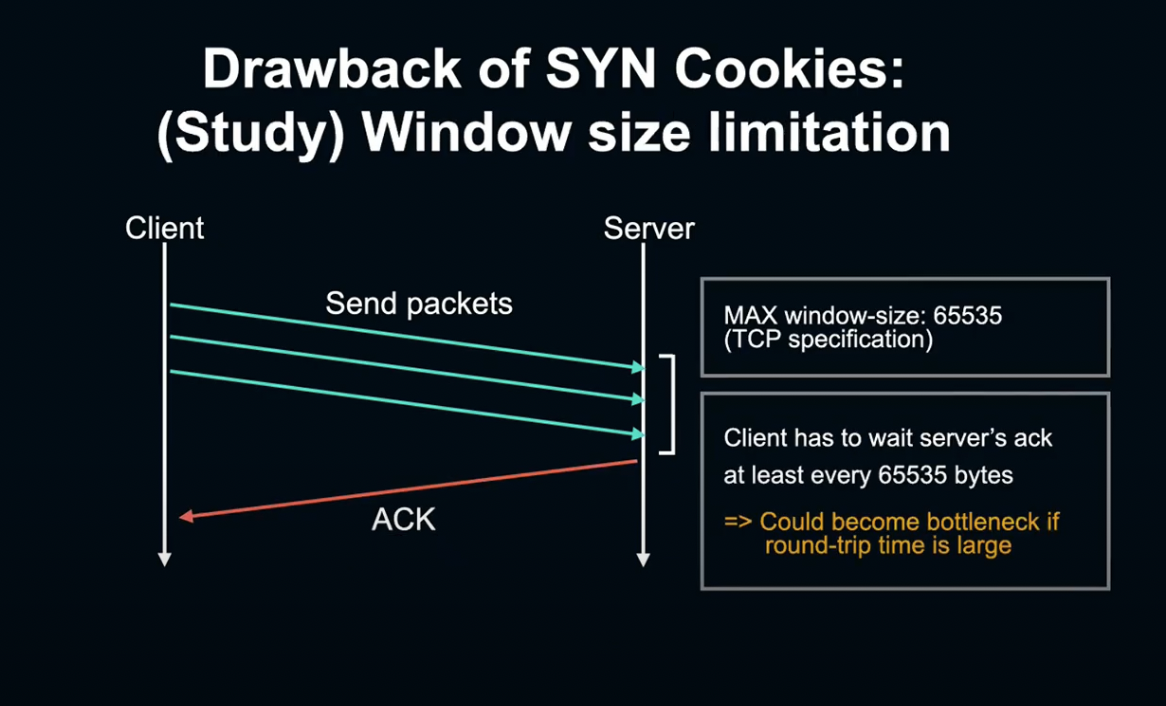
Window size는 16비트로, TCP 사양으로 정해져 있습니다.
그렇다면 서버를 기다리지 않고 한 번에 전송할 수 있는 데이터 양은 최대 65535Byte라는 것인데, 이는 인터넷과 같은 지연이 큰 연결에서는 병목 조건이 될 수 있습니다.
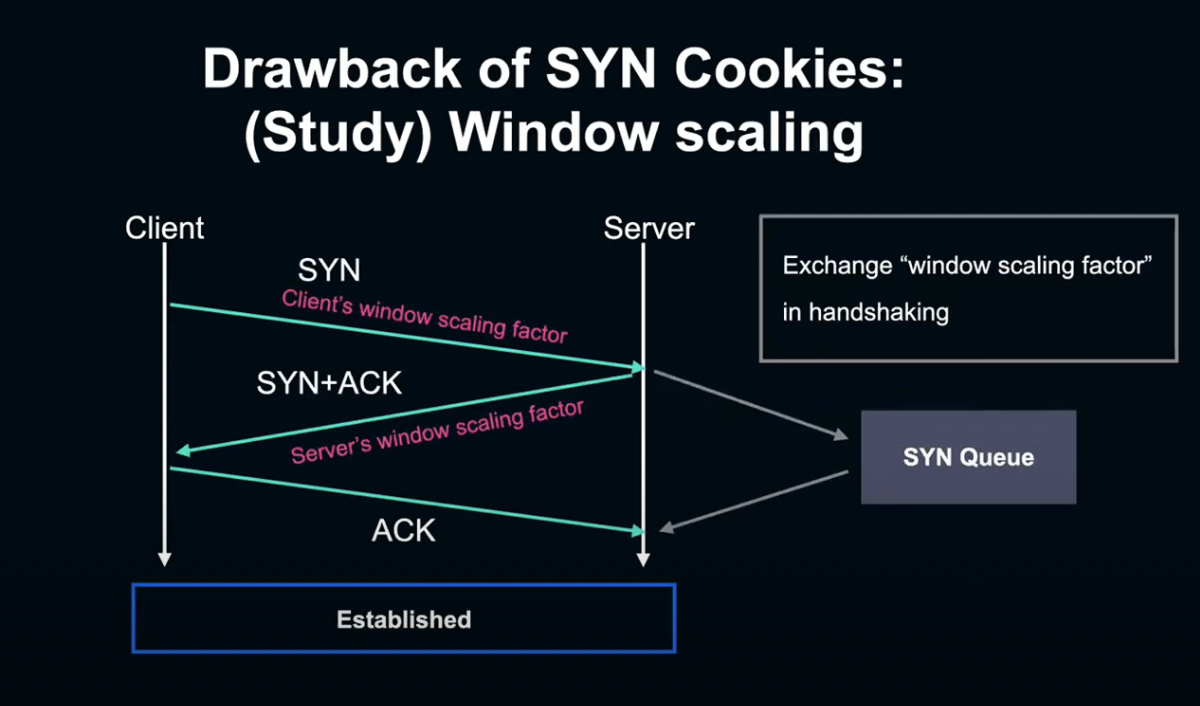
이때 Window size를 65535Byte 이상으로 확대하고, Throughtput을 향상시키기 위해 사용하는 기술이 Window scaling입니다.
Window scaling은 TCP Handshake 시 SYN과 SYN에게 반영된 Window scaling factor 수치를 상대방에게 알립니다.
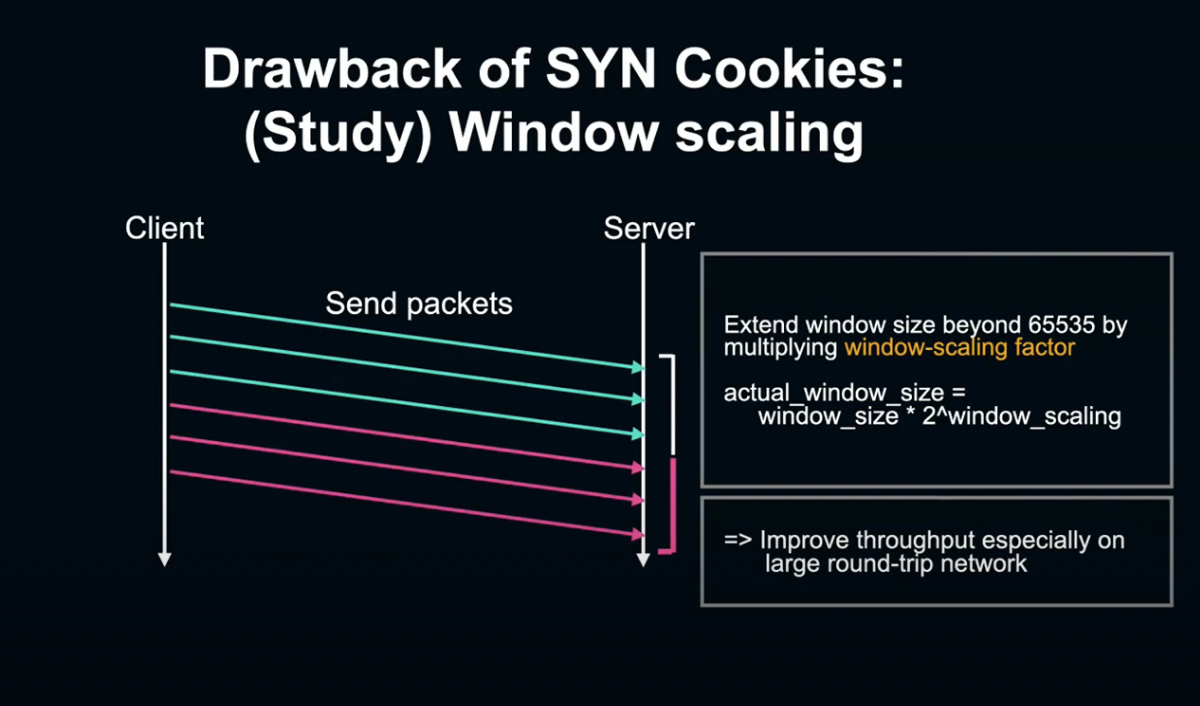
그리고 실제 데이터를 송수신 할 때, Window size에 미리 준비한 window scaling factor를 곱해 2^scaling factor로 계산합니다.
이렇게 함으로서 window size를 크게 확대하여 Throughput을 향상할 수 있습니다.
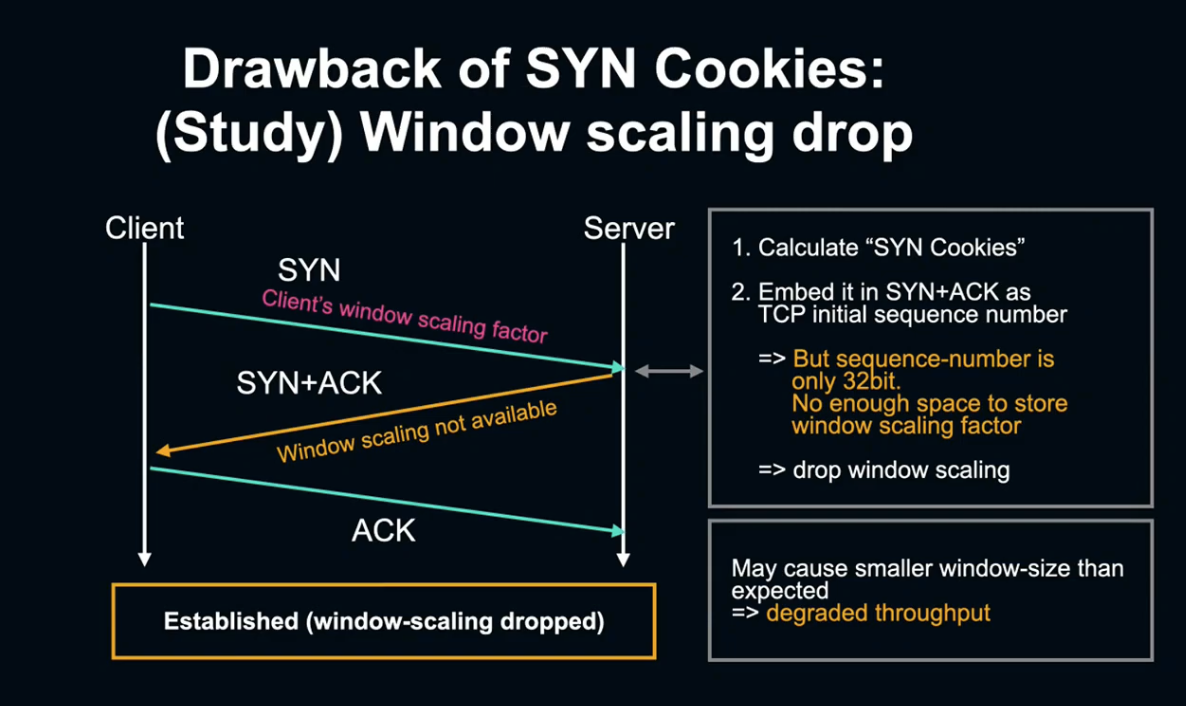
다시 SYC cookie에서 Throughput이 떨어지는 이유에 대한 이야기로 돌아가겠습니다.
SYN Cookie는 SYN 패킷을 복원하는 대신, SYN 정보를 TCP Sequence number에 인코딩하는 방법입니다.
하지만 Sequence number는 32비트이기 때문에 내장 정보가 제한되어 있어 window scaling factor 사용이 불가능합니다.
다시 말해 SYN Cookie에서는 window scaling을 사용할 수 없어 widow scaling을 사용하는 것보다 전송 데이터 양이 적고, Throughput이 약화됩니다.
But..
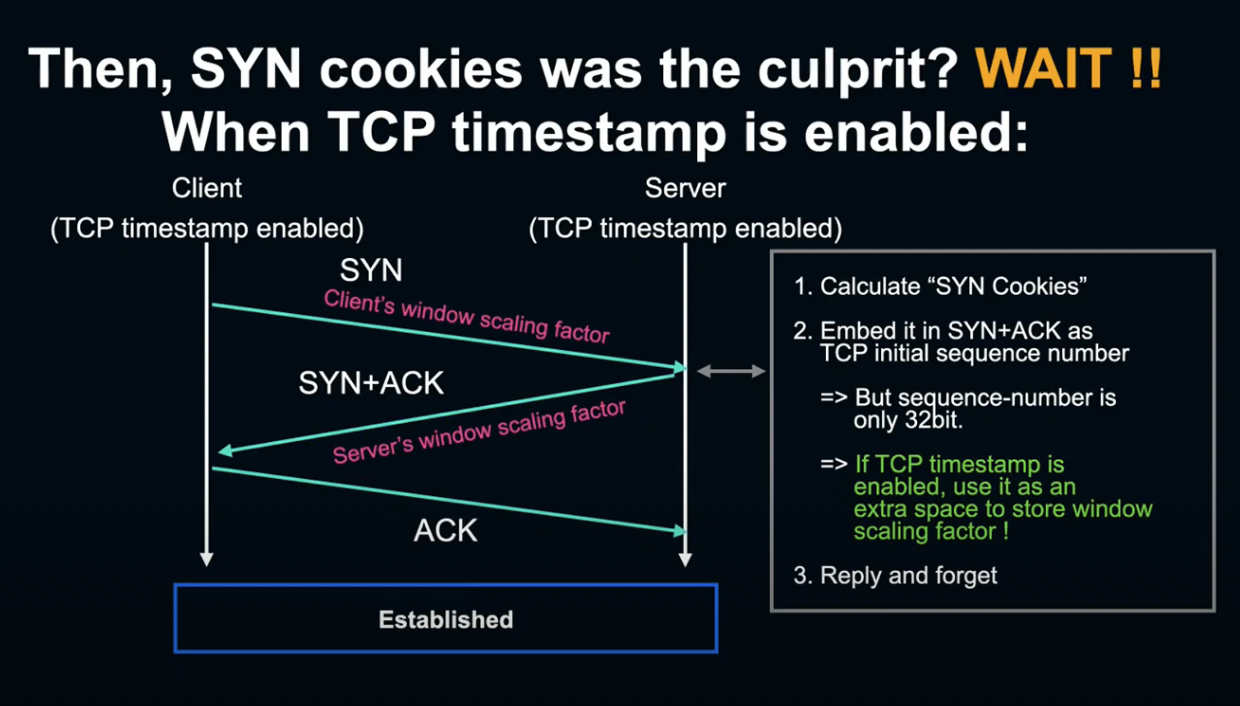
그렇다면 이것이 프로듀스 리퀘스트 지연을 일으킨 원인일까요?
결론을 내기에는 아직 이릅니다. SYN Cookie에서의 Throughput 약화는 window scaling을 사용하지 못하게 되면서 발생했습니다.
그런데 사실 리눅스 커널은 TCP Timestamp가 유효한 경우, Timestamp 빌드의 여분 공간을 사용해 scaling factor를 내장하는 기능이 있고, LINE의 환경에서는 TCP Timestamp가 Default로 사용되고 있습니다.
따라서 Throughput 악화의 원인으로 보기엔 무리가 있습니다.

게다가 LINE 내부 환경 같은 Low latency 환경에서는 만약 window scaling을 사용하지 않더라도, 충분한 Throughput을 확보할 수 있습니다.
Experiment

이에 우리는 SYN Cookie에서 window scaling이 무효화되면 실제로 얼마나 큰 영향이 발생하는지 실험해 보기로 했습니다.
이 실험에서는 netip tcp syncookie 커널의 Parameter를 2로 설정함으로서 모든 연결에 SYN Cookie를 강제하고, 프로토콜을 재기동하여 실험하였습니다.
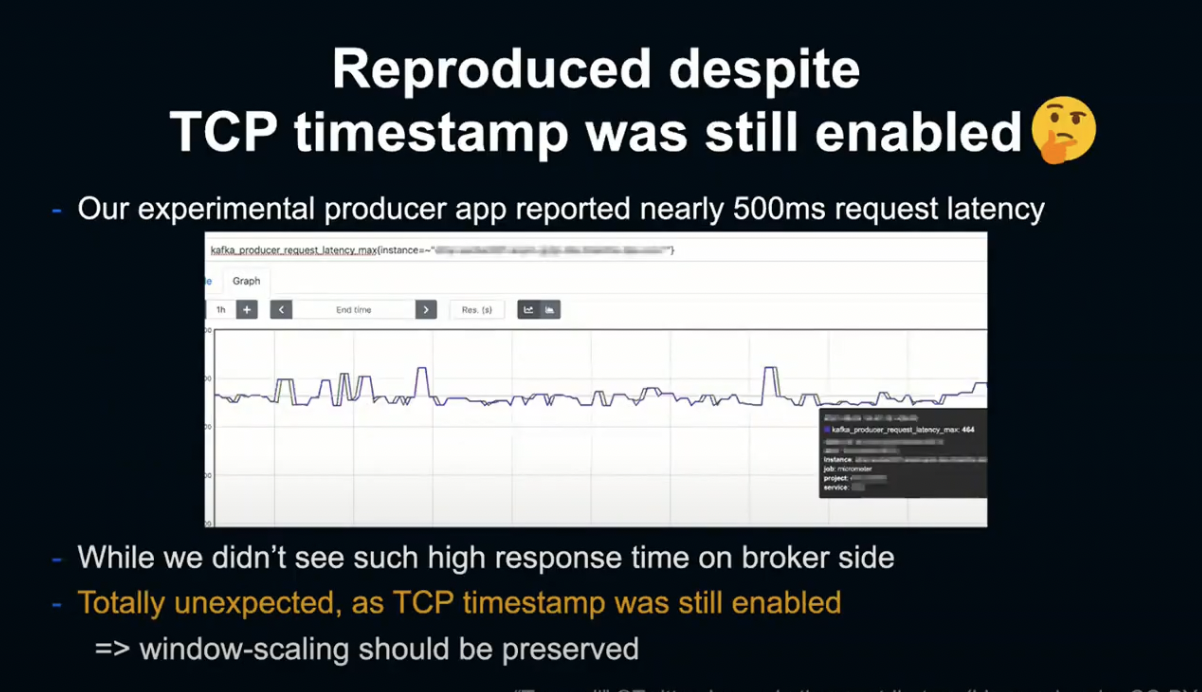
그 결과 TCP Timestamp 무효화 전 단계, 다시 말해 window scaling이 유효해야 할 단계에서 현상이 재현되고 있었습니다.

이때 TCP Dump를 확인한 결과, 놀랍게도 Producer는 패킷을 한번 전송할 때마다 Broker의 ACK을 기다리고 있었습니다.
즉, Broker의 Window size가 작아서 Broker에서 ACK를 수신할 때까지 Producer가 후속 패킷을 송출하지 못하는 상황이 발생 중이었던 것입니다.
원래 window size는 window size * 2 ^ window scaling이었어야 했습니다.
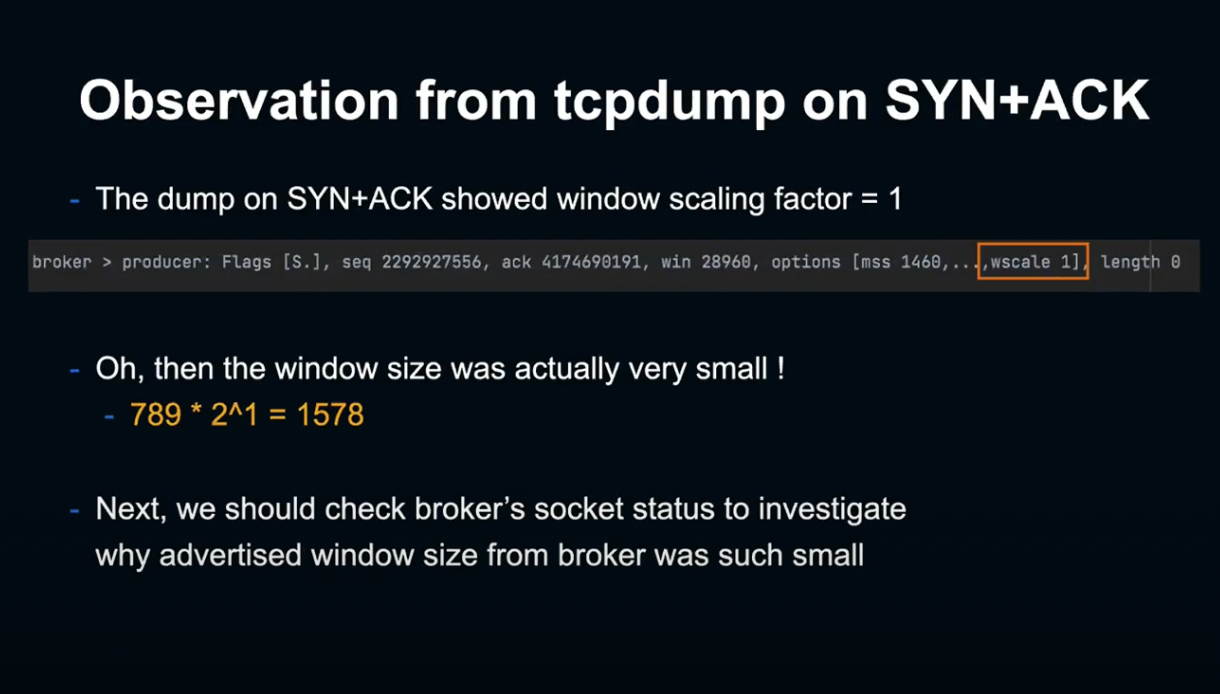
하지만 TCP Dump에서 패킷을 확인한 결과, window scale factor가 1로 되어 있었습니다.
다시 말해 실제 윈도우 사이즈는 window size * 2로, 매우 작은 값이었습니다.
그래서 우리는 왜 윈도우 사이즈가 이렇게 작은 값이 되었는지 알아보았습니다.

TCP 소켓 상태 확인 툴인 SS2를 문제가 발생한 Broker에서 작동시켜 확인한 결과, 또 다시 기묘한 현상이 발생했습니다.
Broker 단의 Window scale factor가 7이라는 점입니다.
앞서 TCP Dump에서 보았듯이 Broker는 SYN ACK로 window scale factor size는 1이라고 Producer에 알린 상태입니다.
Producer와 Broker의 Scale factor가 일치하지 않으면 원래 window size를 복원할 수 없게 됩니다.

다음으로 실제로 Broker에서 window size를 계산할 때 사용한 값이 1인지 7인지 확인해 보기로 했습니다.
Linux kernel의 소스 코드를 확인해 보면, window size의 계산은 tcp select window라는 kernel 함수로 진행되는 것을 알 수 있습니다.

그렇다면 어떻게 kernel 함수를 사용할 수 있을까요?
이는 BPF라는 Linux 시스템을 사용해 매우 쉽게 실현할 수 있습니다.
BPF는 이벤트로 구동하는 툴로, 다양한 이벤트를 트리거 삼아 유저가 작성한 BPF 프로그램을 Kernel 내부에서 실행할 수 있으며, BCC 키트, kprobe 등의 툴을 사용해 쉽게 작성 및 사용할 수 있습니다.
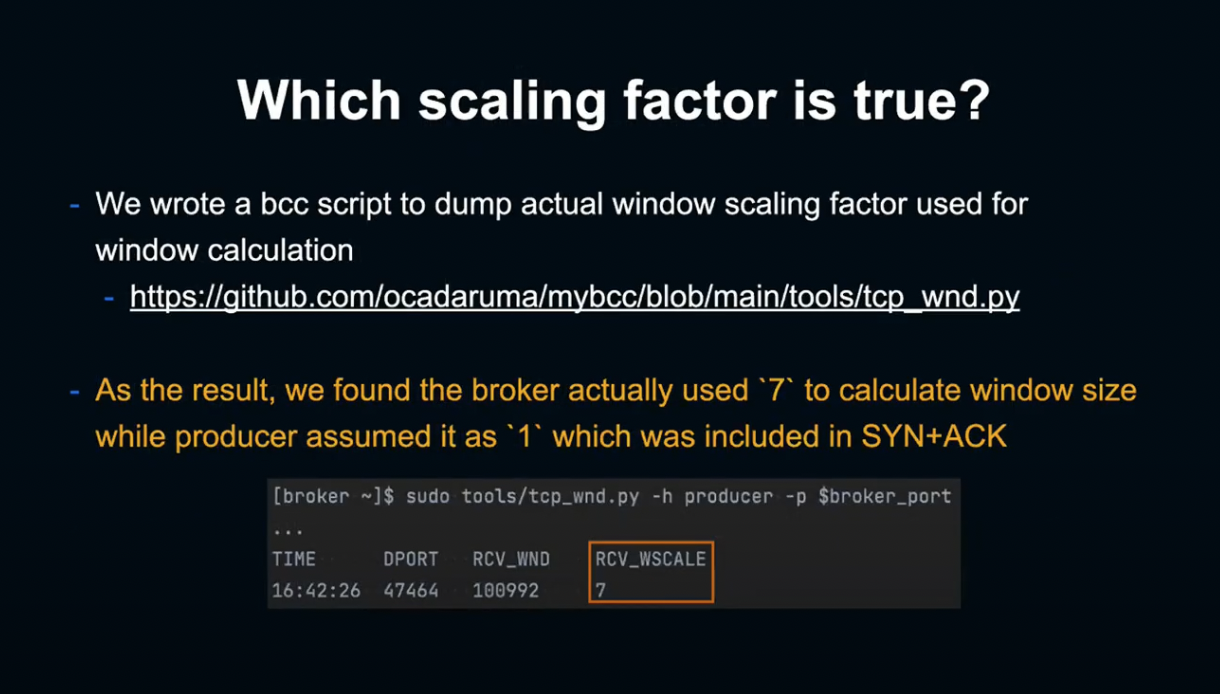
BCC를 사용해 TCP select window 함수로 window scaling factor를 사용하는 간단한 스크립트를 작성했습니다.
이 스크립트로 Broker에서 실행해 본 결과, 실제로 SS가 출력했던 7을 사용해 window size를 계산했던 것으로 나타났습니다.

그렇다면 왜 Broker에서 SYN ACK으로 알린 scaling factor와 Broker가 연결 확립 후 사용하는 scaling factor 간에 차이가 발생하는 것일까요?
다시 한번 kernel의 소스 코드를 확인한 결과, Client에 전송하는 SYN ACK 패킷 생성 부분과, SYN Cookie를 전송한 후 Client ACK에 포함되는 쿠키를 디코딩하여 연결을 확립하는 부분에 차이가 있었습니다.
이는 Linux 커널의 5.10 버전 이전 버그로, 이 버그가 원인이 되어 window scale factor에 차이가 발생하고 있었다는 사실을 알게 되었습니다.

이로써 모든 수수께끼가 풀렸습니다. 지금까지의 흐름을 정리해 보겠습니다.
먼저 Broker를 재기동함으로서 많은 Client가 한꺼번에 재접속하는 상황이 발생해, Broker가 SYN Flood 상태가 되었습니다.
이로 인해 Producer의 TCP handshake가 SYN Cookie를 경유하도록 롤백되었습니다.
그리고 Linux의 버그로 인해 SYN ACK factor와 최종 연결 factor 간의 차이가 발생했습니다.
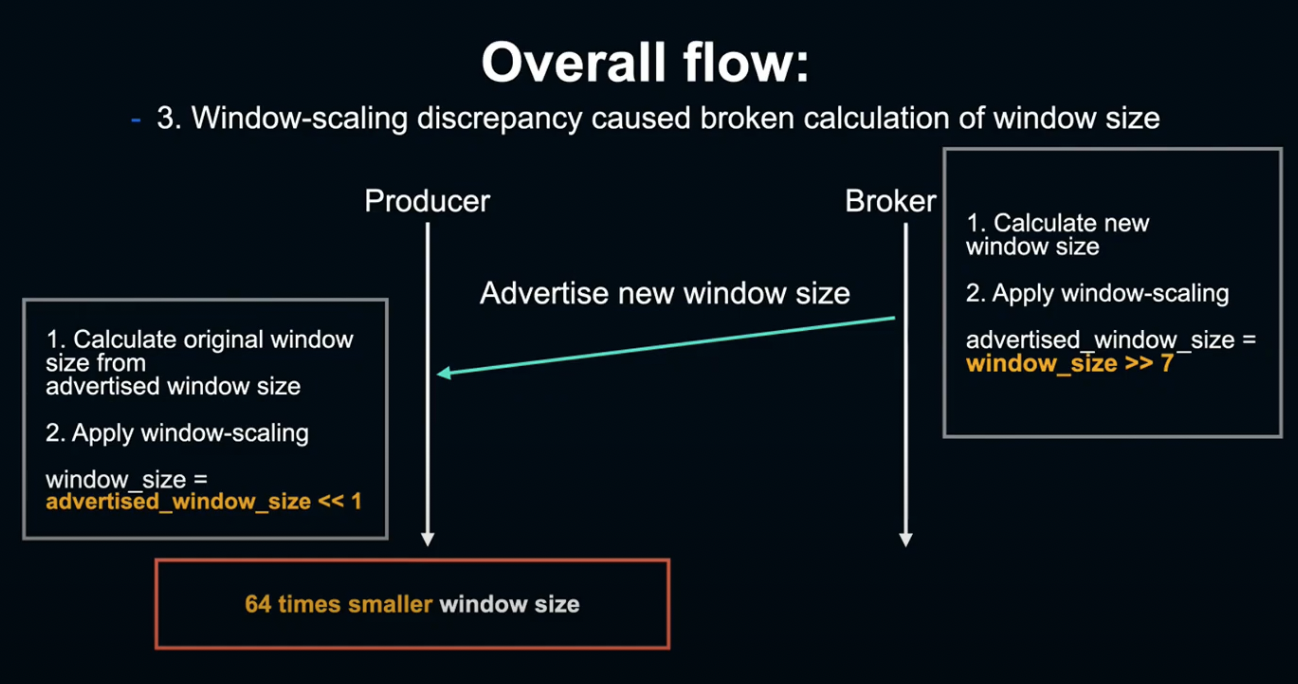
Broker에서 알린 window size가 정확히 복원되지 않고, 매우 작은 값이 되었습니다.
우선 Broker가 Producer에 window size를 알릴 때, Broker는 scale factor를 7로 인지하고 있기 때문에, Producer 단에 size를 2^7로 나누어 전달합니다.
한편 Producer 단에서는 scale factor를 1로 알고 있기 때문에, 2에 1을 곱하여 복원하려 하고, 이에 따라 window size는 원래 값의 1/64라는 매우 작은 값이 됩니다.

그리고 이 너무 작은 window size로 인해 Producer는 패킷을 전송할 때마다 Broker의 ACK를 기다려야 했고,
그 결과 Produce Request를 전송하는 데 오랜 시간이 걸리게 되면서 Timeout을 초래하게 되었습니다.
Solution

이제 근본적인 원인이 밝혀졌기 때문에, 어떻게 해결할지 생각하는 일만 남았습니다.
먼저 시도한 방법은 TCP SYN Cookie를 애초에 무효화하는 방법입니다.
SYN Cookie를 무효화 할 시 SYN Flood가 일어나는 동안에는 SYN을 Drop하고, SYN Retry를 통해 Client와 연결하게 됩니다.
하지만 SYN Drop 및 Client 단의 SYN Retry 시 지연이 발생할 수 있는 문제가 있었습니다.

따라서 SYN Cookie 무효화와 더불어 Kafka Socket의 listen backlog 크기를 늘려, 애초에 SYN Flood 상태가 일어나지 않게 하는 것을 보다 바람직한 대책이라고 할 수 있습니다.
다만 안타깝게도 현 시점에서는 Kafka의 listen backlog 크기가 50으로 하드코딩되어 있어 늘릴 수 없습니다.
이 부분은 현재 KIP-764라는 back log 설정을 유관 부서와 논의 중에 있습니다.
마무리

오늘 우리는 LINE Cluster와 같이 많은 Client가 접속하는 대규모 Kafka Platform에서는 SYN Flood가 일어날 수 있다는 것을 배웠습니다.
또한 Linux Kernel 5.10 이전 버전에서는 SYN Cookie 버그로 인해 Producer와 Broker 간 window scaling factor의 차이가 생겨, TCP Throughput이 악화되는 경우가 있다는 것도 알게 되었습니다.
그리고 이와 같은 Kernel 내부까지 포함되는 네트워크 문제를 조사할 때에는 TCP dump, ss, bcc와 같은 툴들이 유용하다는 것도 배울 수 있었습니다.
오늘 제가 준비한 내용은 여기까지입니다. 감사합니다.
LINE Home Tab에 컨텐츠를 전달하기 위한 고범용성 시스템 - Zhixin Li

Agenda

본 세션에서는 LINE Home Tab에서의 정보 전달을 위한 다목적 시스템에 관해 말씀드리겠습니다.
- Home Tab과 추천 기능이란?
- 시스템 아키텍처와 기술
- 어려움들과 극복 과정
- Use Case
LINE Home Tab
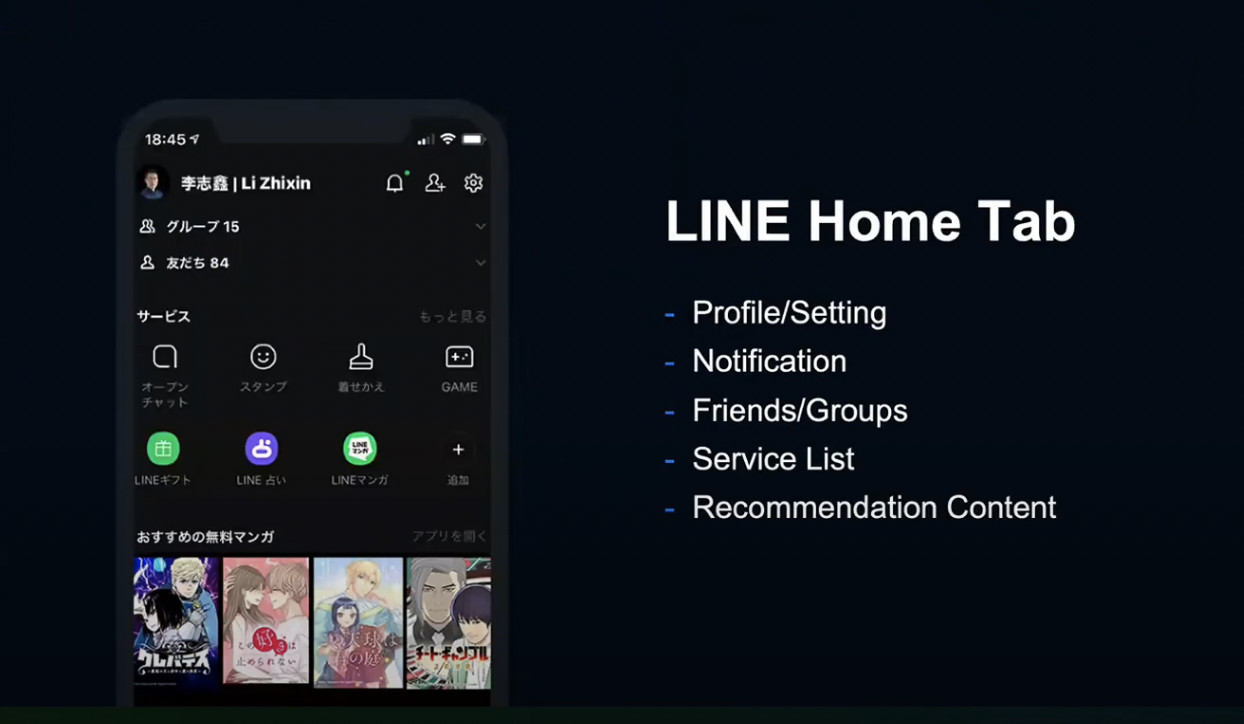
LINE Home Tab은 LINE 앱에 진입하면 보이는 첫 번째 페이지로, 프로필, 설정, 알림, 친구 그룹, 서비스 목록, 추천 컨텐츠 등을 제공합니다.

추천 기능에서는 LINE 앱의 다양한 기능을 추천받을 수 있습니다.
일본 유저의 경우 스티커, 만화, 오픈 채팅, 특별 캠페인, LINE MUSIC, Cosme 등을 추천받을 수 있습니다.
단순히 컨텐츠 뿐만이 아니라 구성도 다양하기 때문에, 컨텐츠마다 다른 레이아웃을 적용할 필요가 있습니다.
Recommendation Content Development Flow
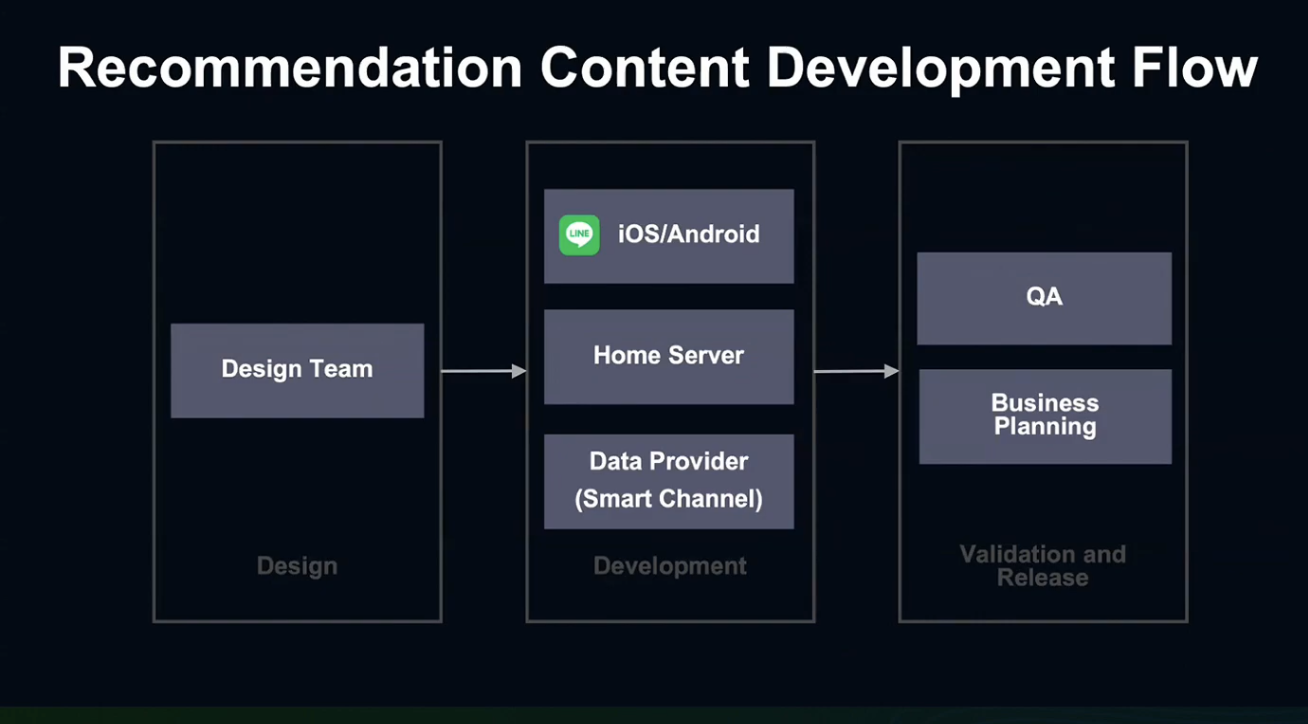
추천 컨텐츠는 3가지 단계를 거쳐서 출시됩니다.
디자인 단계에서는 디자이너가 기능에 따른 UI를 개발합니다.
개발 단계에서는 iOS/Android 개발자들이 Client의 UI를 개발하고, Home Server에서는 Client에 API로 데이터를 전송합니다.
Data Provider는 Home Server의 Upstream Server인데, 머신러닝과 추천 기술을 사용해 컨텐츠별 추천 정보를 전달하게 됩니다.
Smart Channel은 내부 서비스로, LINE의 개인 맞춤화 서비스를 개발합니다.
개발이 완료되면, QA에서 컨텐츠를 검증 및 검사하고, 비즈니스&기획 팀이 최종 출시일을 결정하게 됩니다.

하지만 이런 개발 방식에는 단점이 있습니다.
새로운 컨텐츠를 개발할 때 항상 3개의 부서가 이 과정을 반복해야 하기 때문에, 개발 비용이 높습니다.
또한 UI가 Client 쪽에서 구현되기 때문에, 새로운 컨텐츠를 출시하기 위해서는 새로운 앱 버전이 필요하고, 출시된 컨텐츠의 UI를 변경하는 것이 어렵습니다.

그렇다면 이런 단점들을 극복하고 유연한 시스템을 만들기 위해서는 어떻게 해야 할까요?
구현에 앞서 시스템의 요구사항부터 알아보겠습니다.
시스템은 유연해야 합니다. 새로운 Client 버전 없이 출시하기 위해서는 Client 쪽에 하드코딩된 UI가 없어야 합니다.
반복적 비용을 줄여야 합니다. 새로운 시스템은 Client 개발 비용이 없어야 하며, 미니멀한 홈 서버 애플리케이션 환경에서의 기초적인 구현만으로도 작동해야 합니다.
다국어 지원이 필요합니다. LINE은 Global Service이기 때문에, 서버 쪽 다국어 지원이 필요합니다.
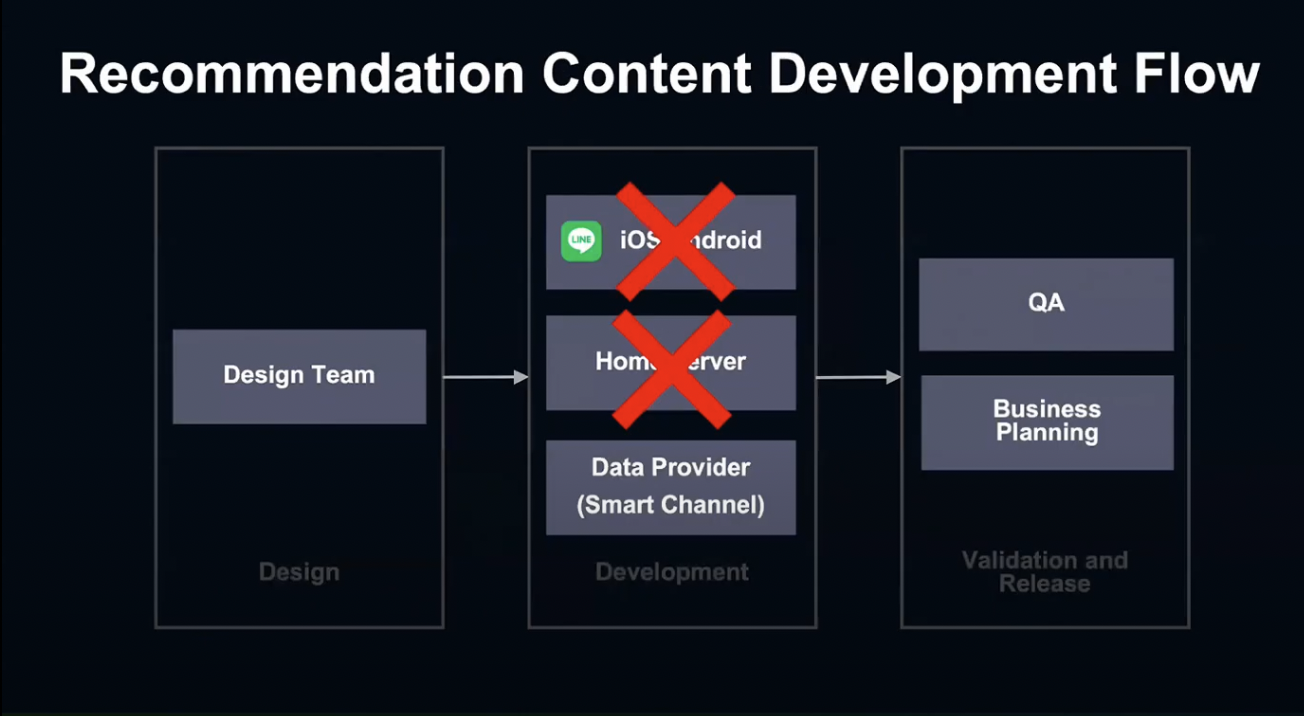
이런 세 가지 요구사항을 충족시킬 수 있다면 Flow가 이와 같이 훨씬 간단해질 것입니다.
지금부터 어떤 기술과 아키텍쳐를 적용하여 요구 사항을 만족하는 서비스를 구현했는지 말씀드리겠습니다.
Flex Message

유연한 UI를 만들기 위해 FLEX Message를 사용했습니다.
Flex Message는 LINE Message를 위한 외부 기능으로, JSON 형식 메세지로서 LINE API를 통해 전송됩니다.
LINE Bot을 통해 Flex Message가 전송되고, Client는 메세지를 받아 Building, Rendering을 수행합니다. 마지막으로 User는 Rendering된 결과값을 받아 출력합니다.
사용 예로는 영수증이나 카페 메세지 카드가 있습니다. 하지만 JSON 방식의 Flex message는 Home Tab 추천 컨텐츠 방식에 적합하지 않았습니다.
Recommand System Flow
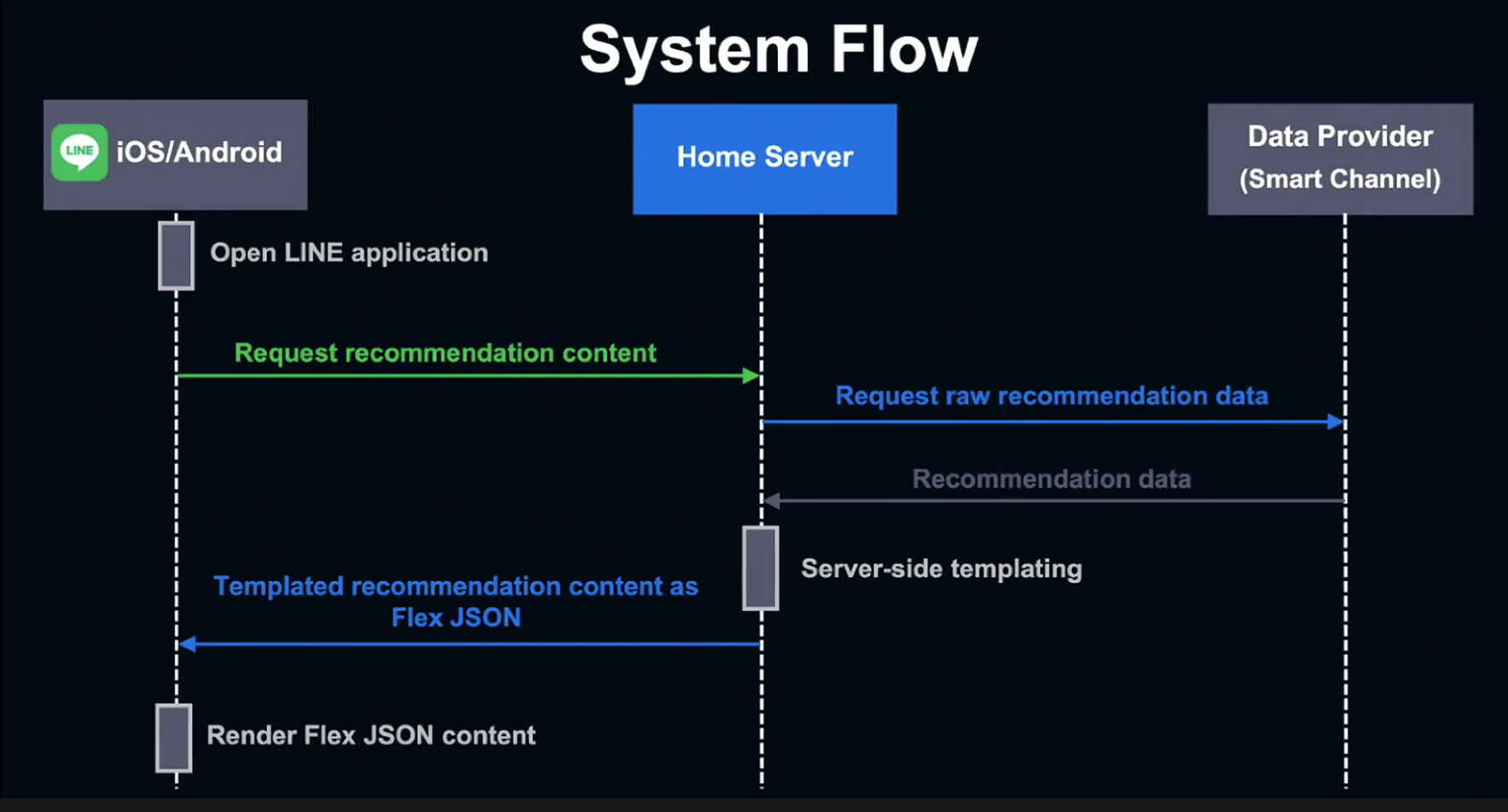
유저가 LINE 앱을 열면 Client는 Home Server에게 추천 데이터를 요청합니다. Home Server에는 추천 데이터가 전혀 없기 때문에, Upstream Server인 Data Provider에 추천 원 데이터를 요청합니다.
추천 데이터를 받은 Home Server는 홈 버전의 Flex Message인 Flex JSON을 생성합니다. 이 단계를 Server-Side Templating이라고 부릅니다.
Home Server는 Client에 JSON을 전송하고, Flex 결과를 렌더링하여 유저에게 전달합니다.
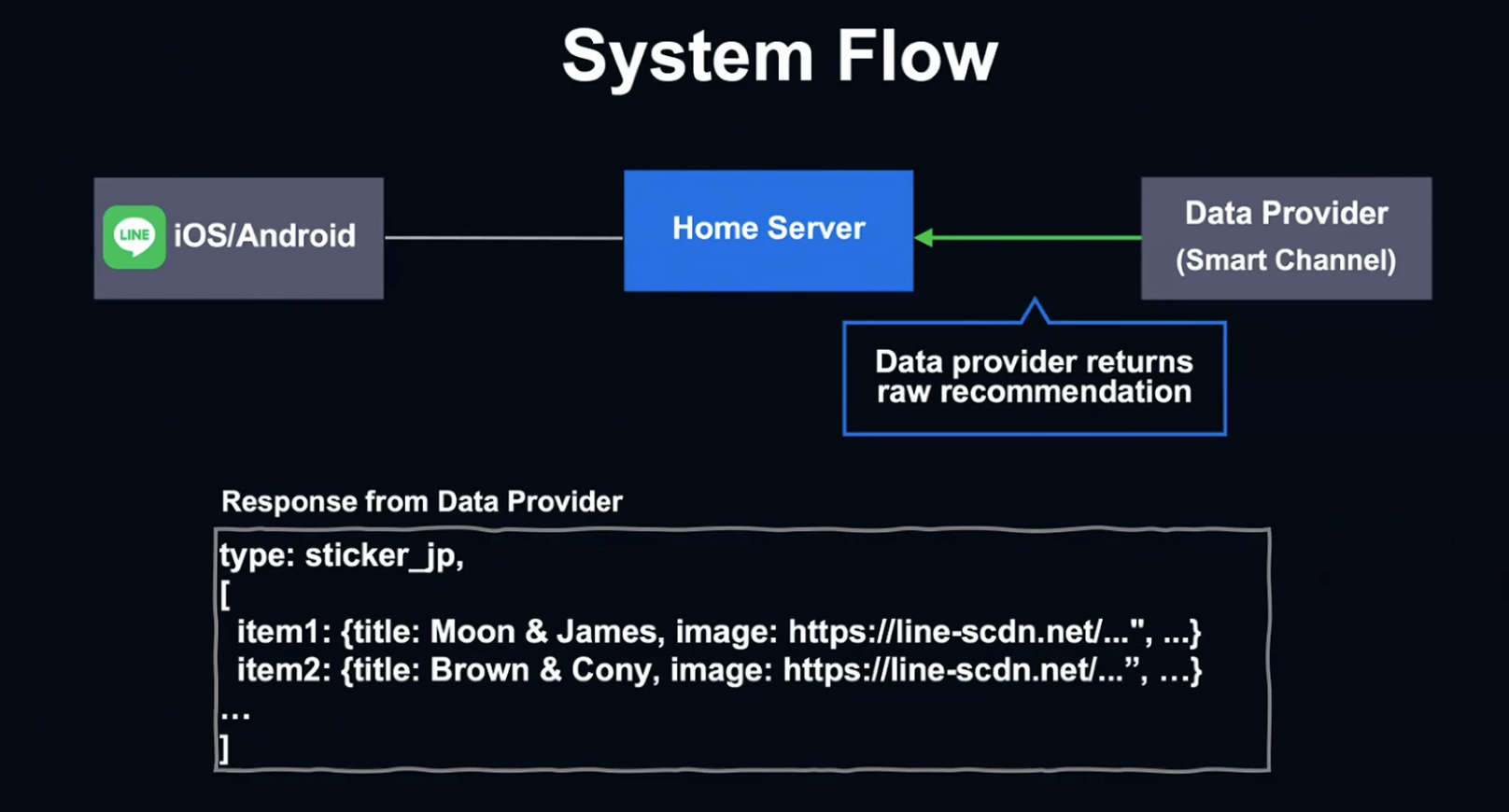
Data Provider의 응답에서는 컨텐츠 종류와 아이템 리스트를 확인할 수 있습니다. 제목, 이미지 URL, 링크 URL과 같은 정보가 아이템 리스트를 구성하고, Home Server에 맞는 Flex Template을 찾게 됩니다.
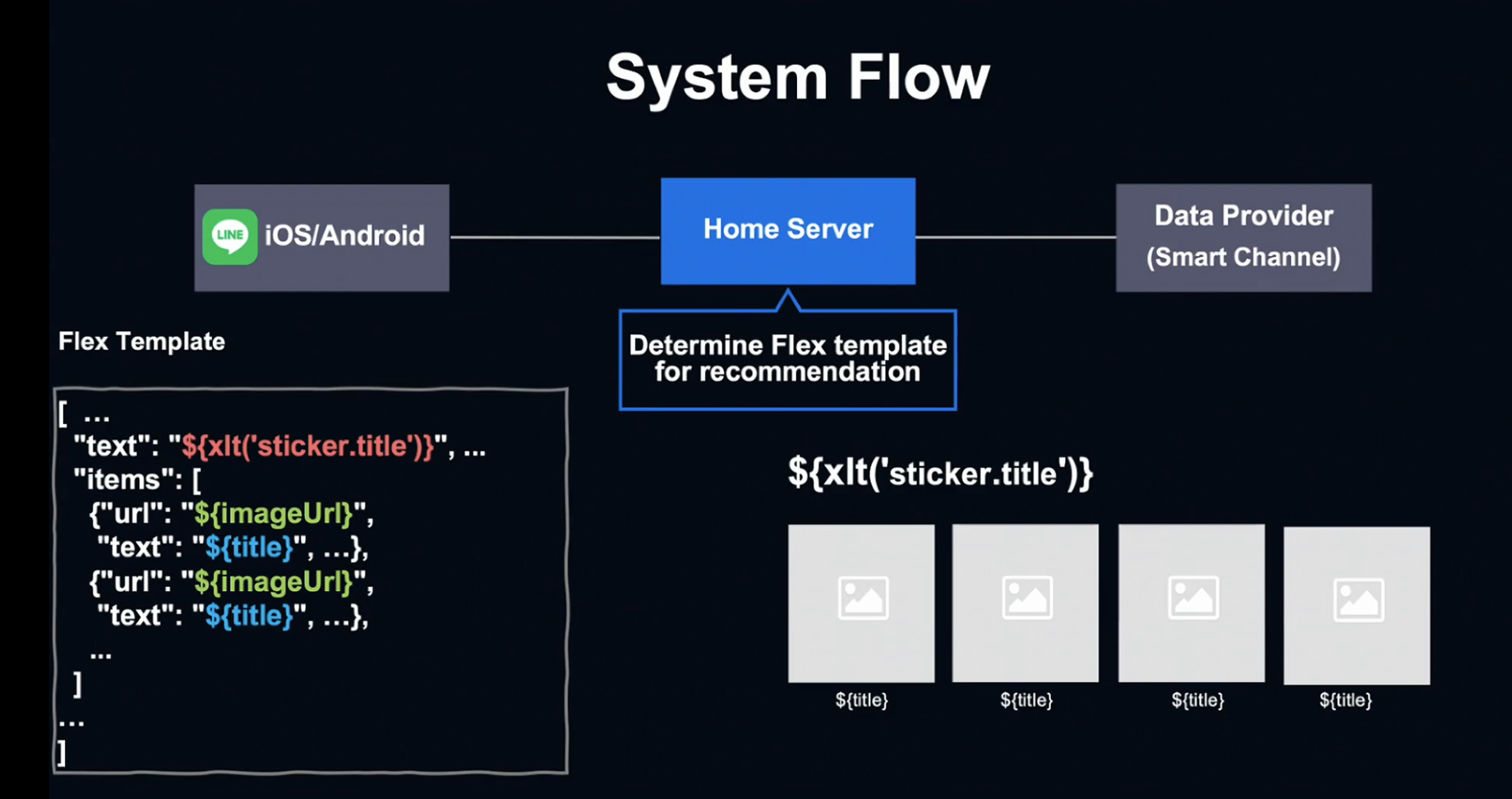
Flex template은 tag와 parameter가 포함된 placeholder가 있는, 빈 UI Template입니다.
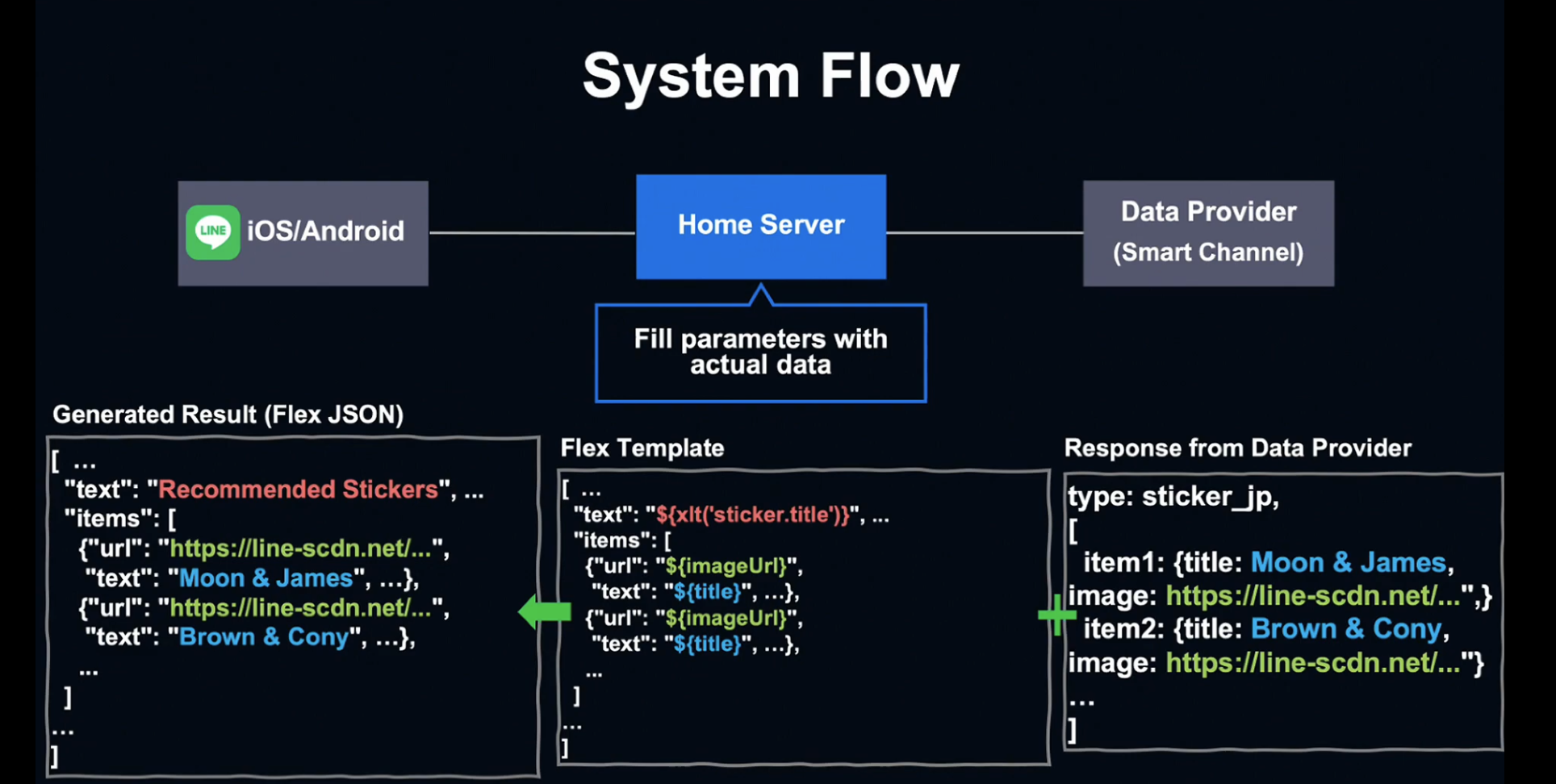
Flex Template이 Server Data와 결합되어 최종 Flex JSON을 생성합니다.
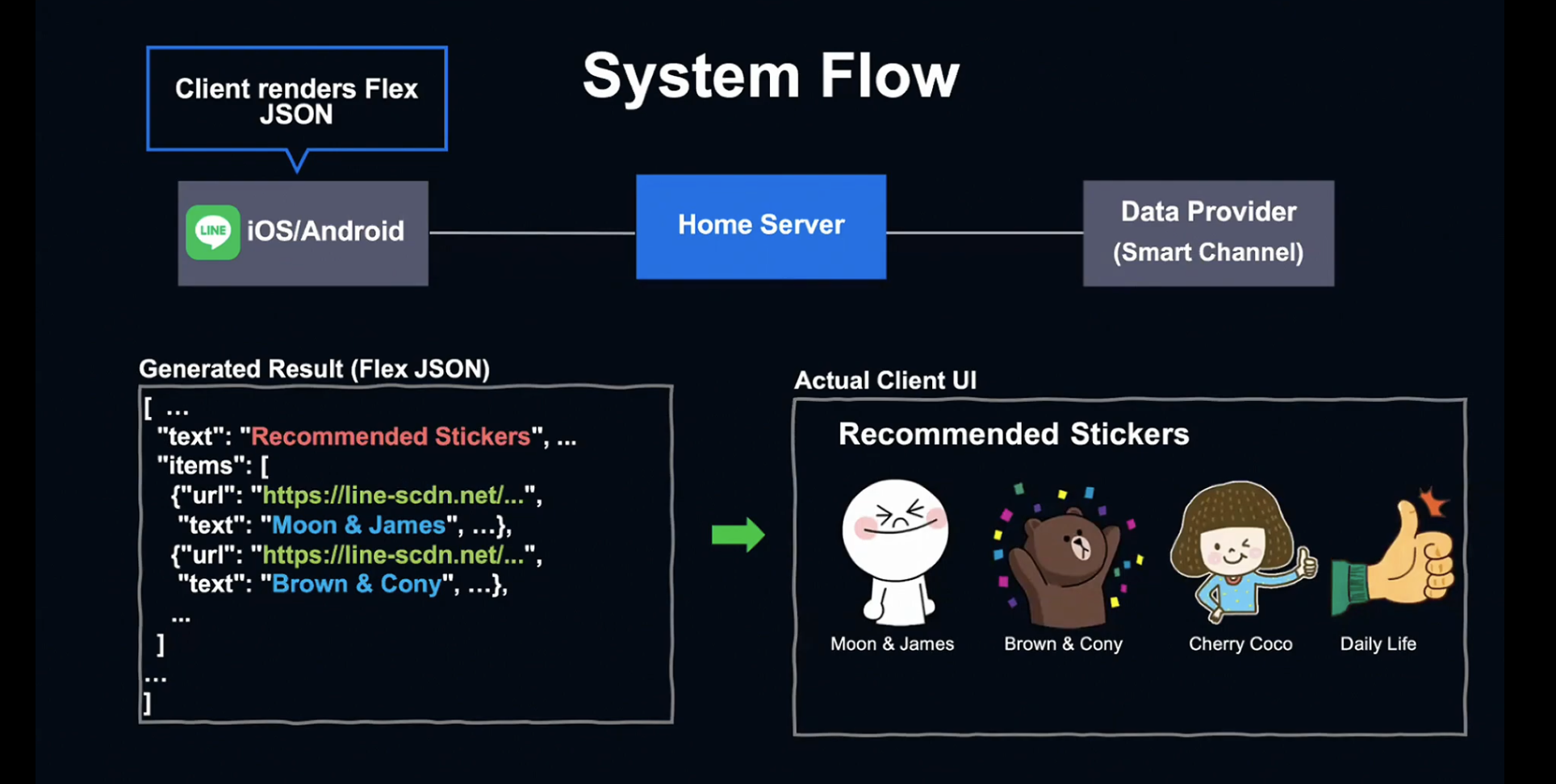
Client가 값을 수신하면 UI에 Rendering하고, 유저는 추천 컨텐츠를 볼 수 있게 됩니다.
Flex Template
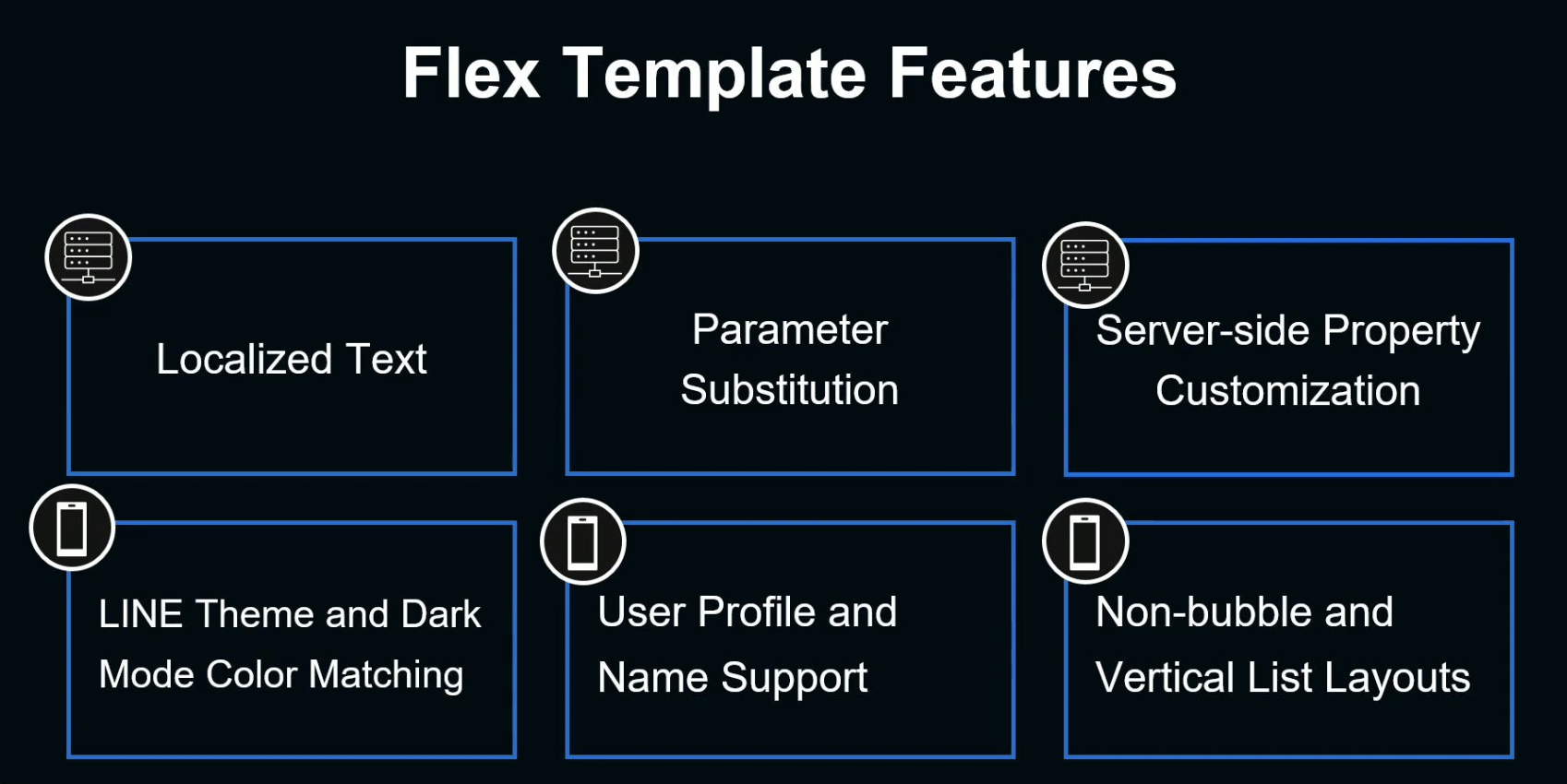
Flex template은 Flex Message를 Home Tab 추천에 적합하도록 변경한 것입니다.

Server 쪽의 변경 사항으로는 다국어 지원, Parameter substitution, 서버 맞춤화 등이 있고,
Client 쪽의 변경 사항으로는 LINE 테마 - 다크 모드간 색 통일, 유저 프로필 지원, 새로운 리스트 레이아웃 등이 있습니다.
Implementation Challenges


Home Tab은 56가지의 추천 컨텐츠, 초당 25,000개의 Request, 하루 5천만 개의 컨텐츠를 매일 유저에게 제공하고 있습니다.

그렇기 때문에 서버 트래픽이 높을 때, 유저가 데이터를 전달받지 못하는 상황에 대비해기 위해 부하 관리 전략을 만들었습니다.
예를 들어 일본 유저들은 재난재해 시 Home Tab에 동시에 다중적으로 접속할 수 있기 때문에, 높은 부하로 인해 각각의 유저가 Home Tab으로부터 추천 데이터를 응답받지 못할 가능성이 있습니다.
이런 상황을 방지하기 위해서 부하 관리 전략을 점진적으로 적용하는 것이 LINE의 목표입니다.

첫 번째 전략은 기한 관리입니다.
기한 관리란 다음 추천까지의 요청 간격을 서버가 통제하는 것입니다.
응답이 성공할 때, 서버는 기한 만료 Timestamp를 응답과 함께 저장하고, Client가 만료되었을 때 Timestamp에 따라 새로운 컨텐츠를 요청합니다.
기본 Expired Time은 한 시간이고, 서버 트래픽에 따라 Timestamp를 변경할 수 있습니다.
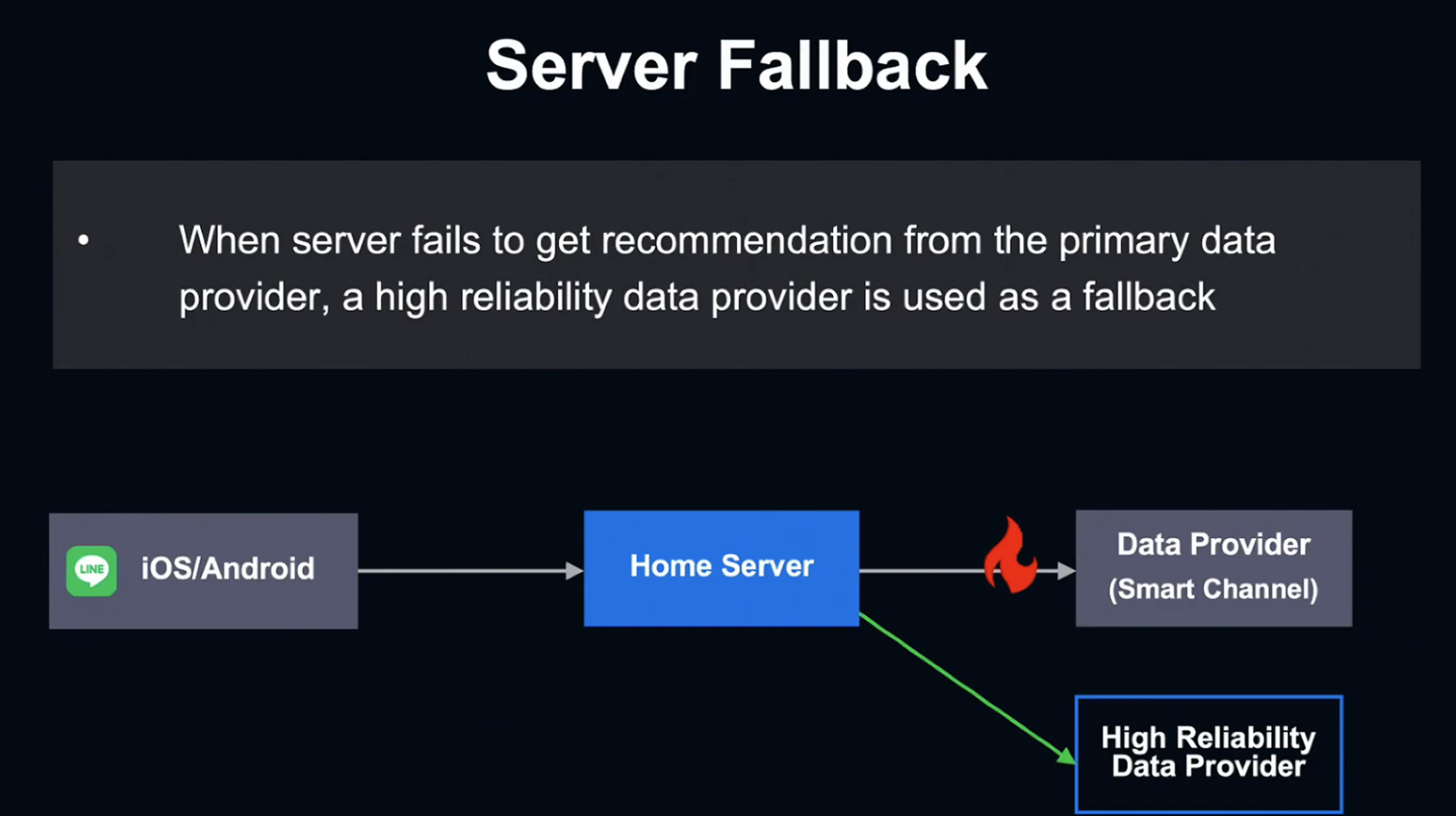
두 번째 전략은 Server Fallback입니다.
Server가 Data Provider와의 연결을 실패하거나 개인 데이터가 전혀 없는 유저를 맞닥뜨릴 때 신뢰성이 높은 데이터 프로바이더를 Fallback으로 사용하여 신뢰성을 보장합니다.
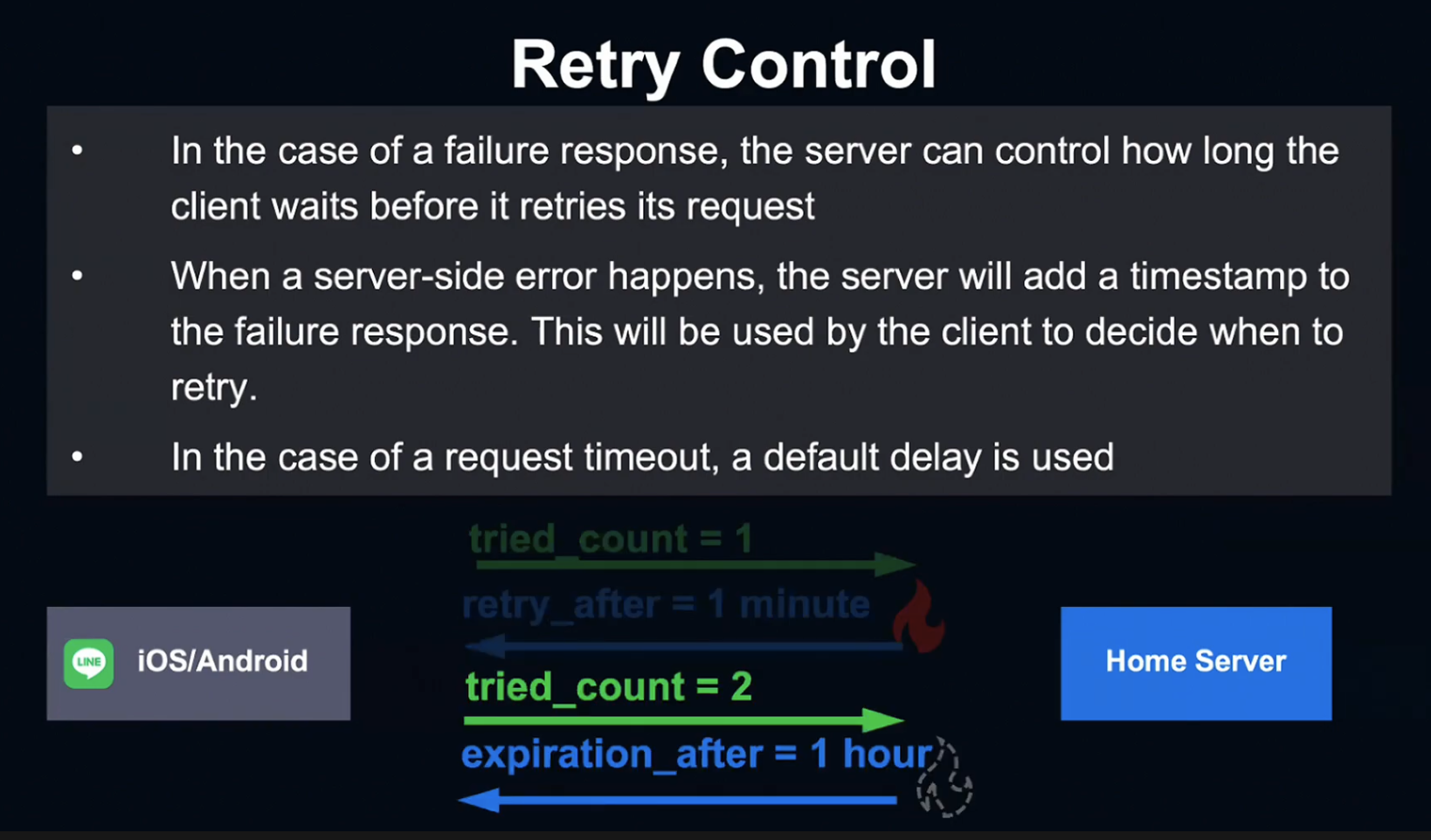
세 번째 전략은 Retry Control 전략입니다.
Server는 실패한 응답에 Timestamp를 추가하여 Client가 재시도 시 참고할 수 있도록 함으로서 Client의 응답 재시도 간격을 정할 수 있습니다.

마지막 전략은 Caching입니다.
Server는 Template Data를 위한 Local Cache를 사용하여 Database 요청에 소요되는 시간을 줄이고, 개인화 처리 시간을 단축시킵니다.
Use Cases

마지막으로 이 시스템을 사용한 Use Cases를 소개해 드리겠습니다.
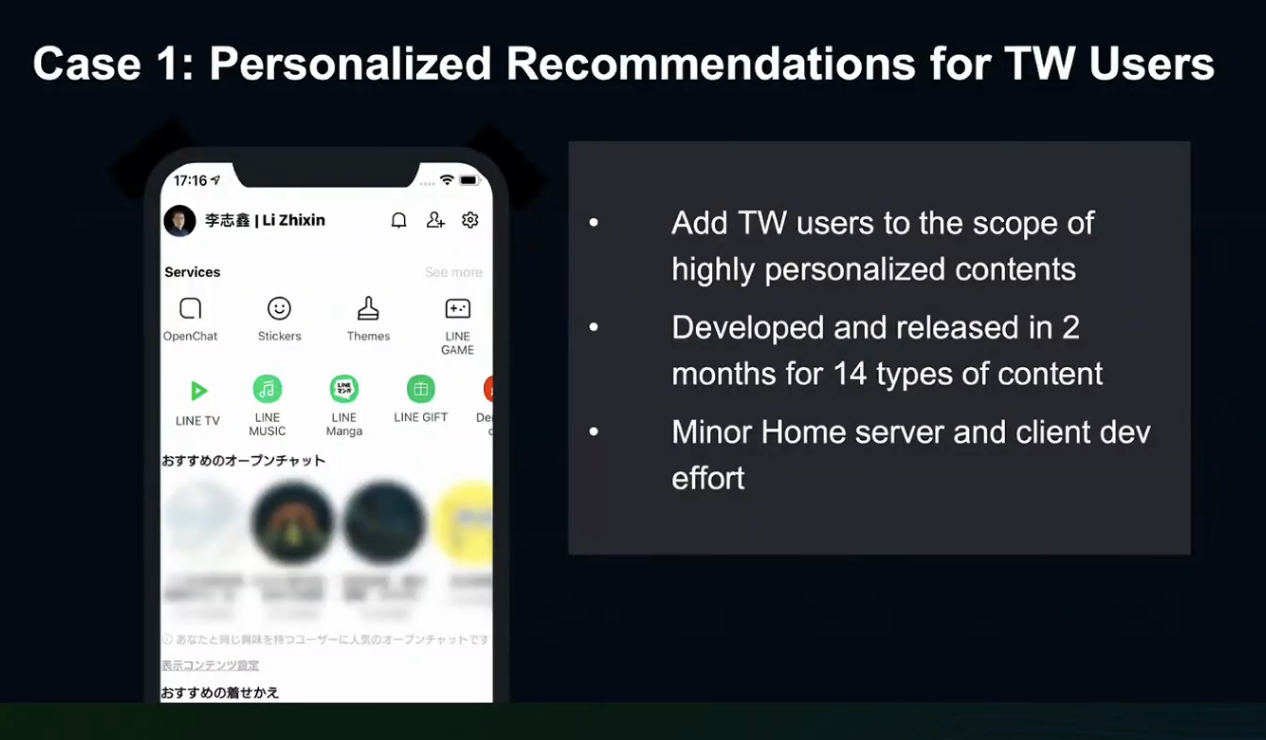
첫 번째 Case는 대만 유저를 위한 개인 맞춤 추천입니다.
이 기능은 올해 출시된 기능으로서, 2개월의 개발 기간 동안 15개 종류의 컨텐츠를 개발했고, Home Server와 Client의 공수를 최소화 했습니다.
UI Front에서는 훨씬 오랜 시간이 소요되었을 것으로 예상됩니다.

두 번째 Case는 캠페인 컨텐츠입니다.
연말연시에 모든 유저가 한시적으로 사용하는 컨텐츠에 Flex Template을 적용해, Data providor의 개발 공수를 0으로 줄이게 되었습니다.
마무리

미래에는 이 시스템을 사용하여 더 유용한 유저 추천 컨텐츠를 제작하는 것이 저희의 목표입니다.
오늘 세션을 시청해 주셔서 감사합니다.
후기
가볍게 정리만 해보려는 마음으로 시작했는데, 생각보다 시간이 많이 소요되어 실제 컨퍼런스 날짜보다 많이 밀리게 되었습니다.
각종 개발 컨퍼런스가 열릴 때마다 느끼지만, 공부 정말 열심히 해야겠다라는 생각이 저절로 들게 되네요.
DAY 2로 돌아오겠습니다. 감사합니다.
Reference
LINE DEVELOPER DAY 2021 - https://linedevday.linecorp.com/2021/ko/
LINE Messaging 플랫폼에서 Hbase와 Kafka 데이터 파이프라인 활용 사례 - https://www.youtube.com/watch?v=NANh-cpdMd0
LINT-HTT/2와 TLS를 통한 네트워크 현대화 - https://www.youtube.com/watch?v=rvdthweJYto&ab_channel=LINEDevelopers
LINE 앱을 위한 확장 가능한 멀티 데이터 센터 ID 제너레이터 - https://www.youtube.com/watch?v=Nj6z8NgKun0&ab_channel=LINEDevelopers
LINE 플랫폼 서버의 장애 대응 프로세스와 문화 - https://www.youtube.com/watch?v=YS35AGyq4aY&ab_channel=LINEDevelopers
TCP로 인한 대규모 Kafka 클러스터 요청 지연 문제 해결 사례 - https://www.youtube.com/watch?v=_2F_qdwfUas&ab_channel=LINEDevelopers
LINE Home Tab에 컨텐츠를 전달하기 위한 고범용성 시스템 - https://www.youtube.com/watch?v=LR1HyE8Zhco&ab_channel=LINEDevelopers
{kind=link}